problem definition:(用于肿瘤学多模式数据集成的人工智能)
多实例学习
MIL 是一种弱监督学习,其中输入的多个实例没有单独标记,并且监督信号仅适用于通常称为包的一组实例(Carbonneau 等人,2018 年;Cheplygina等人, 2019 ) 如果袋子中至少有一个阳性实例,则袋子的标签被假定为阳性。该模型的目标是预测袋子标签。MIL 模型包括三个主要模块:特征学习或提取、聚合和预测。第一个模块用于将图像或其他高维数据嵌入到低维嵌入中,该模块可以动态训练(Campanella 等人,2019 年)) 或来自监督或自监督学习的预训练编码器可用于减少训练时间和数据效率 ( Lu et al., 2021 )。实例级嵌入被聚合以创建患者级表示,作为最终分类模块的输入。一种常用的聚合策略是基于注意力的池化(Ilse 等人,2018 年),其中使用两个完全连接的网络来学习每个实例的相对重要性(Ilse 等人,2018 年)。由相应的注意力分数加权的补丁级别的表示被总结以构建患者级别的表示。注意力分数也可用于理解模型的预测基础(参见“多模态可解释性””了解更多详情)。在大规模医学数据集中,精细注释通常不可用,这使得 MIL 成为训练深度模型的理想方法,最近在癌症病理学中有几个例子(Campanella 等人,2019 年,Lu 等人,2021 年, Lu等人, 2021 年)和基因组学(Sidhom 等人,2021 年)
Vision transformers
位置编码和多个自注意力头允许合并空间信息,增加上下文和鲁棒性(李等,2022;Shamshad 等人,2022 年)的 VIT 方法优于其他方法
多模态数据融合
多模态数据融合的目的是提取和组合不同模态的互补上下文信息,以做出更好的决策(Zitnik 等人,2019 年)。这在医学上尤为重要,其中一种模式的相似发现可能与其他模式相结合有不同的解释(Iv 等人,2021 年)。例如,单独的IDH1突变状态或组织学特征不足以解释患者结果的差异,而两者的结合最近已被用于重新定义弥漫性神经胶质瘤的 WHO 分类(Louis 等人,2016 年)). 人工智能提供了一种自动化和客观的方式来整合来自不同数据的补充信息和临床背景,以改进预测。多模态数据驱动的 AI 模型还可以利用模态中的互补和补充信息;如果单峰数据有噪声或不完整,补充来自其他模态的冗余信息可以提高预测的稳健性和准确性。AI驱动的数据融合策略(Baltrušaitis et al., 2018)可分为早期、晚期和中期.
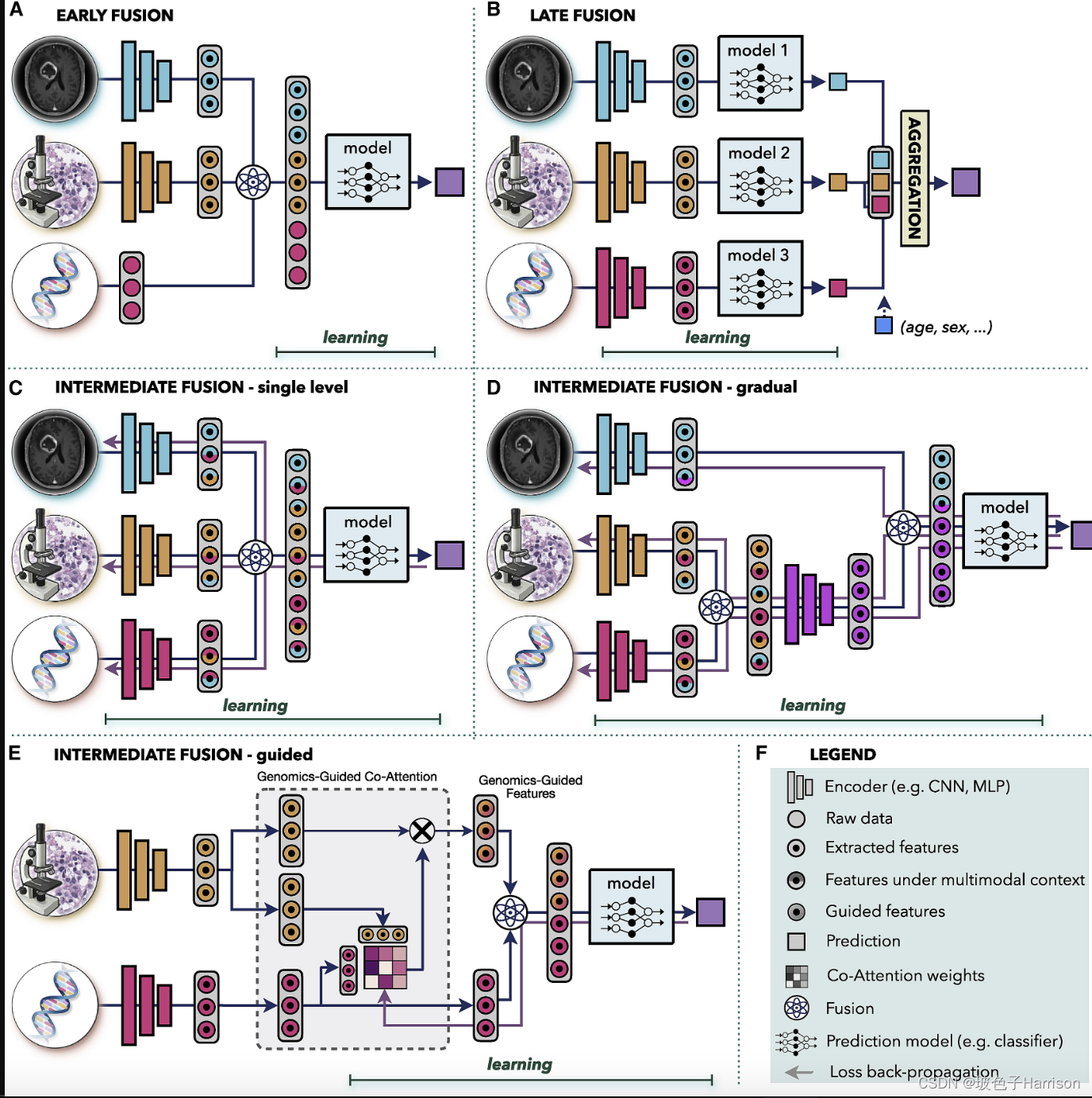
- (A) Early fusion 在将其提供给模型之前,在输入级别从原始数据或特征构建联合表示。
- (B) 后期融合为每个模态训练一个单独的模型,并在决策级别聚合来自各个模型的预测。
