快毕业了吗,是不是对就业信息一无所知,以下也许能给你提供一下帮助,come on!!!
小编是为了实现功能而写的代码,没做优化,感兴趣的可以对代码进行优化,提高运行效率。
运行环境:
python3.7.4
requests
pandas
urllib
numpy
matplotlib
一、首先获取职业信息,此处从51job获取的。
以python为例,分别获取以下内容

先向请求51job资源,然后再进行内容提取,写到根目录下,命名为***_jobss.csv
要替换查询的职业信息,将主函数下的python替换成你要搜索的职业即可
'''
第一页
https://search.51job.com/list/000000,000000,0000,00,9,99,%25E6%25B1%25BD%25E8%25BD%25A6,2,1.html
第二页
https://search.51job.com/list/000000,000000,0000,00,9,99,%25E6%25B1%25BD%25E8%25BD%25A6,2,2.html
两个字以及两个字以内,编码转换要转两次,两个字以上转一次
'''
import requests
import pandas as pd
import time
import re
import urllib.parse
#给中文编码
def get_input(inpu_orin):
inpu_len = re.findall('[\u4e00-\u9fa5]',inpu_orin)
if len(inpu_len) <= 2:
inpu = urllib.parse.quote(inpu_orin)
inpu = urllib.parse.quote(inpu)
print(inpu)
else:
inpu = urllib.parse.quote(inpu_orin)
print(inpu)
return inpu
#获取url的内容
def get_url(inpu,pageno):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0\
.3683.86 Safari/537.36",
"Host": "search.51job.com",
"Upgrade-Insecure-Requests": "1",
"Cookie":"guid=ffa919e5f535e903b5a58205b7232c30; adv=adsnew%3D1%26%7C%26adsresume%3D1%26%7C%26adsfrom%3Dhttps%253A%252F%252Fsp0.baidu.com%252F9q9JcDHa2gU2pMbgoY3K%252Fadrc.php%253Ft%253D06KL00c00fDewkY0gPN900uiAsjB3nVT00000c6R7dC00000Ij-BMt.THYdnyGEm6K85yF9pywdpAqVuNqsusK15H61mymYuj6znj0sryD3rHb0IHY4rDuafYF7P1Rsrjn1f1b4nY7APjPanRwDfbNafWDvffK95gTqFhdWpyfqn1ckPHb4nH63nzusThqbpyfqnHm0uHdCIZwsT1CEQLwzmyP-QWRkphqBQhPEUiqYTh7Wui4spZ0Omyw1UMNV5HcsnjfzrjchmyGs5y7cRWKWiDYvHZb4IAD1RgNrNDukmWFFINbzrgwnndF8HjPrUAFHrgI-Uj94HRw7PDkVpjKBNLTEyh42IhFRny-uNvkou79aPBuo5HnvuH0dPA79njfdrynzuywbPycYPvmdPvPBPWDsuj6z0APzm1YzrHDYP6",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language":"zh-CN,zh;q=0.9",
"Connection": "keep-alive"
}
url = 'https://search.51job.com/list/000000,000000,0000,00,9,99,'+inpu+',2,'+str(pageno)+'.html'
print(url)
req = requests.get(url,headers=headers).content
#按F12可以看到这句,后面表示编码格式为gbk
#<meta http-equiv="Content-Type" content="text/html; charset=gbk">
req = req.decode('gbk') #解决乱码的问题
#print(req)
return req
#进行数据处理,获取表格
def data_process(req):
jobs_cities=[]
jobs_area=[]
jobs_name = re.findall('<a target="_blank" title="(.*?)"',req) #匹配出所需内容
jobs_co = re.findall('<span class="t2"><a target="_blank" title="(.*?)"',req)
jobs_place = re.findall('<span class="t3">(.*?)</span>',req)
jobs_price = re.findall('<span class="t4">(.*?)</span>',req)
jobs_date = re.findall('<span class="t5">(.*?)</span>',req)
jobs_url = re.findall(' href="(.*?)" οnmοusedοwn=',req)
for i in jobs_place:
cities_ = i.split("-")[0] #将 "广州-花都区" 进行分割,注意有空格 #这个语句比较费时间
