目录
在上一节我们已经配置好了python爬虫的环境python-配置爬虫环境,现在我们就来实践一下吧。
引入外部库
首先要引入python平台提供的两个库
pip install requests
pip install lxml安装XPath
引用好两个库后,还要在你的浏览器安装一个XPath的插件,以准确获取想要获取的文本信息。
1、下载XPath helper的源码
链接:https://pan.baidu.com/s/1MKNh06DSLCRsp4Wvl_uIUQ
提取码:6868
2、在edge中添加
源码下载后直接解压到文件夹,记住这个文件夹在哪里。
进入edge的扩展选项:
(1)点右上角的“...”->“扩展”
or (2)在地址栏输入:edge://extensions/
点图中的这个选项:
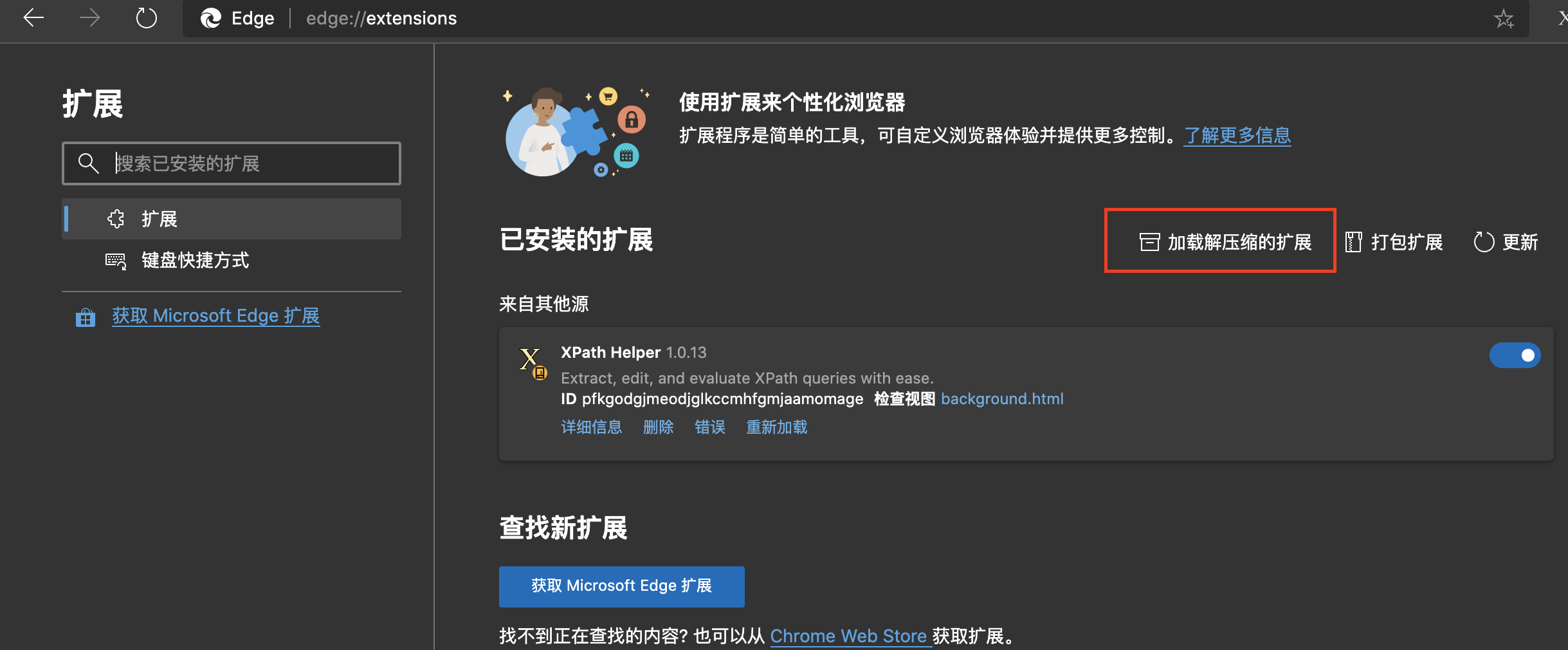
装好之后会像上图出现 XPath helper的扩展了。
记得打开左下角的“允许来自其他应用商店的扩展”选项。
3.使用Xpath helper
按快捷键是可以调用了。
windows: Shift + Ctrl + X
