目录
前言
最近在学习电力系统态势感知相关知识,也发表了一篇文章,下面想要深入学习该方面知识。态势感知基本要靠机器学习来完成。机器学习中可解释性是非常重要的部分。今天进行学习。
一、什么是可解释性
随着机器学习技术的不断进步,未来有望产生一个能够感知、学习、做出决策和采取独立行动自主系统。但是,如果这些系统无法向人类解释为何作出这样的决策,那么它们的有效性将会受到限制。用户要理解,信任和管理这些人工智能“合作伙伴”,可解释AI则至关重要。
二、可解释性的作用
1.模型改进
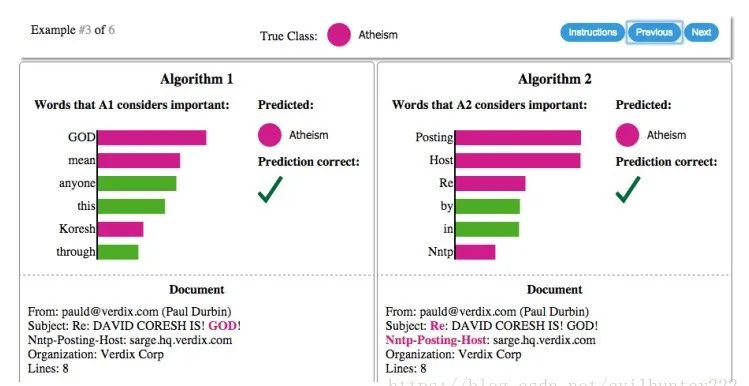
通过可解释分析,可以指导特征工程。一般我们会根据一些专业知识和经验来做特征,同构分析特征重要性,可以挖掘更多有用的特征,尤其是在交互特征方面。当原始特征众多时,可解释性分析将特别重要。在做机器学习任务时,我们一般会选择一个指标,比如准确率,然后尽可能优化。假设在一个文本分类任务中,判断文章是与“基督教”(Christianity)有关还是“无神论教”(Atheism)”,模型准确率,90%多,很高了。但是用LIME进行可解释分析发现,Posting(邮件标头的一部分)这个词重要性很高,但这个词汇与无神论本身并没有太多的联系,只是因为在无神论文章中出现的频次很高。这意味着尽管模型准确率很高,但所使用的原因是错误的。我们可以借此来改进模型,是否捕捉到了有意义的特征,以提高泛化性。
2.模型的可信和透明度
在我们做型的时候,需要在两个方面之间进行权衡,仅仅想要知道预测是什么,还是要知道模型为什么要给出这样的预测。在一些低风险的情况下,不一定要知道决策是如何做出的,比如推荐系统,广告、视频或者商品推荐等。但是在其他领域,比如在金融和医疗领域,模型的预测结果将会对相关的人产生巨大的影响,有时候我们依然需要专家对结果进行解释。解释为什么一个机器学习模型将某个患者的肿瘤归类为良性或恶性,解释为什么模型会拒绝一个人的贷款申请,这样,专家更有可能信任机器学习模型给出的预测结果。长久来看,更好地理解机器学习模型可以节省大量时间、防止收入损失。如果一个模型没有做出合理的决定,在应用这个模型并造成不良影响之前,我们就可以发现这一点。我们在面对客户的时候,他们会问 ”我为什么要相信你的模型“。如果客户不相信模型和预测结果,就无法使用这个模型,将其部署在产品中。
3. 识别和防止偏差
方差和偏差是机器学习中广泛讨论的话题。有偏差的模型经常由有偏见的事实导致,如果数据包含微妙的偏差,模型就会学习下来并认为拟合很好。一个有名的例子是,用机器学习模型来为囚犯建议定罪量刑,这显然反映了司法体系在种族不平等上的内在偏差。其他例子比如用于招聘的机器学习模型,揭示了在特定职位上的性别偏差,比如男性软件工程师和女性护士。机器学习模型在我们生活的各个层面上都是强有力的工具,而且它也会变得越来越流行。所以作为数据科学家和决策制定者来说,理解我们训练和发布的模型如何做出决策,让我们可以事先预防偏差的增大以及消除他们,是我们的责任。
三、论文实例
1. 论文原文
论文在介绍完整体模型后,提及了提高可解释性的方法。具体如下:




2. 进一步分析
见手写笔记部分:


四、深入研究
目前对于可解释性的理解只停留在了知道概念上,如果想要进一步学习,推荐链接:
原创 | 一文读懂模型的可解释性(附代码&链接) - 腾讯云开发者社区-腾讯云 (tencent.com)![]() https://cloud.tencent.com/developer/article/1629351此文章没有完全看懂,后面会进一步学习的。
https://cloud.tencent.com/developer/article/1629351此文章没有完全看懂,后面会进一步学习的。
总结
由于没有项目的练习,可解释性只是在论文中看到了,所以理解得非常浅显。后面如果有深入研究,会继续更新的。