资源下载地址:https://download.csdn.net/download/sheziqiong/85673772
实验目的
使用Python爬虫技术获取小说信息,包括小说名称、小说作者以及小说简介等作品信息!在实验中掌握Python的第三方库requests和lxml
实验内容
- 明确实验需求——获取小说页面的相关小说信息
- 使用Python的requests库获取响应信息
- 使用python的lxml库进行必要信息的提取
- 保存信息到txt文件中!
- 进行多页信息提取,找到规律
主要仪器设备(必填)
- python编译器Pycharm
- Chrome浏览器F12进行网页的分析
操作方法和实验步骤
- 确定网页URL链接:http://www.ijjxsw.com/txt/Xuanhuan/index_1.html
- 确定爬取的信息:小说名称、作者以及简介
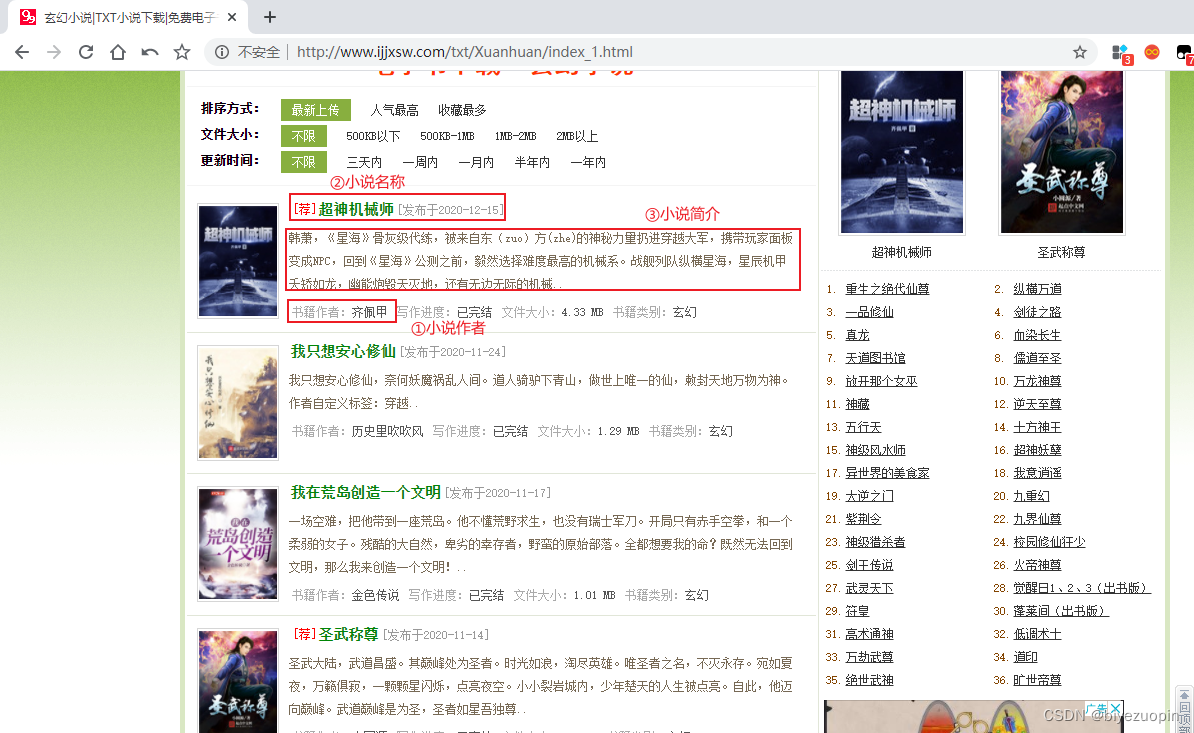
- 进行网页的分析,在Chrome浏览器打开网页之后,按快捷键F12开始分析网页,得到要爬取得信息的标签和属性信息!
