今天写一个通过python获取论坛用户信息的demo
有朋友会问,这玩意有啥用么?用处老大了,举个栗子,通过获取到用户的信息与本地库比对,就会获得N多账号密码,不多解释
爬取一个CTF的站吧,https://www.bugku.com/
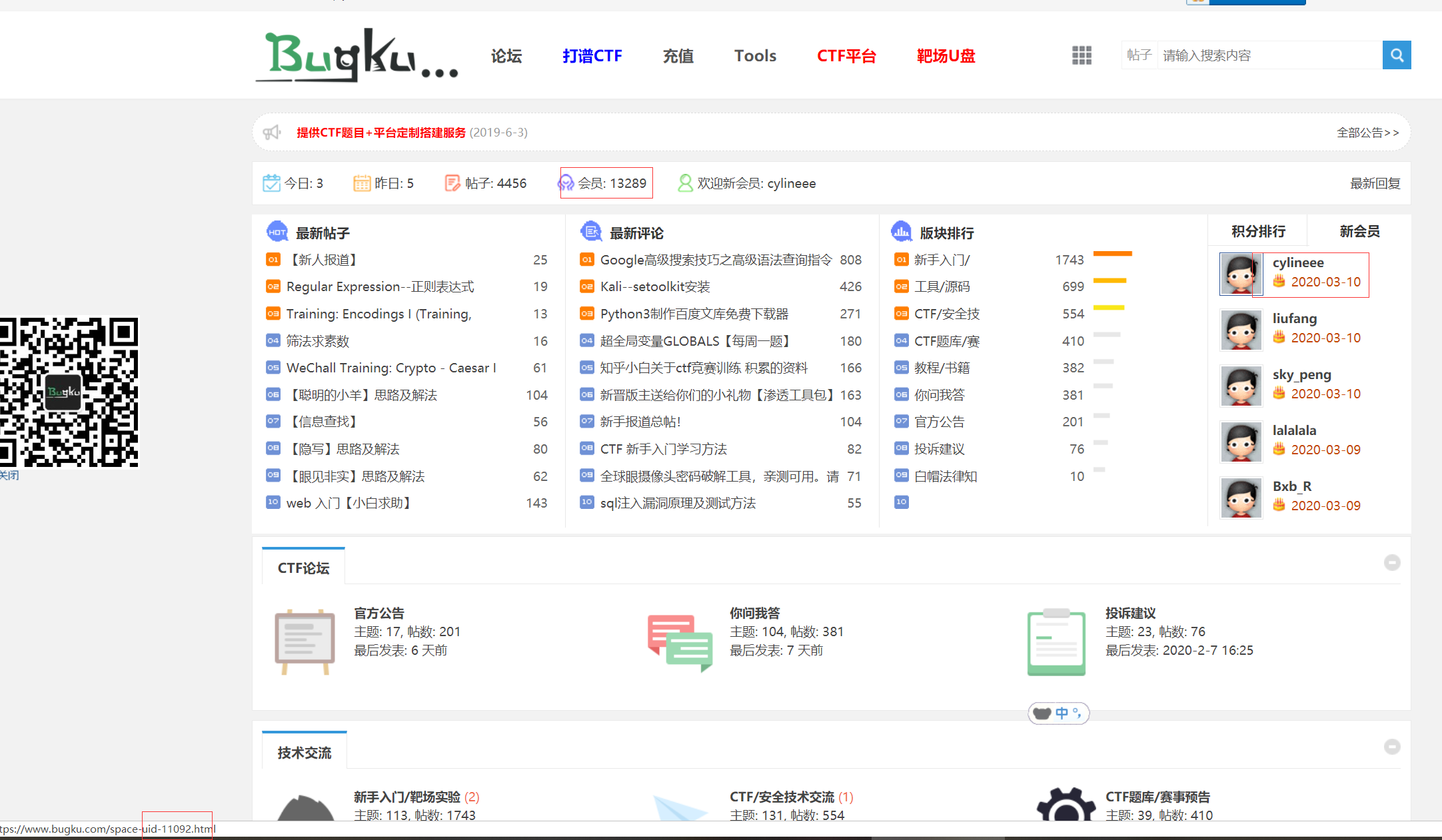
先分析 1.会员数量,看图说话,明显官网提供的数据不对,自己抓取吧。
