问题描述
数据集样本不均衡。
例如,一个二分类任务,标签为 0 的数据占了 90%,标签为 1 的数据却只占 10%,用全部原始数据训练模型很可能导致模型带有一定的 ”偏见“,也可能会导致模型训练效率很慢。
使用 WeightedRandomSampler 均衡数据
PyTorch 官方文档:torch.utils.data.WeightedRandomSampler
以下即是 PyTorch 官方文档给出的说明:
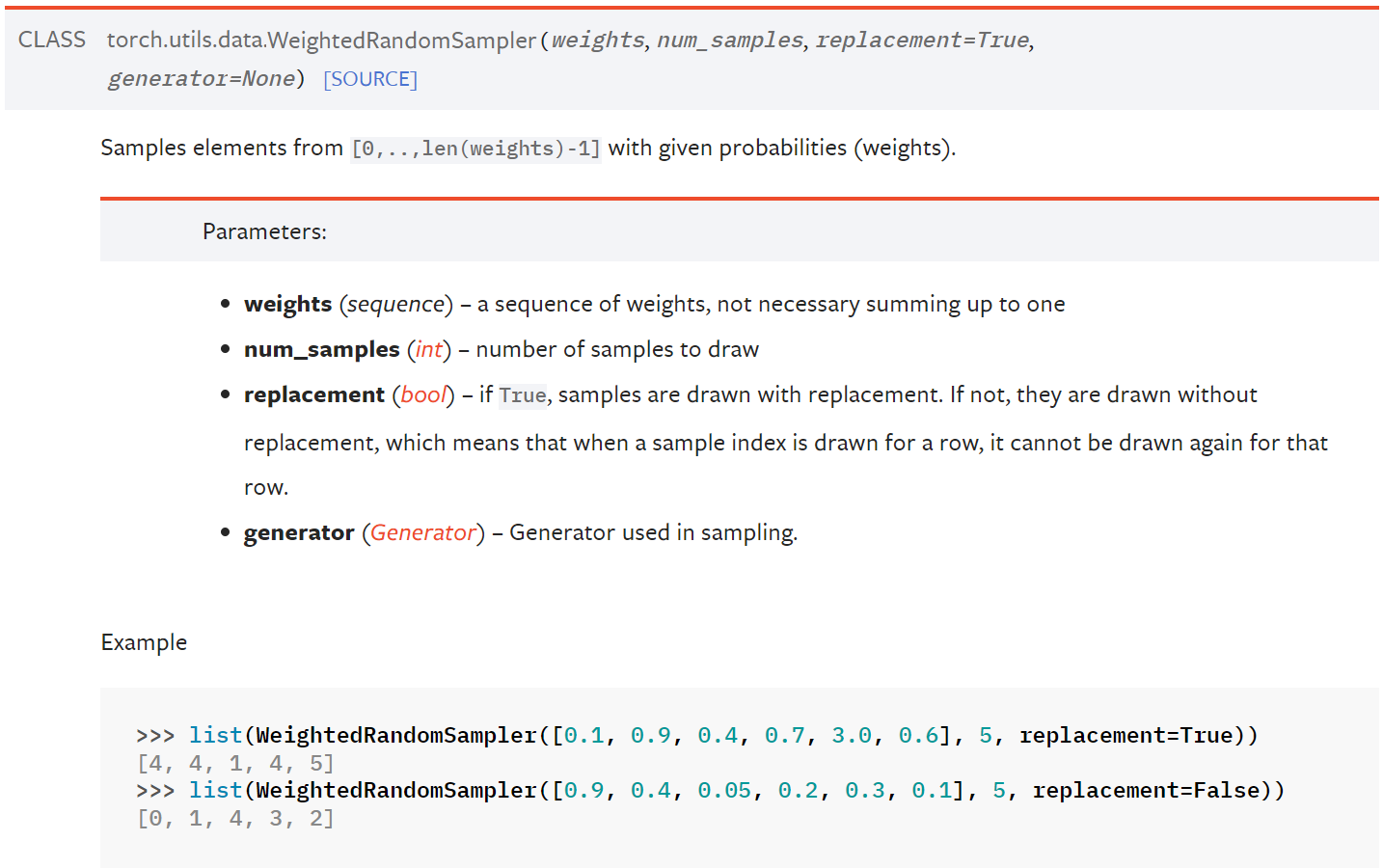
可以看到官方文档中给了代码示例:
>>> list(WeightedRandomSampler([0.1, 0.9, 0.4, 0.7, 3.0, 0.6], 5, replacement=True))
[4, 4, 1, 4, 5]
>>> list(WeightedRandomSampler([0.9, 0.4, 0.05, 0.2, 0.3, 0.1], 5, replacement=False))
[0, 1, 4, 3, 2]
结合这个示例解释一下各个参数:
- weights:用来采样的权重序列,并且并不要求这个序列的加和为 1。
比如第一个示例中的 [0.1, 0.9, 0.4, 0.7, 3.0, 0.6],就表示取第 0 个样本的权重(可以理解为概率,但不等同)为 0.1,取第 1 个样本的权重为 0.9,…,取第 4 个样本的权重为 3.0,…,很明显,取第 4 个样本的概率最大,然后是 第 1 个、第 3 个、第 5 个、第 2 个、第 0 个。 - num_samples:采样的数量。
比如示例中 num_samples 为 5,即采样数量为 5,最终输出的序列长度也为 5。 - replacement:是否可放回采样。
应用
以下是使用 WeightedRandomSampler 来解决数据集样本不均衡问题的代码。
from torch.utils.data import DataLoader, Dataset, WeightedRandomSampler
class MyDataset(Dataset):
def __init__(self, data):
self.data = data
def __getitem__(self, index):
return {
"text": self.data[index]["text"],
"label": self.data[index]["label"]
}
def __len__(self):
return len(self.data)
if __name__ == '__main__':
data = [
{
"text": "a", "label": 0}, {
"text": "b", "label": 0}, {
"text": "c", "label": 1}, {
"text": "d", "label": 0},
{
"text": "e", "label": 0}, {