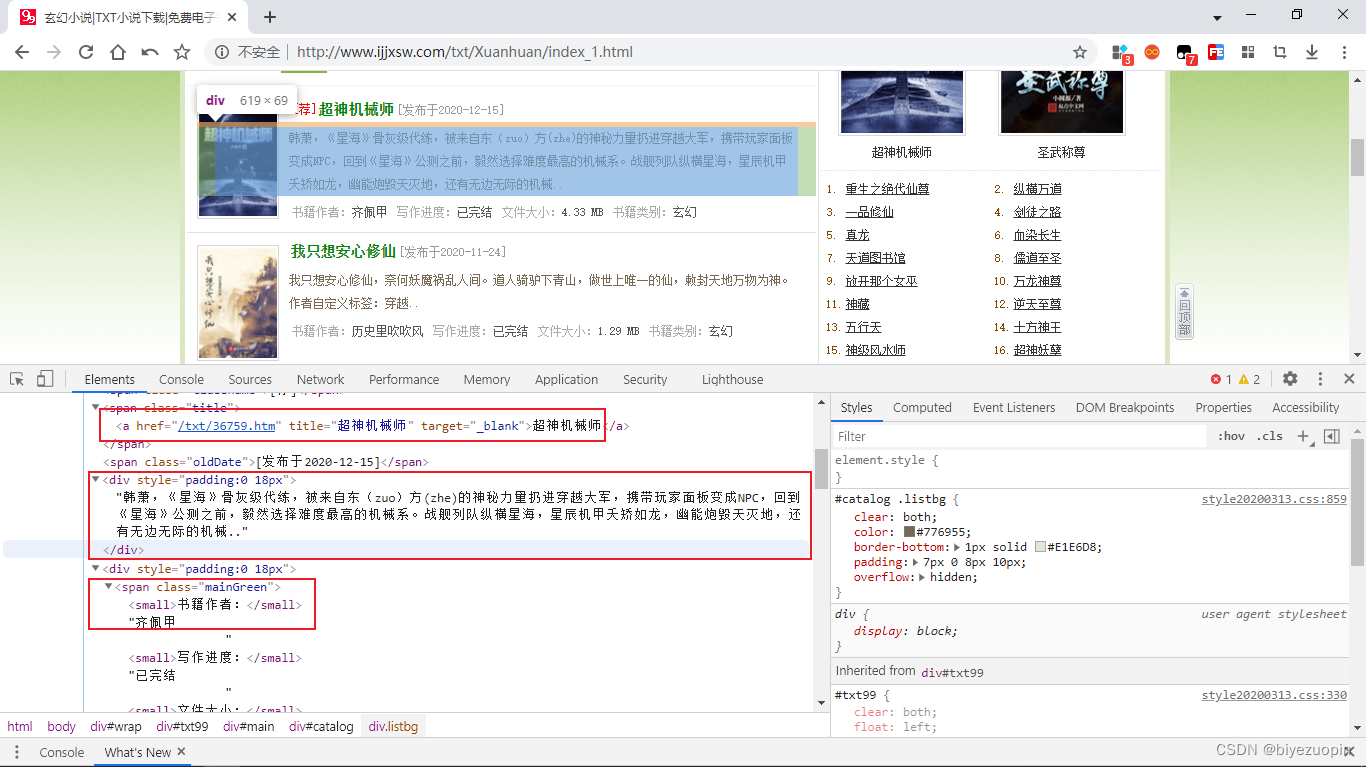
- 编写代码,逐步实现需求!
实验结果和分析
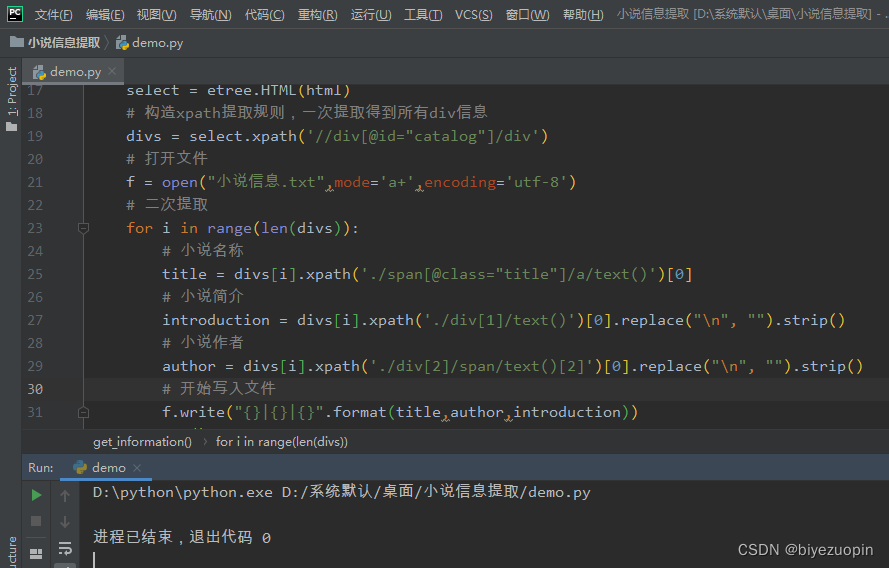
实验结果:通过编写代码,并合理解析页面以及多次调试解决爬虫过程中出现的问题,代码运行成功,获取到了第一页的10本小说的作者名、小说简介以及小说名称!
运行截图如下:
得到的txt文件截图:

实验分析:
本次实验通过编写爬虫代码,从网页中之间抓取信息,保存到本地文件中!较好的达到了实验前的需求!
讨论、心得
-
Python爬虫技术能大大方便人们的生活,很多手工操作需要大量时间,但是通过编写python爬虫代码很快就能从网页中获取信息
-
Txt文件保存信息有缺陷,格式方面很不美观,建议用excel替代
-
爬虫能获取大量数据,因此了解到了有反爬的相关内容
资源下载地址:https://download.csdn.net/download/sheziqiong/85673772