try :
area_ = i.split("-")[1]
except Exception as e:
area_ = ''
jobs_cities.append(cities_)
jobs_area.append(area_)
# time.sleep(50000)
# print(len(jobs_co))
# print(len(jobs_url))
# print(jobs_url)
jobs_adds = pd.DataFrame() #创建一个数据
#jobs_adds.to_csv('./%s_jobs.csv' % a, index=False,encoding='ansi')
#请求url获得更多想要的信息
for url in jobs_url:
try:
time.sleep(1)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0\
.3683.86 Safari/537.36",
"Host": "jobs.51job.com",
}
jobs_url = url
# print(jobs_url)
req = requests.get(jobs_url,headers=headers).content
#按F12可以看到这句,后面表示编码格式为gbk
#<meta http-equiv="Content-Type" content="text/html; charset=gbk">
try:
req = req.decode('gbk') #解决乱码的问题
except Exception as e:
print(e)
#print(req)
jobs_treat = re.findall('<span class="sp4">(.*?)</span>',req)
jobs_req = re.findall('<p class="msg ltype" title="(.*?)"',req)
jobs_details= re.findall('<p><b>(.*?)<p><b>',req)
# if jobs_details == []:
# print('空了')
if jobs_details == []:
# print('还是空了')
jobs_details= re.findall('<p>(.*?)<p>',req)
if jobs_details == []:
jobs_details= re.findall('<span>(.*?)</span></div><div>',req)
# print('1',jobs_details)
if jobs_details == []:
jobs_details= re.findall('<p>(.*?)</p>',req)
# print("到这里了")
if jobs_details == []:
# print('还是空了')
jobs_details= re.findall('white-space: normal;">(.*?)</p>',req)
try:
j_r = jobs_req[0]
jobs_req = j_r.replace(' | ',' ') #从字符串中删除指定字符,把' | '全部替换为' '
except Exception as e:
jobs_req = "无"
# print(re.sub('[ | ]', '', j_r)) #与上面的效果一样
# print(j_r.translate(' | ')) #与上面的效果一样
# print(j_r)
jobs_treats = ''
for i in jobs_treat: #将列表遍历为字符串
jobs_treats = jobs_treats +i +' '
jobs_detail = ''
for i in jobs_details: #将列表遍历为字符串
jobs_detail = jobs_detail +i +' '
if jobs_treats == '':
jobs_treats = '无'
except Exception as e:
print(e)
jobs_req = '解码出错'
jobs_detail = '解码出错'
jobs_treats = '解码出错'
jobs_treats = [jobs_treats] #转为列表,经过上面转为字符串,所以这个列表只有一列
jobs_detail =[jobs_detail]
jobs_req = [jobs_req]
treats = pd.DataFrame(jobs_treats,columns=["treats"]) #将列表转换为DataFrame格式,从 <行变为列>
details=pd.DataFrame(jobs_detail,columns=["details"])
reqs=pd.DataFrame(jobs_req,columns=["reqs"])
# print(jobs_treats)
# print('-------------------------------------------')
# print(jobs_detail)
# print('-------------------------------------------')
# print(jobs_req)
jobs_add = pd.concat([treats,reqs,details],axis=1)
jobs_adds = pd.concat([jobs_adds,jobs_add],axis=0,ignore_index=True)
# print(jobs_adds)
#jobs_adds.to_csv('./%s_jobs.csv' % a, mode='a',index=False, header=False,encoding='ansi')
