一、文法
E::=E+T|T
T::=T*F|F
F::=(E)|i
二、源代码模块
(一)消除文法的左递归
#pragma once
#pragma once
#include <iostream>
#include <map>
#include <set>
#include <vector>
#include <iomanip>
#include <fstream>
#include <stack>
#include <string>
void ReadGrammarFile(std::vector<std::string>& grammarList, std::string url)
{
std::ifstream input(url);
std::string line;
if (input)
{
while (std::getline(input, line))
{
grammarList.push_back(line);
}
}
}
void PrintGrammar(const std::vector<std::string>& grammarList)
{
for (std::string oneGrammar : grammarList)
{
std::cout << oneGrammar << std::endl;
}
}
void SetToVector(const std::set<std::string>& oneSet, std::vector<std::string>& oneVector)
{
oneVector.clear();
for (std::string item : oneSet)
{
oneVector.push_back(item);
}
}
void GetTerminator_Nonterminal(const std::vector<std::string>& grammarList,
std::vector<std::string>& terminatorList,
std::vector<std::string>& nonterminalList)
{
std::set<std::string> terminator;
std::set<std::string> nonterminal;
for (std::string oneGrammar : grammarList)
{
int len = oneGrammar.length();
for (int i = 0; i < len; i++)
{
if (oneGrammar[i] == '|')
{
continue;
}
else if (i < len - 1 && oneGrammar[i] == '-' && oneGrammar[i + 1] == '>')
{
i++;
continue;
}
else if (i < len - 2 && oneGrammar[i] == ':' && oneGrammar[i + 1] == ':' && oneGrammar[i + 2] == '=')
{
i += 2;
continue;
}
else if (oneGrammar[i] >= 'A' && oneGrammar[i] <= 'Z')
{
if (i < len - 1 && oneGrammar[i + 1] == '\'')
{
nonterminal.insert(oneGrammar.substr(i, 1) + "'");
i++;
}
else
{
nonterminal.insert(oneGrammar.substr(i, 1));
}
}
else
{
terminator.insert(oneGrammar.substr(i, 1));
}
}
}
SetToVector(nonterminal, nonterminalList);
SetToVector(terminator, terminatorList);
}
void PrintTerminator(const std::vector<std::string>& terminatorList)
{
std::cout << "终结符号集为" << std::endl;
for (std::string item : terminatorList)
{
std::cout << item << " ";
}
std::cout << std::endl;
}
void PrintNonterminal(const std::vector<std::string>& nonterminalList)
{
std::cout << "非终结符号集为" << std::endl;
for (std::string item : nonterminalList)
{
std::cout << item << " ";
}
std::cout << std::endl;
}
std::string GetFirstChar(const std::string str)
{
std::string firstChar = str.substr(0, 1);
if (str.length() > 1 && str.substr(1, 1) == "'")
{
firstChar = str.substr(0, 2);
}
return firstChar;
}
std::vector<std::string> DivideOneGrammar(const std::string oneGrammar)
{
std::vector<std::string> oneDividedGrammar;
std::string part;
int i = 1;
part = oneGrammar.substr(0, 1);
char startChar = oneGrammar[0];
if (oneGrammar.substr(1, 1) == "'")
{
i++;
part = oneGrammar.substr(0, 2);
}
oneDividedGrammar.push_back(part);
if (oneGrammar.substr(i, 2) == "->")
{
oneDividedGrammar.push_back("->");
part = "";
i += 2;
}
else if (oneGrammar.substr(i, 3) == "::=")
{
oneDividedGrammar.push_back("::=");
part = "";
i += 3;
}
else
{
std::cout << "文法错误" << std::endl;
exit(-1);
}
for (; i < oneGrammar.length(); i++)
{
if (oneGrammar[i] == '|')
{
oneDividedGrammar.push_back(part);
part = "";
oneDividedGrammar.push_back("|");
continue;
}
part += oneGrammar[i];
}
oneDividedGrammar.push_back(part);
return oneDividedGrammar;
}
void GetOneGrammarAllRight(const std::string oneGrammar, std::map<std::string, std::vector<std::string>>& allRightMap)
{
std::vector<std::string> oneDividedGrammar = DivideOneGrammar(oneGrammar);
std::string key = oneDividedGrammar[0];
for (int i = 2; i < oneDividedGrammar.size(); i++)
{
std::string part = oneDividedGrammar[i];
if (part != "|")
{
allRightMap[key].push_back(part);