- (C-E) 在中间融合中,预测损失被传播回每个模态的特征提取层,以迭代地学习多模态上下文下改进的特征表示。单峰数据可以融合(C)在一个单一的水平或(D)逐渐在不同的层。
- (E) 引导融合允许模型使用来自一种模态的信息来指导从另一种模态提取特征。
早期融合
早期融合在输入到单个模型之前整合来自输入级别的所有模式的信息。模态可以表示为原始数据、手工制作或深层特征。联合表示是通过向量连接、逐元素求和、逐元素乘法(Hadamard 乘积)或双线性池化(Kronecker 积)等操作构建的(Huang 等人,2020 年;Ramachandram 和 Taylor,2017年)). 在早期融合中,只训练一个模型,简化了设计过程。然而,假设单一模型非常适合所有模式。早期融合需要模态之间一定程度的对齐或同步。虽然这在其他领域更为明显,例如语音识别中音频和视觉信号的同步,但它在临床环境中也很重要。如果模式来自显着不同的时间点,例如干预前和干预后,那么早期融合可能不是一个合适的选择。
后期融合
后期融合,也称为决策级融合,为每个模态训练一个单独的模型,并聚合来自各个模型的预测以进行最终预测。聚合可以通过平均、多数表决、基于贝叶斯的规则(Ramanathan 等人,2022 年)或学习模型(例如MLP)来执行. Late Fusion允许对每个模态使用不同的模型架构,并且不对数据同步造成任何限制,使其适用于具有大数据异构性或来自不同时间点的模态的系统。在数据丢失或不完整的情况下,后期融合保留了做出预测的能力,因为每个模型都是单独训练的,并且即使缺少模态也可以应用多数表决等聚合。同样,可以在不需要重新训练完整模型的情况下执行新模态的包含。简单的协变量,如年龄或性别,由于其简单性,通常通过后期融合包含在内(参见图 3B). 如果单峰数据不相互补充或没有很强的相互依赖性,则后期融合可能更可取,因为与其他融合策略相比,它具有更简单的体系结构和更少的参数。这在数据有限的情况下也很有用。此外,来自各个模型的误差往往是不相关的,从而导致后期融合预测中的偏差和方差可能较低。在不同模态的信息密度差异很大的情况下,共享表示的预测可能会受到最主要模态的严重影响。在后期融合中,可以通过在聚合步骤中为每个模态设置相等或不同的权重,以受控方式说明每个模态的贡献。
中间融合
这是一种策略,其中多模态模型的损失传播回每个模态的特征提取层,以迭代地改进多模态上下文下的特征表示。相比之下,在早期和晚期融合中,单峰嵌入不受多峰信息的影响。中间融合可以在不同的抽象层次上组合单独的模态。此外,在具有三种或更多模态的系统中,数据可以一次性全部融合(图 3 C)或逐渐跨越不同层次(图 3D). 中间单层融合类似于早期融合;然而,在早期融合中,单峰嵌入不受多峰上下文的影响。渐进融合允许将来自同一级别的高度相关通道的数据组合起来,迫使模型考虑特定模态之间的交叉相关性,然后在后面的层中与不太相关的数据融合。