# print(jobs_add)
#time.sleep(1)
#print("开始写入")
#jobs_adds.to_csv('./%s_jobs.csv' % a, mode='a',index=False, header=False,encoding='ansi')
#print("写入完成")
for x in jobs_co: #分离出公司
jobs_name.remove(x)
jobs_cities.pop(0) #去除多匹配出来的第一项
jobs_area.pop(0)
jobs_price.pop(0)
jobs_date.pop(0)
# print(jobs_cities ,jobs_area)
# print(len(jobs_cities),len(jobs_area))
# print("在这里",jobs_reqs)
#print(jobs_place)
#print(jobs_price)
#print(jobs_date)
# print(len(jobs_name))
name = pd.DataFrame(jobs_name,columns=["name"]) #将列表转换为DataFrame格式,从 <行变为列>
price=pd.DataFrame(jobs_price,columns=["price"])
date=pd.DataFrame(jobs_date,columns=["date"])
co=pd.DataFrame(jobs_co,columns=["co"])
cities=pd.DataFrame(jobs_cities,columns=["citie"])
area=pd.DataFrame(jobs_area,columns=["area"])
jobs_all = pd.concat([name,co,cities,area,price,jobs_adds,date],axis=1) # 进行拼接 axis=1表现向左右合并 ignore_index=True 表示忽略所有索引
#print(jobs_all)
#jobs_all = jobs_all.loc[:, ['name','years', 'edu', 'cities','place','price','date']] #!!!如果拼接上去为空文件,加上这句
# print('jobs_all',jobs_all)
#jobs_all.to_csv('./%s_jobs.csv' % a, mode='a',index=False, header=False,encoding='ansi')
print(jobs_all)
return jobs_all
if __name__ == '__main__':
inpu_orin = 'python' #输入要搜索的职位
pageno = 0 #设置起始页数,一般为第0页
jobs_all = pd.DataFrame(columns=['职位','公司', '城市','区/县/镇', '薪资','待遇','要求','详情','发布日期']) #一开始就应该先定义好每一行的标签
print(jobs_all.columns)
jobs_all.to_csv('./%s_jobss.csv' % inpu_orin, index=False) #创建一个空文件用于存放,可以将已经存在的同名文件抹去
while True:
pageno = pageno+1 #从第一页开始
# print(pageno)
inpu = get_input(inpu_orin) #获取输入,将中文转码
req = get_url(inpu,pageno) #将转好码的中文添加到url中,取得完整的URL,获取总页面的请求,一个页面50个职业
jobs_all=data_process(req) #进行数据的处理,分别进入每个职业的子页面,进行详细信息的获取并整合信息
if jobs_all.empty: #判断获取的DataFrame是否为空,是的话,结束循环
print('end')
print(pageno)
break
else: #DataFrame不为空,执行追加写入文档
jobs_all.to_csv('./%s_jobss.csv' % inpu_orin, mode='a',index=False, header=False) #文件追加写入本地
time.sleep(2) #进行缓冲,以免ip被封
获取后得到的表格打开,直接用excel打开会出现乱码

先用记事本打开,另存文件,编码格式改为UTF-8,文件名称不变,覆盖即可

再次用excel打开可以看到

二、获取薪资
记得将函数 def read_data():下的python_jobs.csv 改为你要搜索的职业名称 比如***_jobs.csv
import pandas as pd
import re
import time
a = '6-8千/月'
b = '0.7-1.789万/月'
def split_mon(mon):
l_h_mon = []
try:
l_mon = mon.split("-")[0]
h_mon = mon.split("-")[1]
l_h_mon.append(l_mon)
l_h_mon.append(h_mon)
except Exception as e:
l_mon = mon.split("-")[0]
l_h_mon.append(l_mon)
return l_h_mon
def judge_num(h_mon_):
h_mon = re.findall('\d*\.\d*',h_mon_) #匹配出浮点数字
#print(i)
if h_mon != [] :
h_mon = str(h_mon[0])
if h_mon == []:
h_mon = re.findall('\d*',h_mon_)
h_mon = str(h_mon[0])
return h_mon