}
}
}
void GetAllRightMap(std::map<std::string, std::vector<std::string>>& allRightMap,
const std::vector<std::string>& grammarList)
{
for (std::string oneGrammar : grammarList)
{
GetOneGrammarAllRight(oneGrammar, allRightMap);
}
}
int GetGrammarIndexByLeft(std::string left, const std::vector<std::string>& grammarList)
{
for (int i = 0; i < grammarList.size(); i++)
{
std::string oneGrammar = grammarList[i];
std::string firstChar = GetFirstChar(oneGrammar);
if (firstChar == left)
{
return i;
}
}
}
std::vector<std::pair<std::string, int>> GetPairIndex(const std::vector<std::string>& nonterminalList,
std::map<std::string, std::vector<std::string>> allRightMap)
{
std::vector<std::pair<std::string, int>> leftRecursionIndex;
for (std::string left : nonterminalList)
{
std::vector<std::string> oneAllRight = allRightMap[left];
for (int i = 0; i < oneAllRight.size(); i++)
{
std::string oneRight = oneAllRight[i];
std::string startChar = GetFirstChar(oneRight);
if (left == startChar)
{
leftRecursionIndex.push_back(std::make_pair(left, i));
}
}
}
return leftRecursionIndex;
}
void EliminateOneLeftRecursion(std::string left, int rightIndex, std::vector<std::string>& grammarList,
const std::vector<std::string>& oneAllRight, int grammarIndex)
{
std::string A = left;
std::string alpha = oneAllRight[rightIndex].substr(A.length());
std::string beta = oneAllRight[1 - rightIndex];
grammarList.erase(grammarList.begin() + grammarIndex);
std::string grammar1 = A + "::=" + beta + A + "'";
std::string grammar2 = A + "'::=" + alpha + A + "'|$";
grammarList.push_back(grammar1);
grammarList.push_back(grammar2);
}
void EliminateAllLeftRecursion(const std::vector<std::string>& nonterminalList,
std::vector<std::string>& grammarList,
std::map<std::string, std::vector<std::string>> allRightMap)
{
std::vector<std::pair<std::string, int>> pairIndex = GetPairIndex(nonterminalList, allRightMap);
for (int i = 0; i < pairIndex.size(); i++)
{
std::string left = pairIndex[i].first;
int rightIndex = pairIndex[i].second;
std::vector<std::string> oneAllRight = allRightMap[left];
int grammarIndex = GetGrammarIndexByLeft(left, grammarList);
EliminateOneLeftRecursion(left, rightIndex, grammarList, oneAllRight, grammarIndex);
}
}
void SetFirstGrammar(std::vector<std::string>& grammarList, std::string startChar)
{
std::string oneGrammar = grammarList[0];
std::string firstChar = GetFirstChar(oneGrammar);
if (firstChar == startChar)
{
return;
}
for (int i = 1; i < grammarList.size(); i++)
{
oneGrammar = grammarList[i];
firstChar = GetFirstChar(oneGrammar);
if (startChar == firstChar)
{
grammarList[i] = grammarList[0];
grammarList[0] = oneGrammar;
break;
}
}
}
void EliminateLeftRecursion(const std::vector<std::string>& nonterminalList, std::vector<std::string>& grammarList)
{
std::map<std::string, std::vector<std::string>> allRightMap;
GetAllRightMap(allRightMap, grammarList);
const std::string grammarStartChar = GetFirstChar(grammarList[0]);
EliminateAllLeftRecursion(nonterminalList, grammarList, allRightMap);
SetFirstGrammar(grammarList, grammarStartChar);
}
(二)求First集
#pragma once
#include <iostream>
#include <map>
#include <set>
#include <vector>
#include <iomanip>
#include <fstream>
#include <stack>
#include <string>
#include "EliminateLeftRecursion.h"
std::vector<std::string> GetAllLeftRightList(std::map<std::string, std::vector<std::string>> allRightMap)
{
std::vector<std::string> allSentenceList;
std::set<std::string> allSentenceSet;
for (auto item: allRightMap)
{