例如,在图 3D中,首先融合基因组学和组织学数据,以解释突变和组织形态学变化之间的相互作用,而在后一层考虑与宏观放射学数据的关系。在某些应用程序中,渐进融合显示出比单级融合更高的性能(Joze 等人,2020 年;Karpathy 等人,2014 年)). 最后,引导融合允许模型使用来自一种模态的信息来指导从另一种模态提取特征。例如,在图 2 E 中,基因组学信息指导组织学特征的选择。动机是不同的组织区域可能与特定突变的存在相关。引导融合学习反映特定分子信息存在下不同组织学特征相关性的共同注意分数。共同注意分数是通过多模态模型学习的,其中基因组学特征和相应的基因组学指导的组织学特征相结合,用于最终模型预测。
多模式可解释性
可解释性和模型自省是人工智能开发、部署和验证的重要组成部分。凭借 AI 模型学习抽象特征表示的能力,人们担心这些模型可能会使用虚假的捷径进行预测,而不是学习临床相关方面。当出现新数据或歧视某些人群时,此类模型可能无法概括(Banerjee 等人,2021 年;Chen 等人,2021a)。另一方面,这些模型可以发现新的和临床相关的见解。在这里,我们简要概述了用于肿瘤学模型自省的不同方法,更多技术细节可以在最近的评论中找到(Arrieta 等人,2020 年)). 值得指出的是,这些方法允许我们在做出预测性决定时反思模型认为重要的数据部分,但特征表示本身仍然是抽象的。

- (A 和 B)组织学:训练 MIL 模型以对WSI 中的肾细胞癌亚型进行分类,同时训练 CNN 以在图像块中执行相同的任务。(A) 具有最低和最高注意力分数的注意力热图和补丁。(B) 每个类的 GradCAM 属性。
- (C 和 E)集成梯度属性可用于分析 (C) 基因组学或 (E) EMR。归因大小对应于每个特征的重要性,方向表示特征对低(左)与高(右)风险的影响。颜色指定输入特征的值:拷贝数增加和突变的存在以红色显示,而蓝色用于拷贝数丢失和野生型状态。(E) 注意力分数可以用来分析医学文本中单词的重要性。
- (D 和 F) 放射学:训练 MIL 模型以使用轴向幻灯片作为个体实例来预测 MRI 扫描的存活率。(D) 注意力热图映射到具有最高和最低注意力的 3D MRI 扫描和幻灯片。(F) GradCAM 用于在每个 MRI 幻灯片中获得像素级可解释性。3D 像素级可解释性是通过根据相应幻灯片的注意力分数对幻灯片级别的 GradCAM 映射进行加权来计算的。
组织病理学