def mk_f(l_h_mon):
h_mon = 0
try:
l_mon = str(judge_num(l_h_mon[0]))
h_mon = str(judge_num(l_h_mon[1]))
#print(l_mon)
#print(h_mon)
l_mon = float(l_mon)
h_mon = float(h_mon)
except Exception as e:
l_mon = str(judge_num(l_h_mon[0]))
#print(l_mon)
l_mon = float(l_mon)
return l_mon,h_mon
def calculat(lh_mon):
l_mon,h_mon = lh_mon
if mon.find('万/年')>=0 and h_mon != 0: #判断是否有出现‘年’字
l_mon_r = l_mon * 10000 #计算
h_mon_r = h_mon * 10000
l_mon_r = [int(l_mon_r)] #转为列表
h_mon_r = [int(h_mon_r)]
# print(l_mon_r)
# print(h_mon_r)
elif mon.find('万/年')>=0 and h_mon == 0:
l_mon_r = l_mon * 10000
l_mon_r = [int(l_mon_r)]
h_mon_r = ['']
# print(l_mon_r)
elif mon.find('万/月')>=0 and h_mon != 0:
l_mon_r = l_mon * 10000 * 12
h_mon_r = h_mon * 10000 * 12
l_mon_r = [int(l_mon_r)]
h_mon_r = [int(h_mon_r)]
# print(l_mon_r)
# print(h_mon_r)
elif mon.find('万/月')>=0 and h_mon == 0:
l_mon_r = l_mon * 10000 * 12
l_mon_r = [int(l_mon_r)]
h_mon_r = ['']
# print(l_mon_r)
elif mon.find('千/月')>=0 and h_mon != 0:
l_mon_r = l_mon * 1000 * 12
h_mon_r = h_mon * 1000 * 12
l_mon_r = [int(l_mon_r)]
h_mon_r = [int(h_mon_r)]
# print(l_mon_r)
# print(h_mon_r)
elif mon.find('千/月')>=0 and h_mon == 0:
l_mon_r = l_mon * 1000 * 12
l_mon_r = [int(l_mon_r)]
h_mon_r = ['']
# print(l_mon_r)
else:
l_mon_r = ['']
h_mon_r = ['']
return l_mon_r,h_mon_r
def write_data(l_mon,h_mon):
#print(l_mon)
#print(h_mon)
if l_mon == [''] and h_mon == ['']:
#print('都为空,不写入')
pass
else:
#print('不为空,写入')
l_mon = pd.DataFrame(l_mon,columns=['low']) #将列表转为DataFrame
h_mon = pd.DataFrame(h_mon,columns=['high'])
mon_csv = pd.concat([l_mon,h_mon],axis=1) # 进行拼接 axis=1表现向左右合并 ignore_index=True 表示忽略所有索引
mon_csv.to_csv('./salary.csv',mode='a',index=False, header=False)
def read_data():
csv_data = pd.read_csv('./python_jobs.csv')
# csv_data = pd.read_csv('./机械设计_jobs .csv')
#print(csv_data['薪资'])
#print(csv_data['薪资'][1])
return csv_data['薪资'] #返回'薪资'列
if __name__ == '__main__':
print('running......')
mon_csv = pd.DataFrame(columns=['low','high']) #一开始就应该先定义好每一行的标签
mon_csv.to_csv('./salary.csv',index=False)
date = read_data()
j=0
for i in date:
try:
#print(j)
mon = date[j] #要防止不能被分割的情况
l_h_mon = split_mon(mon)
lh_mon = mk_f(l_h_mon)
l_mon,h_mon = calculat(lh_mon)
write_data(l_mon,h_mon)
j+=1
except Exception as e:
l_mon_ = pd.DataFrame(['NAN'],columns=['low']) #将列表转为DataFrame
h_mon_ = pd.DataFrame(['NAN'],columns=['high'])
mon_csv = pd.concat([l_mon_,h_mon_],axis=1) # 进行拼接 axis=1表现向左右合并 ignore_index=True 表示忽略所有索引
mon_csv.to_csv('./salary.csv',mode='a',index=False, header=False)
j+=1
print('end!!!')