allSentenceSet.insert(item.first);
for (auto item2 : item.second)
{
allSentenceSet.insert(item2);
}
}
SetToVector(allSentenceSet, allSentenceList);
return allSentenceList;
}
bool IsTerminator(std::string ch, const std::vector<std::string>& terminator)
{
for (std::string item : terminator)
{
if (ch == item)
{
return true;
}
}
return false;
}
void GetOneFirst(std::string& sentence,
std::vector<std::string>& First,
const std::vector<std::string>& terminator,
std::map<std::string, std::vector<std::string>> allRightMap)
{
std::string firstChar = GetFirstChar(sentence);
if (IsTerminator(firstChar, terminator))
{
First.push_back(firstChar);
return;
}
else
{
std::vector<std::string> oneAllRight = allRightMap[firstChar];
for (std::string item : oneAllRight)
{
sentence = item + sentence.substr(firstChar.length());
GetOneFirst(sentence, First, terminator, allRightMap);
}
}
}
void PrintAllSentence(const std::vector<std::string>& allSentence)
{
std::cout << "全部的左部和右部如下" << std::endl;
for (std::string item : allSentence)
{
std::cout << item << " " << std::endl;
}
std::cout << std::endl;
}
void PrintFirst(std::map<std::string, std::set<std::string>>& First)
{
std::cout << "FIRST 集如下" << std::endl;
for (std::pair<std::string, std::set<std::string>> item : First)
{
std::cout << std::left << std::setw(4) << item.first << ": { ";
for (std::string ii : item.second)
{
std::cout << ii << ", ";
}
std::cout << "\b\b }" << std::endl;
}
std::cout << std::endl;
}
std::map<std::string, std::set<std::string>> GetFirstSet(
const std::vector<std::string>& terminatorList,
const std::vector<std::string>& nonterminalList,
std::map<std::string, std::vector<std::string>> allRightMap)
{
std::vector<std::string> allSentenceList;
allSentenceList = GetAllLeftRightList(allRightMap);
PrintAllSentence(allSentenceList);
std::map<std::string, std::set<std::string>> First;
std::vector<std::string> oneFirst;
for (std::string sentence : allSentenceList)
{
std::string sentenceTemp = sentence;
oneFirst.clear();
GetOneFirst(sentence, oneFirst, terminatorList, allRightMap);
for (std::string item : oneFirst)
{
First[sentenceTemp].insert(item);
}
}
return First;
}
(三)求Follow集
#pragma once
#include "EliminateLeftRecursion.h"
#include "MyFirst.h"
void PairSetToPairVector(const std::set<std::pair<std::string, std::string>>& onePairSet,
std::vector<std::pair<std::string, std::string>>& onePairVector)
{
onePairVector.clear();
for (std::pair<std::string, std::string> item : onePairSet)
{
onePairVector.push_back(item);
}
}
bool IsNonterminal(std::string ch, const std::vector<std::string>& nonterminalList)
{
for (std::string item : nonterminalList)
{
if (ch == item)
{
return true;
}
}
return false;
}
std::vector<std::string> GetOneCandidateAllLeft(const std::string candidate,
const std::map<std::string, std::vector<std::string>> allRightMap)
{
std::vector<std::string> allLeft;
for (std::pair<std::string, std::vector<std::string>> item : allRightMap)
{
std::string left = item.first;
std::vector<std::string> oneAllRight = item.second;
for (std::string oneRight : oneAllRight)
{
if (oneRight == candidate)
{
allLeft.push_back(left);
break;
}
}
}
return allLeft;
}
std::vector<std::string> GetAllRightList(std::map<std::string, std::vector<std::string>> allRightMap,
const std::vector<std::string>& nonterminalList)
{
std::vector<std::string> allRightList;
std::set<std::string> allRightSet;
for (std::string key : nonterminalList)
{
for (std::string item : allRightMap[key])
{
allRightSet.insert(item);
}
}
SetToVector(allRightSet, allRightList);