按住Shift把鼠标移动到想获取信息的地方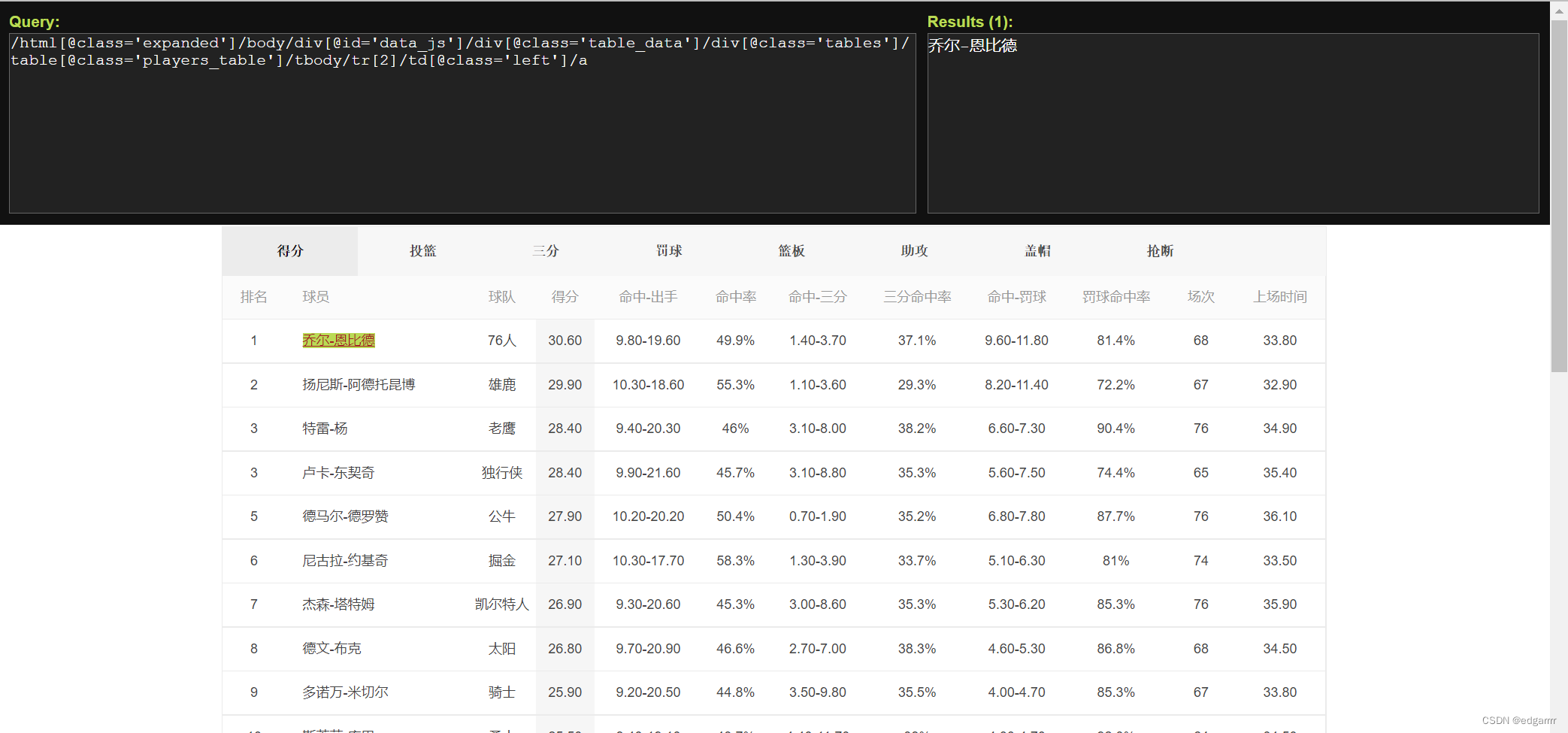
我们要记住Query框中的部分,以便我们在代码中使用。
原码
我们将想要请求的网址信息存入到url中
url = 'https://nba.hupu.com/stats/players'想访问一个网址有两种方法,一种是在浏览器中访问,一种是在代码中访问。而在代码中直接请求网址是不友好的,官 方也不喜欢我们这么做,这时候就就有一个小技巧,伪 装成浏览器访问的样子。教程如下:
在网页中按f12,进入开发者工具。在菜单栏中选择网络,子菜单中选择全部,查找user-agent属性。
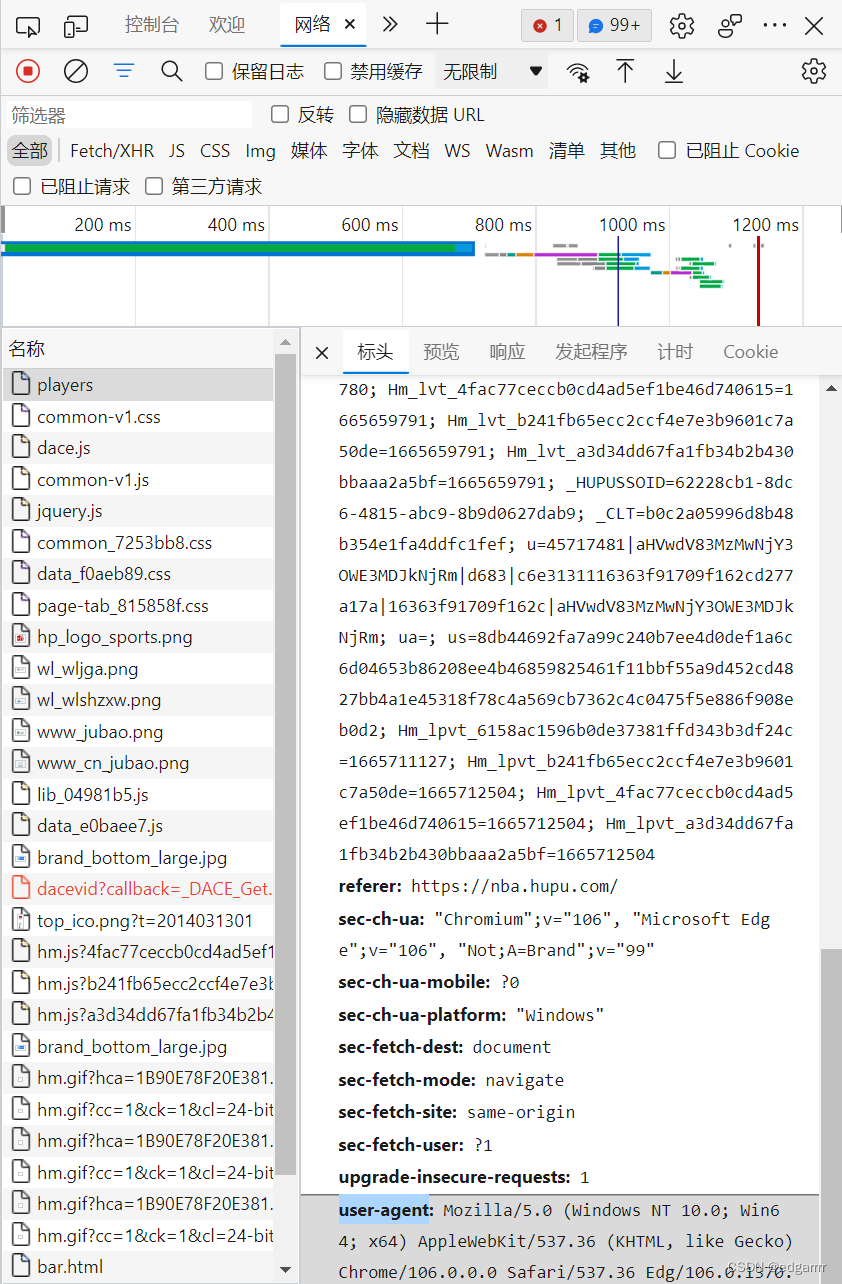
将 user- agent属性中的信息保存到headers变量中
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Edg/106.0.1370.42'}做好所有准备工作后,让我们看一看代码部分吧
import requests
from lxml import etree