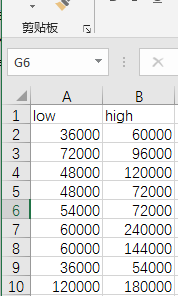
获取后并保存在根目录下,命名为salary.csv,打开之后可以看到以下的表格,薪资是有一个范围的,也就是低价和高价,low表示低价,high表示高价,已经处理为年薪。
三、进行薪资处理,以下代码是对low列的薪资进行处理(将下面代码的low改为high即可获取高位薪资的),将薪资去重,并获取不同薪资出现的频数,能够得出那个薪资水平出现次数最多。
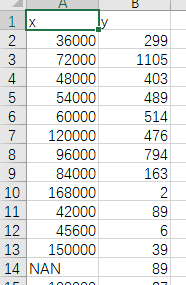
获取后保存到根目录,命名为x_y.csv
x表示薪资,y表示出现频数,其中NAN表示该公司未给出薪资
import pandas as pd
import re
import time
import numpy as np
y_num = []
x_price = []
csv_data = pd.read_csv('./salary.csv')
price = csv_data.drop_duplicates(subset = 'low') #去除列名为"低价"的重复内容,subset为column
price = price['low']
data_price = pd.read_csv('./salary.csv')
data_price = data_price['low'] #数据输入
#print(data_price)
print(len(data_price))
#print(data_price)
for i in price: #i为字符串类型
exec ("price_%s=0"%i)
#print('薪资种类',i)
#print(type(i))
#print(locals())
for i in data_price: #1,2,3,4,5,6 遍历输入的薪资
# print('当前值为',i)
# train_x_list.pop(0)
# print('长度减少',36608-len(train_x_list))
# print('---------')
# time.sleep(5)
#print(type(i))
for j in price: #1,2 遍历薪资
# print(j)
# print(i.find('j'))
if i == j :
# print('大于0')
locals()["price_%s"%j] = locals()["price_%s"%j]+1 #用local对动态变量进行读取和计算
# exec('print("price_"+str(i),price_{}, end=" ")'.format(i))
# print('##########')
# time.sleep(2)
total = 0
for i in price:
print('')
exec('print("price_"+str(i),price_{}, end=" ")'.format(i))
total += locals()["price_%s"%i]
print('---------------')
print(total)
#----------------以下为增加的内容
for i in price: #重新建立一个,不然索引会出错
y = str(locals()["price_%s"%i])
y_num.append(y) #y_num为列表
x_price.append(i)
y_num = pd.DataFrame(y_num,columns=["y_num"])
x_price = pd.DataFrame(x_price,columns=["x_price"])
#x_price.reset(columns = True)
pd.DataFrame(columns=['x','y']).to_csv('./x_y.csv', index=False)
x_y = pd.concat([x_price,y_num],axis=1,ignore_index=True,)
x_y.to_csv('./x_y.csv', mode='a',index=False, header=False)
将上面处理的薪资进行图形化
import matplotlib.pyplot as plt
import pandas as pd
#解决打印图片出现中文乱码的问题
from pylab import mpl
#mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 指定默认字体:解决plot不能显示中文问题
data = pd.read_csv('./x_y.csv')
#print(data['y'])
j = 0
for i in data['y']:
print(int(i))
if int(i)<10:
data.drop([j],axis=0,inplace=True)
print('清除一次',i)
j += 1
print('清除之后',data['y'])
x = []
for i in data['x']:
if i != 'NAN':
i = int(i)
i = i/10000
x.append(str(i))
else:
x.append('其他')
#for i in data['y']
print(data['y'])
print(x)
y = data['y']
#画柱状图
plt.bar(x,y)
#标识标题及坐标轴信息
plt.title('51job_2020_python')
plt.xlabel('年薪(万/年)')
plt.ylabel('出现频率')
#显示画图结果
plt.show()
画出的柱形图如下所示,图太长了,只截了一部分:

获取职业要求,主要获取学历要求,并画成饼图
import pandas as pd
import re
import time
import matplotlib.pyplot as plt
#解决打印图片出现中文乱码的问题
from pylab import mpl
#mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 指定默认字体:解决plot不能显示中文问题
data = pd.read_csv('机械设计_jobs.csv')
data_reqs = data['要求']
data_price = data['薪资']
data_job = data['职位']
data_co = data['公司']
data_city = data['城市']
data_treats = data['待遇']
num_cz = 0
num_gz = 0
num_dz = 0
num_bk = 0
num_ss = 0
num_bs = 0
num_bsh = 0
num_qt = 0
for i in data_reqs:
print(type(i))
print(i)
if i.find('初中')>=0:
num_cz += 1
elif i.find('高中')>=0:
num_gz += 1
elif i.find('大专')>=0:
num_dz += 1
elif i.find('本科')>=0:
num_bk += 1
elif i.find('硕士')>=0:
num_ss += 1
elif i.find('博士')>=0:
num_bs += 1
elif i.find('博士后')>=0:
num_bsh += 1
else:
num_qt += 1
print('初中','高中','大专','本科','硕士','博士','博士后','其他')
print(num_cz,num_gz,num_dz,num_bk,num_ss,num_bs,num_bsh,num_qt)
add_all = num_cz+num_gz+num_dz+num_bk+num_ss+num_bs+num_bsh+num_qt
print(add_all)
#分别取出gdp类别列表和gdp列表
labels = ['初中','高中','大专','本科','硕士','博士','博士后','其他']
values = [num_cz,num_gz,num_dz,num_bk,num_ss,num_bs,num_bsh,num_qt]
#指定图形大小
plt.figure(figsize=(6,6))
#画图
plt.pie(values,
labels=labels, #设置每个块的标签
autopct='%.1f%%', #设置小数点后一位和所占百分比以及百分号 **.*%
startangle=90 #设置开始角度
)
#设置样式
plt.axis('equal')
#显示图例
plt.legend()
#显示图片
plt.show()
图中其他表示公司未给出学历要求

统计工作地点,得出哪个城市工作机会较多,获取后保存到根目录下,命名为python_city.csv
import pandas as pd
import re
import time
import matplotlib.pyplot as plt
#解决打印图片出现中文乱码的问题
from pylab import mpl
#mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 指定默认字体:解决plot不能显示中文问题
data_name = 'python'
data = pd.read_csv('./%s_jobs.csv' % data_name)
data_cities = data['城市']
cities = set(data_cities) #转为集合,可以去重
#print(cities)
#print(type(cities))
cities = list(cities) #将集合转为列表
#print(cities)
num = [0 for x in range(0, len(cities))] #创建列表,用于储存城市频数
#print(type(data_cities))
#print(data_cities[1])
#print(cities[1])
n = 0
for i in cities:
for j in data_cities:
if i == j:
num[n] +=1
#print(i)
#print(num[n])
n += 1
print(sum(num))
x = cities
y = num
cities = pd.DataFrame(cities,columns=["城市"])
num = pd.DataFrame(num,columns=["频数"])
data_all = pd.concat([cities,num],axis=1)
data_all = data_all.sort_values(by = '频数',axis=0,ascending = False) #按照列排序,降序
city = pd.DataFrame(columns=['城市','频数'])
city.to_csv('./%s_city.csv' % data_name, index=False)
print(data_all)
data_all.to_csv('./%s_city.csv' % data_name, mode='a',index=False, header=False)
'''
1、先读取已存储的数据中的城市列表
2、城市去重
3、遍历城市列表,并记数
4、画图
'''

到此为此结束战斗