return allRightList;
}
std::vector<std::string> GetOneCandidateAllCharacter(std::string oneCandidate)
{
std::vector<std::string> charList;
std::string oneChar;
int len = oneCandidate.length();
for (int i = 0; i < len; i++)
{
oneChar = oneCandidate.substr(i, 1);
if (i < len - 1 && oneCandidate.substr(i + 1, 1) == "'")
{
oneChar = oneCandidate.substr(i, 2);
i++;
}
charList.push_back(oneChar);
}
return charList;
}
std::vector<std::pair<std::string, std::string>> FindOneCandidateBBeta(
std::string oneCandidate,
const std::vector<std::string>& nonterminalList,
const std::vector<std::string>& oneCandidateCharList)
{
std::vector<std::pair<std::string, std::string>> oneBBeta;
int index = 0;
int charNum = oneCandidateCharList.size();
std::string beta;
std::string oneChar;
for (int i = 0; i < charNum; i++)
{
oneChar = oneCandidateCharList[i];
index += oneChar.length();
if (IsNonterminal(oneChar, nonterminalList))
{
std::string B = oneChar;
beta = oneCandidate.substr(index);
beta = beta == "" ? "$" : beta;
oneBBeta.push_back(make_pair(B, beta));
}
}
return oneBBeta;
}
std::vector<std::pair<std::string, std::string>> FindAllCandidateBBeta(
const std::vector<std::string>& allCandidateList,
const std::vector<std::string>& nonterminalList)
{
std::vector<std::pair<std::string, std::string>> allBBetaList;
std::set<std::pair<std::string, std::string>> allBBetaSet;
std::vector<std::string> oneCandidateAllCharList;
std::vector<std::pair<std::string, std::string>> oneCandidateBBetaList;
for (std::string oneCandidate : allCandidateList)
{
oneCandidateAllCharList = GetOneCandidateAllCharacter(oneCandidate);
oneCandidateBBetaList = FindOneCandidateBBeta(oneCandidate, nonterminalList, oneCandidateAllCharList);
for (std::pair<std::string, std::string> oneBBeta : oneCandidateBBetaList)
{
allBBetaSet.insert(oneBBeta);
}
}
PairSetToPairVector(allBBetaSet, allBBetaList);
return allBBetaList;
}
void Rule1(std::map<std::string, std::set<std::string>>& Follow, std::string startChar)
{
Follow[startChar].insert("#");
}
void Rule2(std::map<std::string, std::set<std::string>>& Follow,
const std::vector<std::pair<std::string, std::string>> allBBetaList,
const std::vector<std::string>& terminatorList,
std::map<std::string, std::vector<std::string>> allRightMap)
{
std::vector<std::string> FirstSetOfBeta;
for (std::pair<std::string, std::string> oneBBeta : allBBetaList)
{
FirstSetOfBeta.clear();
std::string B = oneBBeta.first;
std::string beta = oneBBeta.second;
GetOneFirst(beta, FirstSetOfBeta, terminatorList, allRightMap);
for (std::string item : FirstSetOfBeta)
{
if (item != "$")
{
Follow[B].insert(item);
}
}
}
}
void IsGeneralizedDerivation(std::string lastA,
std::pair<std::string, std::string>& oneBBeta,
std::map<std::string, std::vector<std::string>> allRightMap,
const std::vector<std::string>& terminatorList,
bool& flag,
std::set<std::string>& ASet)
{
std::string beta = oneBBeta.second;
std::string firstChar = GetFirstChar(beta);
if (IsTerminator(firstChar, terminatorList))
{
if (firstChar == "$")
{
flag = true;
ASet.insert(lastA);
}
}
else
{
for (std::string right : allRightMap[firstChar])
{
std::string newBeta = right + beta.substr(firstChar.size());
oneBBeta.second = newBeta;
lastA = firstChar;
IsGeneralizedDerivation(lastA, oneBBeta, allRightMap, terminatorList, flag, ASet);
}
}
}
bool IsRule3Over(std::map<std::string, std::set<std::string>>& thisFollow,
std::map<std::string, std::set<std::string>>& lastFollow,
const std::vector<std::string>& nonterminalList)