在组织病理学中,VIT 或 MIL 可以揭示每个图像块对模型预测的相对重要性。根据模型架构,注意力或概率分数可以映射以获得幻灯片级别的注意力热图,如图A所示,其中训练 MIL 模型以对 WSI 中的癌症亚型进行分类。尽管没有使用手动注释,但该模型学会了识别每种癌症类型的特定形态,并区分正常组织和恶性组织。类激活方法 (CAM),例如 GradCAM ( Selvaraju et al., 2017 ) 或 GradCAM++ ( Chattopadhay et al., 2018)),允许人们通过计算输入的变化如何影响每个预测类别的模型输出来确定模型输入(例如,像素)的重要性。GradCAM 通常与引导反向传播方法结合使用,即所谓的引导 GradCAM(Selvaraju 等人,2016 年),其中引导反向传播确定 GradCAM 指定的预测区域内的像素级重要性。图B 中进行了说明,其中训练了 CNN 以对图像块中的癌症亚型进行分类。为了比较,在注意力方法中,每个实例的重要性在训练期间确定,而基于 CAM 的方法是模型不可知的,即独立于模型训练。
分子数据
分子数据可以通过积分梯度法进行分析(Sundararajan et al., 2017),它计算属性值,指示特定输入的变化如何影响模型输出。对于回归任务,如生存分析,属性值可以反映重要性的大小以及影响的方向:具有正属性的特征增加预测输出(即更高的风险),而具有负属性的特征减少预测值(即降低风险)。在患者层面,这被可视化为条形图,其中 y 轴对应于特定特征(按其绝对属性值排序),x 轴显示相应的属性值。在总体水平上,归因图描述了所有受试者的归因分数分布。图 4C 显示了用于神经胶质瘤患者生存预测的最重要基因组学特征的归因图(Chen 等人,2021c )。其他表格数据,例如手工制作的特征或从EMR获得的值,可以用相同的方式解释。EMR 也可以通过自然语言处理(NLP) 方法进行分析,例如转换器,其中注意力分数决定文本中特定单词的重要性(图 E)。
多模态模型
在多模态模型中,属性图还可以确定每种模态对模型预测的贡献。前面提到的所有方法都可以用于多模态模型,以探索每种模态的可解释性。此外,可以研究单峰和多峰设置下特征重要性的变化,以分析多峰环境的影响。
可解释性方法通常没有任何准确性措施,因此不要过度解释它们很重要。虽然基于 CAM 或注意力的方法可以定位预测区域,但它们无法指定哪些特征是相关的,即它们可以解释位置但不能解释原因。此外,不能保证所有高关注/归因区域都具有临床相关性。高分仅表示该模型认为这些区域比其他区域更重要。
多式联运数据互联
多模式数据互连的目的是揭示跨模式的关联和共享信息。这种关联可以提供对癌症生物学的新见解,并指导新生物标志物的发现。尽管有许多数据探索方法,但我们在此说明几个可能的方向
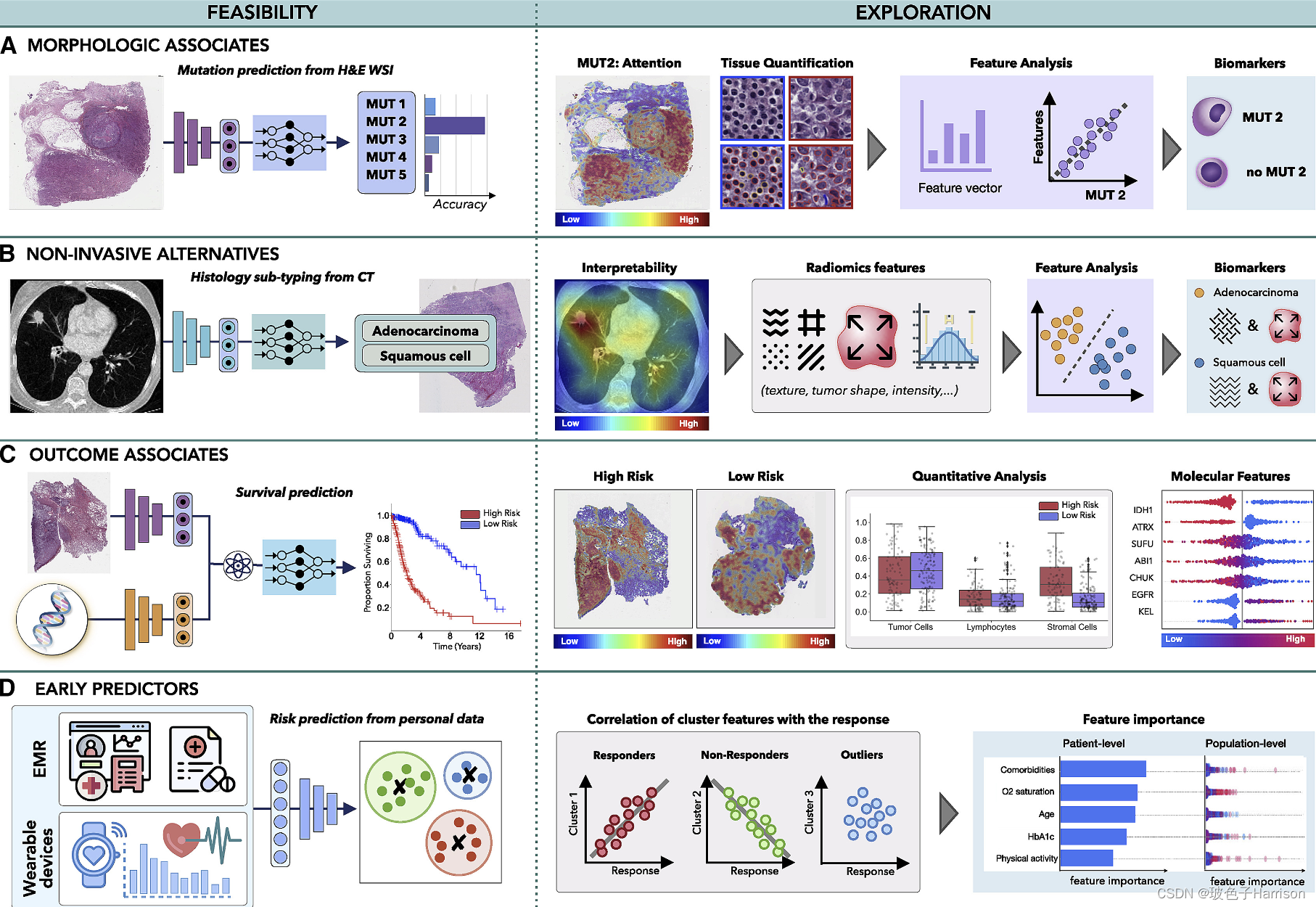
- (A 和 B)AI 可以识别跨模态的关联,例如(A)从组织学或放射学图像推断某些突变的可行性或(B)非侵入性和侵入性模态之间的关系,例如从放射组学预测组织学亚型特征。
- (C) 这些模型可以揭示临床数据和患者结果之间的关联,有助于发现模式内部和模式之间的预测特征。