"text": "f", "label": 0}, {
"text": "g", "label": 0}, {
"text": "h", "label": 0},
{
"text": "i", "label": 0}, {
"text": "j", "label": 0}, {
"text": "k", "label": 0}, {
"text": "l", "label": 1}
]
dataset = MyDataset(data)
label_list = []
for per_data in dataset:
label_list.append(per_data["label"])
print(f"label_list = {
label_list}")
weights = [1.0 / label_list.count(label) for label in label_list]
print(f"weights = {
weights}")
sampler = WeightedRandomSampler(weights, len(dataset), replacement=True)
train_loader = DataLoader(dataset, sampler=sampler, batch_size=4, shuffle=False, num_workers=0)
for data in train_loader:
print(data)
输出:
label_list = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1]
weights = [0.1, 0.1, 0.5, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.5]
{
'text': ['c', 'a', 'g', 'l'], 'label': tensor([1, 0, 0, 1])}
{
'text': ['e', 'j', 'l', 'k'], 'label': tensor([0, 0, 1, 0])}
{
'text': ['c', 'g', 'c', 'k'], 'label': tensor([1, 0, 1, 0])}
数据集有 12 条数据,其中包含 10 个标签为 0 的数据和 2 个标签为 1 的,可以说数据集是及不均衡了。
首先计算权重序列,标签为 0 的权重均为 1 / 10 = 0.1 1 / 10=0.1 1/10=0.1,标签为 1 的权重均为 1 / 2 = 0.5 1 / 2=0.5 1/2=0.5,把标签为 0 的权重全加起来的值和把标签为 1 的权重全加起来的值相等的,因此采样时随机取到标签为 0 和标签为 1 的概率是相等的,最终新的 dataloader 中基本上数据就均衡了,不过因为是随机采样,两种标签的数据量最终差一、两个也是可以理解的,总之是比原始数据集均衡了很多。