背景
近几年,人工智能的可解释性问题受到了来自政府、工业界和学术界的广泛关注。美国国防部先进研究项目局DARPA资助了可解释性人工智能项目XAI(Explainable AI);中国国务院在《新一代人工智能规划》中提出的“实现具备高可解释性、强泛化能力的人工智能”目标,得到了各个公司的积极响应;ICML 2017年的最佳论文Understanding Black-Box Predictions via Influence Functions以及NIPS 2017的最佳论文A Linear-Time Kernel Goodness-of-Fit Test也和可解释性有着紧密关联。
NIPS 2017年时间检验奖(Test-of-Time Award)获得者Rahimi在发表获奖感言的时候表示,现在的机器学习已经越来越像炼金术了。其实如果只是简单应用炼金术的结果倒也无妨,可是将类似炼金术的机器学习结果用于社交媒体甚至大选是不够严谨和周密的,这也让他感到不安。
认知推理的任务中,我们想使模型学习到认知层面的信息;为了证明模型确实学习到了这种信息,将问题转换为使模型学习到人类能够直观理解的信息,即提供模型的可解释性Interpretability。

动机
- 深度神经网络DNN在多个领域中取得了很好的效果,但人们普遍对它们的黑匣子结构产生的结果不信任。
- 2016年,Angwin等分析了Correctional Offender Management Profiling for Alternative Sanctions (COMPAS),这是一个被广泛使用的刑事风险评估工具,发现其预测结果不可靠,且存在种族偏见。
- DNN容易遭受逃逸攻击,添加噪声会产生与真实类别无关的错误分类。
- 作为建立可解释机制的第一步,提出了Interpretability。Interpretability是指可以理解模型做了什么(或可能做了什么)。例如:在图像识别中寻找深度神经网络的视觉“焦点”;用代理方法简化复杂系统输出。然而,Interpretability还有很大的改进空间,因为识别主导分类器和简化问题空间并不能解决与理解不透明模型相关的所有可能问题。
- 可解释性Interpretability vs. 完备性Completeness
- 一个Explanation可以用两种方式来评估:Interpretability和Completeness。
- Interpretability的目标是用一种人类可以理解的方式来描述一个系统的内部结构。一个interpretable的模型必须提供对用户来说足够简单的、可用语言描述的解释。
- Completeness的目标是精确地描述一个系统的运行情况。当一个explanation能够让系统的行为在更多的情况下被预测到时,这个explanation就有更好的completeness。例如,在解释DNN时,如果可以解释系统中所有的数学运算和系数,就得到一个完全complete的explanation。
- 越好的completeness也就导致interpretability越差,需要取得平衡。
解释模型的方法分类
- 解释网络处理数据的过程:Explanations of Deep Network Processing
- Linear Proxy Models:在输入邻域上简化完整模型
- LIME
- 决策树:为神经网络用决策树的形式代理
- DeepRED、ANN-DT
自动规则抽取 - 分解方法:在神经元层面抽取if-then规则来模仿单元的行为
- KT、模糊规则
- 教学方法:直接把输入映射到输出空间,不考虑神经网络内部操作
- Validity Interval Analysis、sampling methods、RxREN
- MofN algorithm:通过聚类、忽略不重要的神经元来找到规则
- Salience Mapping:不断使用输入的一部分测试网络,找到真正影响网络输出的部分
- 深度网络中,显著性映射可以直接从输入的梯度计算
- LRP、DeepLIFT、CAM、GradCAM、Intergrated gradients、SmoothGrad
- DeepRED、ANN-DT
- Linear Proxy Models:在输入邻域上简化完整模型
- 解释网络中数据表示的信息:Explanations of Deep Network Representations
- 虽然网络中独立的高维运算很多,但是始终会用较少的子元素来表示。如ResNet中的瓶颈层。
- 数据的表示可以分为三种:
- By layer,所有经过一个layer的数据放在一起考虑
- By unit,每个神经元或filter channel单独考虑
- By vector,表示空间中的其他vector都单独考虑
- Role of Layers
- 我们可以通过测试layer在解决不同问题时的作用来了解layer。Razavian等人发现用ImageNet训练的图像分类器其中一层的输出可以直接用于其他更复杂的图像处理问题,包括更细粒度的分类,如鸟的种类、场景分类、特征检测、物品定位等。在每个任务中,用SVM等简单模型处理深层表示就可以超越SotA的表现,不用重新训练复杂的深度网络。利用这种深层网络中某一层的信息的方法叫做迁移学习。
- Role of Individual Units
- 一个layer中的信息可以进一步分为独立的神经元或卷积filter。每个unit的作用可以通过可视化能最大程度激活一个unit的输入模式来定性了解。可视化可以通过梯度下降、样本采样、训练生成式网络的方式来建立。还可以通过unit对完成任务的作用来定性分类。
- 网络剪枝也是理解unit作用的方式之一。用更少的单元来完成与大网络同样的任务更具有可解释性。
- Role of Representation Vectors
- Concept Activation Vectors (CAVs) 用户提供一组输入数据作为例子定义概念,学习用这些概念的线性组合来表示样本。
- 设计一个提供解释的系统,对模型自己的行为提供简化的解释:Explanation-Producing Systems
- 现有的一些方法使模型在设计上就更容易解释,包括:
- 用显式attention作为架构的一部分;
- 使模型学习disentangled representations;
- 使模型能产生generative explanations。
- Attention Networks
- 基于注意力的模型可以学习输入或内部特征的权重来控制网络其他部分获取的信息。已经在NLP、图像分类、可视化问答等任务中卓有成效。虽然注意力单元不以人类可理解的解释为训练目标,但是它直接将信息传递的映射关系表示出来,也可以作为一种解释。
- Attention可以视为一种抽取解释的方法,还有一种应用方法是显式训练attention,使网络的表现符合预期的解释(将错误的解释作为先验,使模型学习更好的解释)。
- Disentangled Representations
- 分离的表示要求不同维度有着相互独立的含义。传统方法包括PCA、ICA、NMF等。
- 深度网络可以直接学习分离表示,例如VAE。
- InfoGAN以隐变量的分离程度为目标训练生成式网络。
- Generated Explanations
- 深度网络可以直接把生成可解释作为网络的一部分来训练。已被应用于视觉问答、细粒度图像分类。
- 现有的一些方法使模型在设计上就更容易解释,包括:
总结

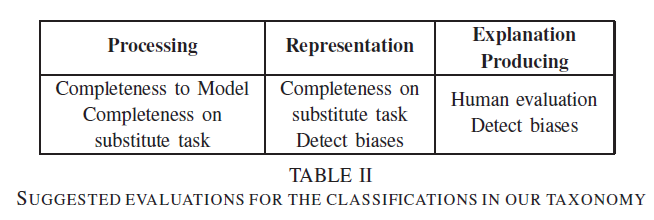
Completeness: 跟原始模型/其他任务的性能进行比较
Detect biases: 测试模型对特定输入(存在特定模式)的敏感度,看是否存在相关/不相关的偏向(依赖/无视特定模式)
Interpretability和completeness存在tradeoff