- (D) 可以分析通过 EMR 或可穿戴设备获取的信息,以确定与癌症发作相关的风险因素或揭示与治疗反应或耐药性相关的模式,以支持早期干预。
形态关联
恶性变化通常会在不同尺度上传播;致癌突变会影响细胞行为,进而重塑组织形态或组织学图像中可见的肿瘤微环境。因此,微观变化可能对PET或 MRI 扫描可检测到的肿瘤代谢活动和宏观外观产生影响。Coudray 等人首先证明了人工智能方法识别跨模态关联的可行性。( Coudray 等人,2018 年),他们表明肺癌中的某些突变可以直接从苏木精和伊红(H&E) 染色的 WSI 中推断出来。其他研究紧随其后,预测肝脏中 WSI 的突变状态(Chen 等人,2020a)、膀胱癌(Loeffler 等人,2021 年)、结直肠癌( Jang 等人,2020 年)和甲状腺癌(Tsou 和 Wu,2019 年),以及尝试进行泛癌泛突变研究预测任何肿瘤类型的任何遗传改变( Fu 等人,2020 年; Kather 等人,2020 年)。其他分子生物标志物,例如基因表达( Anand 等人,2020 年; Binder 等人,2021 年; Schmauch 等人,2020 年)、激素受体状态( Naik 等人,2020 年)、肿瘤突变负荷( Jain 和马苏德,2020 年)和微卫星不稳定性(Cao 等人,2020 年; Echle 等人,2020 年)也已从 WSI 中推断出来( Murchan 等人,2021 年)。在放射学方面,AI 模型已经预测了术前脑部 MRI扫描中的IDH突变和1p/19q共缺失状态(Bangalore Yogananda 等人,2020 年; Yogananda 等人,2020 年)以及乳房X 线照相术中的BRCA1和BRCA2突变状态(Ha 等人) al., 2017 ) 和 MRI ( Vasileiou et al., 2020 ) 扫描,而EGFR和KRAS肺癌 ( Wang et al., 2019 ) 和结直肠癌 ( He et al., 2020 )的CT 扫描已检测到突变。
通过发现跨模态的形态关联的存在,AI 模型可以增强探索性研究并减少可能的候选生物标志物的搜索空间。例如,在图 5中A,AI 已经揭示,可以从 WSI 中可靠地推断出所研究的突变之一。尽管模型使用的预测特征可能是未知的,但可解释性方法可以提供额外的见解。注意热图可以揭示与预测特定突变相关的组织区域。可以识别具有高和低注意力分数的区域中不同的组织结构和细胞类型,并且可以进一步提取和分析它们的属性,例如细胞核形状或体积。可以部署聚类或降维方法来检查有希望的特征,可能揭示突变状态与不同形态特征之间的关联。
结果关联