2.抓取会员用户名、id、用户组

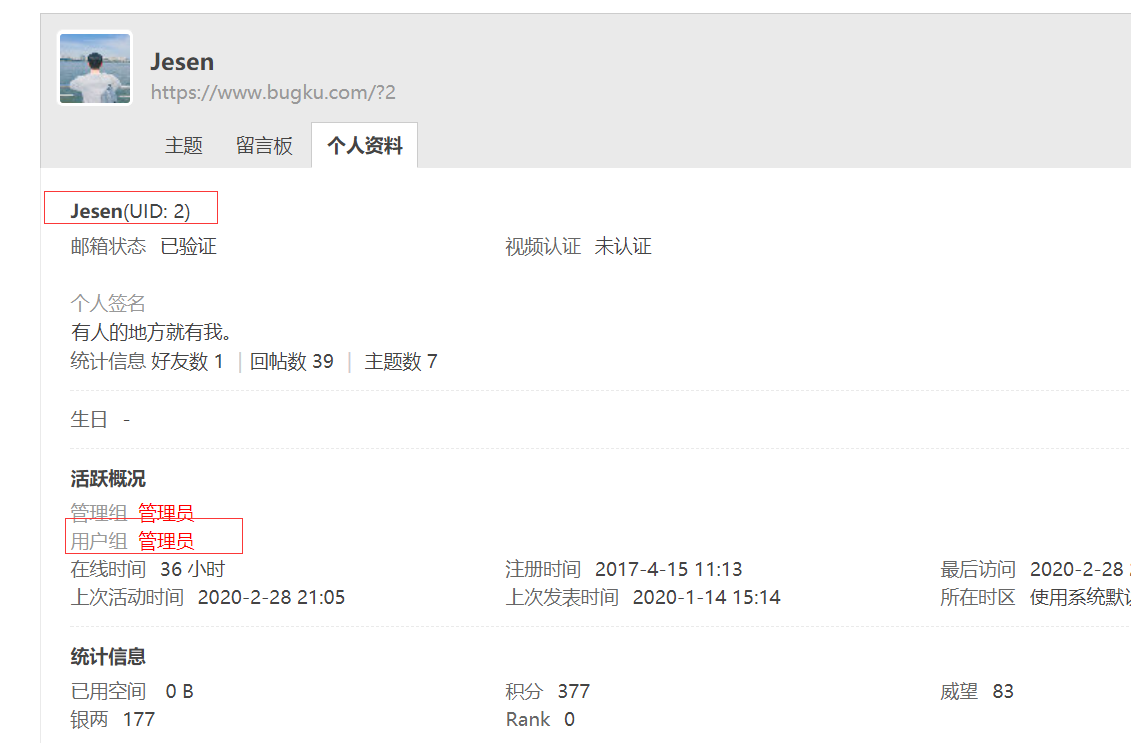
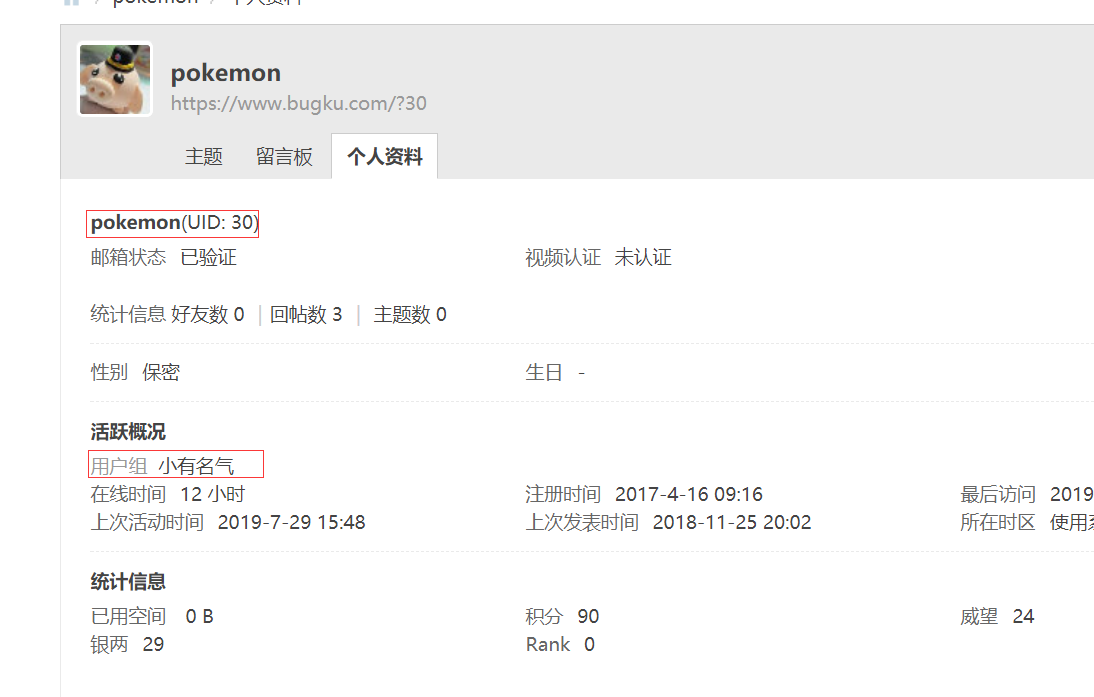
通过代码对比,用户组中 管理员与普通用户的抓取格式不一样,在代码中做了一次判断,对于 有的会员没有用户组,直接就传空值
抓取后的MySQL图:

看代码吧,里面的细节自己分析自己看!
