背景
在进行数据分析的时候,有时候会存在这样的情况:例如判断信用卡是否存在欺诈的行为,这样的问题就是一个二分类的问题,但是对于这样的问题,存在欺诈和正常的样本是存在有很大的差距的,可能欺诈的仅仅占有百分之一都不到;对于这样的样本不均衡的情况,一般情况下可以采用两种方式进行处理:过采样、下采样
下采样
对于这种方式,通常情况下就是将样本数量多的那一方的数据量调小,使和较小样本数量一样的数量(使样本数量同样少)
过采样
对于这种方式,通常情况下就是将样本数量少的那一方进行生成数据,使得样本数量少的那一方的数据能够和样本数量多的那一方一样多(使样本数量同样多)
样本数据处理
在进行数据分析的时候,首先我们需要对数据进行一个预处理,在机器学习中间,存在这样的一个误区,会认为在样本数据中间数据量比较大的数据的重要程度更高,数据量比较小的数据的重要程度更低;但是在我们定义数据样本的重要程度是一样的情况下,就需要对数据进行预处理了,在进行预处理的时候,通常情况下采用两种方式进行处理:归一化、标准化
归一化
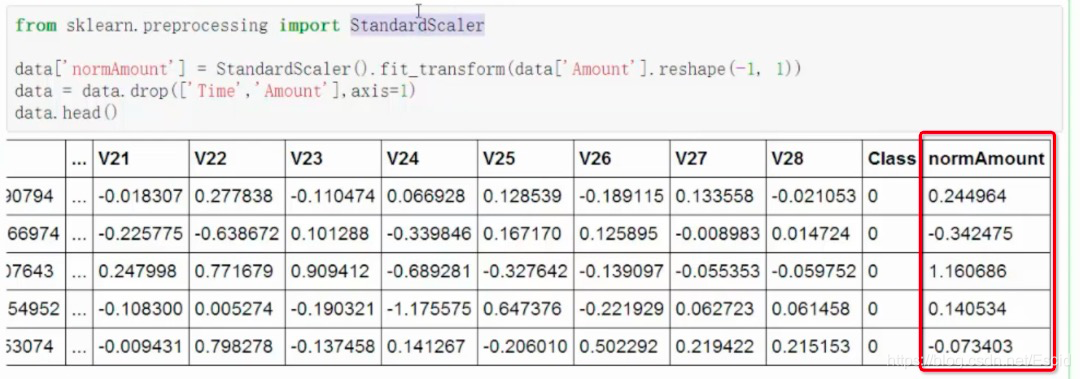
这里归一化使用到了sklearn,这里引入了sklearn中间预处理模块preprocessing中间的标准处理方法StandardScaler;这里需要注意的是reshape的使用,如果存在一个矩阵是2行3列的,如果使用.reshape(-1,1)表示将该矩阵改为了6行1列的数据,这里的-1表示让系统自动进行判断
后面将Time和Amount这两列进行删除,中间使用到的axis=1,表示的是将列进行删除
下采样
下采样的时候,需要去掉样本较多的那一方数据的时候,可以使用numpy中间的random.choice进行随机选择
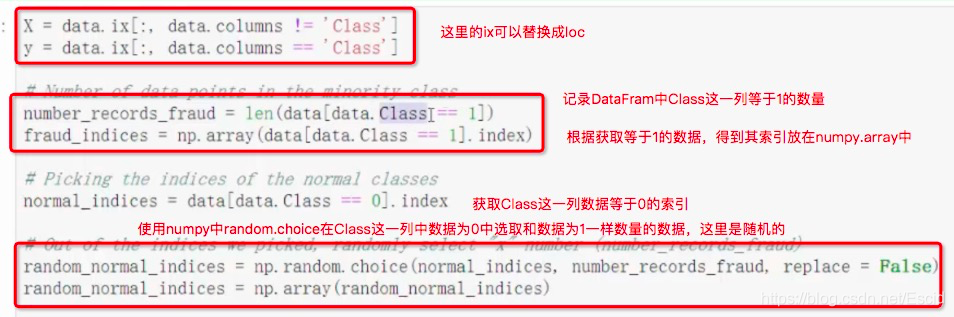
通过上面的方式,就能够找到Class为0和1的两类数据的索引了,下面就能够将这两类数据进行数据整合;这里使用到的是numpy中的concatenate方法

上面的under_sample_indices中间存放的就是数据为0和数据为1对应的索引值了,下面就需要将这些索引对应的内容进行获取

上面的under_sample_data中间就是对应的数据为0和数据为1的数据值了,之后需要进行分析的对象就是这个了,定义的自变量是非Class的这一列,定义的应变量是Class这一列
通过上面这一系列的过程,就是一个下采样的过程,可以看到,使用下采样的时候,对于提供的数据有很多是没有应用上的,这样会造成一个数据浪费,自然对最后的结果也是存在一定的影响的