个性化医疗的好处通常受到缺乏能够解释患者结果二分法的生物标志物的限制。另一方面,AI 模型在预测临床结果方面表现出色,例如生存率 ( Lai et al., 2020 )、治疗反应 ( Echle et al., 2020 )、复发 ( Yamamoto et al., 2019 ) 和辐射毒性( Men et al., 2019 ),使用单峰和多峰 ( Chen et al., 2020b , 2021c ; Joo et al., 2021 ; Mobadersany et al., 2018) 数据。这些工作意味着 AI 模型在数据中发现相关预后模式的可行性,这可以通过可解释性方法来阐明。例如,在图 5中C,训练模型以根据组织学和基因组学数据预测存活率。注意力热图揭示了与低风险和高风险患者群体相关的组织区域,而分子概况则通过归因图进行分析。可以通过检查组织形态、细胞亚型或其他人类可解释的数据特征来进一步分析预测组织区域。肿瘤浸润淋巴细胞可以通过肿瘤和免疫细胞的共定位来估计,以指定免疫热和冷肿瘤。可以探索特定模态的归因以及单模态与多模态数据中特征重要性的变化,以确定多模态语境化的影响。
这些探索性研究已经提供了新的临床见解。例如,Geessink 等人。( Geessink et al., 2019 ) 表明肿瘤与间质的比值可以作为直肠癌的独立预后指标,而肿瘤面积与转移淋巴结区域的比值在胃癌中具有预后价值( Wang et al., 2021 年)。其他形态学特征,例如乳腺组织学中胶原纤维的排列 ( Li et al., 2021 ) 或结直肠组织中的空间组织组织 ( Qi et al., 2021 ),已被确定为侵袭性或复发的可能生物标志物。
早期预测因子
人工智能还可以探索在患者诊断之前获取的各种数据,以确定潜在的预测风险因素。EMR 提供有关患者病史、用药、过敏或免疫接种的丰富信息,这些信息可能有助于患者的治疗结果。AI 模型可以有效地分析这些多样化的数据,以搜索不同的患者亚组(图 5 D)。确定的亚组可以与不同的患者结果相关联,而归因图可以确定不同因素在患者和人群水平上的相关性。最近,普拉西多等人。( Placido et al., 2021 ) 展示了人工智能识别胰腺癌高危患者的可行性通过探索EMR。同样,EMR 用于预测治疗反应 ( Chu et al., 2020 ) 或住院时间 ( Alsinglawi et al., 2022 )。已确定的新预测风险因素可以支持大规模人群筛查和早期预防保健。
在医院环境之外,智能手机和可穿戴设备为实时和持续的患者监测提供了另一个绝佳机会。测量值的变化,例如患者步数的减少,已被证明是临床结果较差和住院风险增加的有力预测指标(Low,2020 年)). 此外,现代可穿戴设备不断扩展其功能,包括测量温度、压力水平或血氧饱和度或心电图。这些测量值可以与临床数据一起进行分析,以寻找表明毒性或治疗抵抗力增加的早期阶段的风险因素,以便在治疗过程中进行个性化干预。个性化监测和纳米技术的研究正在研究新的方向,例如检测患者汗液测量值(Xu 等人,2019 年)或监测服药依从性和药物吸收的可摄入传感器(Weeks 等人,2018 年)). 所有这些新颖的设备都提供了对患者状态的有用见解,可以通过 AI 模型在更大的临床环境中对其进行分析。