url='https://nba.hupu.com/stats/players'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Edg/106.0.1370.42'}
#发送请求
resp=requests.get(url,headers=headers)
#处理结果
e=etree.HTML(resp.text)
#解析响应式数据
names=e.xpath('//html[@class="expanded"]//body/div[@id="data_js"]/div[@class="table_data"]/div[@class="tables"]/table[@class="players_table"]/tbody/tr/td[@class="left"]/a/text()')
teams=e.xpath('//html[@class="expanded"]//body/div[@id="data_js"]/div[@class="table_data"]/div[@class="tables"]/table[@class="players_table"]/tbody/tr/td[3]/a/text()')
scores=e.xpath('//html[@class="expanded"]//body/div[@id="data_js"]/div[@class="table_data"]/div[@class="tables"]/table[@class="players_table"]/tbody/tr/td[4]/text()')
这样就获取到了网页中球员的姓名、队伍和得分信息,接下来我们把这些信息打印到excel表格中,文件操作的详细知识可见python-文件与异常,代码如下:
import csv
with open('player.csv','a',newline='')as playercsv:
writer = csv.writer(playercsv)
writer.writerow(['姓名', '球队', '得分'])
for name,team,score in zip(names,teams,scores):
writer.writerow([name, team, score])在该python文件所在的文件夹下生成了player.csv的文件,我们打开后就会发现完成了我们想要的操作! 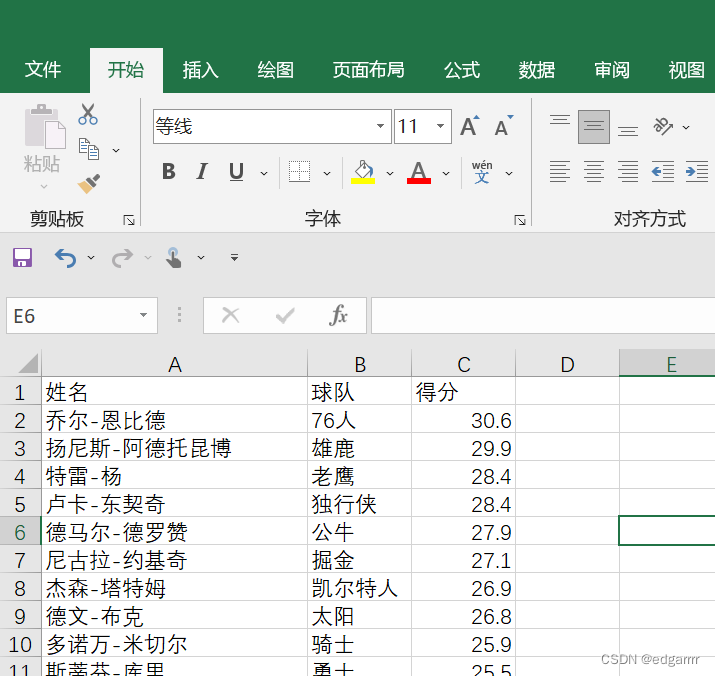
具体操作大家快去试试吧!