1 # -- coding: utf-8 -- 2 import pymysql 3 import requests 4 from lxml import etree 5 headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"} 6 class spiders(object): 7 """爬取""" 8 def html(self,url): 9 """"抓取目标网页源码""" 10 html=response=requests.request("get",url,headers=headers) 11 if html.status_code ==200: 12 return response.text 13 def spider(self,html): 14 html1=etree.HTML(html) 15 title=html1.xpath("//title/text()") 16 try: 17 if str(title).find("个人资料"): 18 username = html1.xpath(".//h2[@class='mbn']/text()") 19 username = str(str(username[0]).split()).replace("[","").replace("]","") 20 #对所有的获取信息进行去除[],()处理,字符格式化 21 id = html1.xpath(".//span[@class='xw0']/text()") 22 id = str(id).replace("UID: ", "").replace("(","").replace(")","").replace("[","").replace("]","") 23 groups = html1.xpath(".//ul/li/span/a/text()") 24 if len(groups) == 0: 25 groups = html1.xpath(".//li[2]/span/a/font/text()") 26 groups=str(groups).replace("[","").replace("]","") 27 # 这里只抓取用户组和管理组,两个组的源码不一致 ,所以进行判断 28 # print(username) 29 # print(id) 30 # print(groups) 31 except: 32 print("用户被禁用,忽略") 33 username="";id="";groups="" 34 return id,username,groups 35 def spider_newuser(self): 36 url = "https://www.bugku.com/" 37 html=self.html(url) 38 html1 = etree.HTML(html) 39 # new_user = html1.xpath("//title/text()") 40 new_user_id=html1.xpath(".//div[@id='content1_2']/div[@class='ptA st clear'][1]/h4/a/@href") 41 new_user_id=int(str(new_user_id).replace("space-uid-","").replace(".html","").replace('[','').replace(']','').replace("'","")) 42 return new_user_id 43 class writeobj(object): 44 """把爬取信息写入mysql""" 45 def write_pa(self,id,username,groups): 46 db=pymysql.connect(host="localhost",user="root",password="root",port=3306,db="DZ_spider") 47 if id=="": 48 return None 49 cursor=db.cursor() 50 table="users" 51 data={ 52 "id":id, 53 "username":username, 54 "groups":groups 55 } 56 keys=",".join(data.keys()) 57 values=tuple(data.values()) 58 sql=f"INSERT INTO {table} VALUES{values}" 59 # print(sql) 60 try: 61 if cursor.execute(sql): 62 print("successful") 63 db.commit() 64 except: 65 print("Failed") 66 db.rollback() 67 db.close() 68 69 if __name__ == '__main__': 70 spiders=spiders() 71 write = writeobj() 72 new_user_id = spiders.spider_newuser() 73 # url = f"https://www.bugku.com/space-uid-3008.html" 74 for i in range(1,new_user_id): 75 url = f"https://www.bugku.com/space-uid-{i}.html" 76 html=spiders.html(url) 77 id,username,groups=spiders.spider(html) 78 write.write_pa(id, username, groups)