类似模式的对齐
这种方法通常涉及同一系统的不同成像模式。这通常是通过图像配准来实现的,它被表述为一个优化问题,最小化模态之间的差异。
在放射学中,刚性解剖结构可以指导数据对齐。例如,MRI 和 PET大脑扫描的配准通常可以高精度实现,即使是简单的仿射配准,这要归功于坚硬的头骨。如果存在运动和变形,情况会更加复杂,例如肺部成像中的呼吸或扫描期间身体姿势的变化。此类数据的对齐通常需要使用自然或手动放置的地标进行可变形配准以进行指导。一个特别具有挑战性的情况是干预之间的扫描配准,例如,术前和术后扫描的配准,由于肿瘤切除、对治疗的反应或组织压缩,它表现出许多不平凡的变化(哈斯金斯等人,2020 年)。
在组织学中,每张染色载玻片通常来自不同的组织切片。即使在连续的组织切割中,由于组织微环境的变化或组织折叠、撕裂或切割等伪影,组织外观也存在显着差异 ( Taqi et al., 2018 ),这些都会使数据对齐变得复杂。组织学图像的稳健和自动配准可能具有挑战性(Borovec 等人,2020 年),因此许多研究采用非算法策略,例如组织载玻片的清除和重新染色(Hinton 等人,2019 年)。一个新出现的方向是不锈钢成像,包括紫外线显微镜等方法(Fereidouni 等人,2017 年))、受激拉曼组织学 ( Hollon et al., 2020 ) 或比色成像 ( Balaur et al., 2021 )。
多种模式的对齐
这是指来自不同尺度、时间点或测量的数据的集成。通常获取一种模态会导致样本损坏,从而阻止从同一系统收集多个测量值。例如,大多数组学测量需要组织解体,这不可避免地影响研究细胞外观与相应基因表达之间关系的可能性。在这里,跨模态自动编码器可用于实现任意模态之间的集成和转换。跨模态自动编码器 ( Dai Yang et al., 2021) 为每个模态构建一对编码器-解码器网络,其中编码器将每个模态映射到低维潜在空间,而解码器将其映射回原始空间。判别目标函数用于匹配公共潜在空间中的不同模态。有了共享的潜在空间,就可以将一种模态的编码器与另一种模态的解码器结合起来,使一种模态与另一种模态对齐。戴阳等。(2021)展示了单细胞染色质图像和 RNA 测序数据之间的转换。跨模式自动编码器的可行性和实用性尚未通过大规模临床相关数据集进行测试。然而,如果证明有效,它们将具有巨大的潜力,可以通过对齐和协调来自不同来源的数据来应对挑战。
4.method framework
就是把文章的主图讲清楚,必要的话配合公式,如果有loss目标函数loss的项目也讲清楚
4.主实验
5.analysis & ablation study
这里是更要细看的
6.critical thinking
:批判文章有什么不足 自己有什么想法