使用 sklearn笔记:AgglomerativeClustering_UQI-LIUWJ的博客-CSDN博客中的凝聚层次分类
from sklearn.cluster import AgglomerativeClustering
import numpy as np
X = np.array([[1, 2], [1, 4], [1, 0],
[4, 2], [4, 4], [4, 0]])
model = AgglomerativeClustering(distance_threshold=0, n_clusters=None)
model=model.fit(X)
counts = np.zeros(model.children_.shape[0])
'''
model.children_是一个n_sample-1*2的数组
从每个样本单独为一个簇,到所有样本是一个簇,一共需要n_sample-1轮
model.children_每一行([a,b])表示第i轮迭代,会将簇a和簇b合并
如果簇a或簇b的编号比n_sample小,那么簇a或簇b表示单个样本组成的叶子节点
如果簇a或簇b的编号比n_sample大,那么簇a或簇b表示第a-n_sample或第b-n_sample次合并后形成的新簇(非叶节点)
count[i]需要计算的是,第i轮合并后,形成的新簇的大小
'''
n_samples = len(model.labels_)
for i, merge in enumerate(model.children_):
#merge是当前轮需要merge的两个节点的index组成的list
#i的范围是0~n_samples-1
current_count = 0
for child_idx in merge:
if child_idx < n_samples:
current_count += 1
# 其中一个合并的簇是编号为child_idx的叶子节点,所以当前合并的样本数量仅仅+1
else:
current_count += counts[child_idx - n_samples]
#其中一个合并的簇是第child_idx - n_samples轮合并后生成的新簇,所以当前合并的样本数量+第child_idx - n_samples轮合并后生成的新簇的大小
counts[i] = current_count
#第i轮合并后的新簇的大小
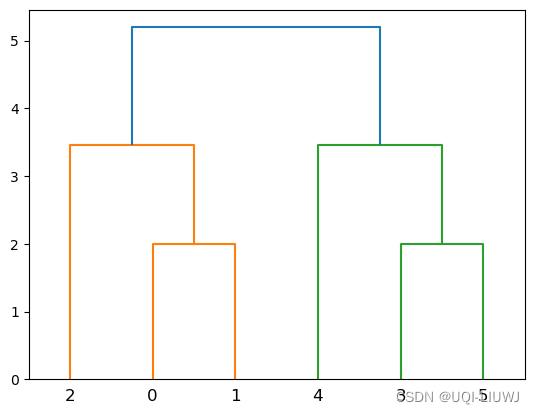
counts
#array([2., 2., 3., 3., 6.])
model.distances_
#array([2. , 2. , 3.46410162, 3.46410162, 5.19615242])
#第i轮合并的两个簇之间的距离
linkage_matrix = np.column_stack(
[model.children_, model.distances_, counts]
).astype(float)
linkage_matrix
'''
array([[0. , 1. , 2. , 2. ],
[3. , 5. , 2. , 2. ],
[2. , 6. , 3.46410162, 3. ],
[4. , 7. , 3.46410162, 3. ],
[8. , 9. , 5.19615242, 6. ]])
'''
'''
第i轮合并哪两个簇,这两个簇之间的距离是多少,合并后的簇多大
'''
dendrogram(linkage_matrix)