{
for (std::string key : nonterminalList)
{
if (thisFollow[key].size() != lastFollow[key].size())
{
return false;
}
}
return true;
}
void Rule3(std::map<std::string, std::set<std::string>>& Follow,
const std::vector<std::string>& allRightList,
const std::map<std::string, std::vector<std::string>> allRightMap,
const std::vector<std::string>& terminatorList,
const std::vector<std::string>& nonterminalList)
{
std::map<std::string, std::set<std::string>> tempFollow = Follow;
std::vector<std::string> allChar;
std::vector<std::pair<std::string, std::string>> oneCandidateBBetaList;
std::vector<std::string> oneCandidateAllLeft;
bool flag;
for (std::string oneCandidate : allRightList)
{
allChar = GetOneCandidateAllCharacter(oneCandidate);
oneCandidateBBetaList = FindOneCandidateBBeta(oneCandidate, nonterminalList, allChar);
oneCandidateAllLeft = GetOneCandidateAllLeft(oneCandidate, allRightMap);
for (std::pair<std::string, std::string> oneBBeta : oneCandidateBBetaList)
{
for (std::string left : oneCandidateAllLeft)
{
std::set<std::string> ASet;
flag = false;
std::string B = oneBBeta.first;
std::string beta = oneBBeta.second;
IsGeneralizedDerivation(left, oneBBeta, allRightMap, terminatorList, flag, ASet);
if (flag)
{
for (std::string key : ASet)
{
for (std::string item : Follow[key])
{
Follow[B].insert(item);
}
}
}
}
}
}
if (!IsRule3Over(Follow, tempFollow, nonterminalList))
{
Rule3(Follow, allRightList, allRightMap, terminatorList, nonterminalList);
}
}
int PrintFollow(std::map<std::string, std::set<std::string>>& Follow)
{
std::cout << "FOLLOW 集如下" << std::endl;
for (std::pair<std::string, std::set<std::string>> item : Follow)
{
std::cout << std::left << std::setw(3) << item.first << " : { ";
for (std::string ii : item.second)
{
std::cout << ii << ", ";
}
std::cout << "\b\b }" << std::endl;
}
std::cout << std::endl;
return 0;
}
std::map<std::string, std::set<std::string>> GetFollowSet(
const std::vector<std::string>& terminatorList,
const std::vector<std::string>& nonterminalList,
std::map<std::string, std::vector<std::string>> allRightMap,
std::string grammarStartChar)
{
std::map<std::string, std::set<std::string>> Follow;
std::vector<std::pair<std::string, std::string>> allBBeta;
std::vector<std::string> allCandidateList = GetAllLeftRightList(allRightMap);
allBBeta = FindAllCandidateBBeta(allCandidateList, nonterminalList);
Rule1(Follow, grammarStartChar);
std::cout << "规则一" << std::endl;
PrintFollow(Follow);
Rule2(Follow, allBBeta, terminatorList, allRightMap);
std::cout << "规则二" << std::endl;
PrintFollow(Follow);
Rule3(Follow, allCandidateList, allRightMap, terminatorList, nonterminalList);
std::cout << "规则三" << std::endl;
return Follow;
}
(四)构建LL(1)分析表
#pragma once
#include "MyFirst.h"
#include "MyFollow.h"
std::string GetSartCharByCandidate(std::string candidate, std::map<std::string, std::vector<std::string>> allRightMap)
{
std::string left;
for (std::pair<std::string, std::vector<std::string>> oneLeftAllRight : allRightMap)
{
left = oneLeftAllRight.first;
for (std::string oneCandidate : oneLeftAllRight.second)
{
if (oneCandidate == candidate)
{
return left;
}
}
}
std::cout << "出错了" << std::endl;
return "Error";
}
void PrintAnalysisTable(std::map<std::string, std::map<std::string, std::string>> analysisTable,
const std::vector<std::string>& terminatorList,
const std::vector<std::string>& nonterminalList)
{
std::vector<std::string> ROW = nonterminalList;
std::vector<std::string> COL = terminatorList;
for (int i = 0; i < COL.size(); i++)
{
if (COL[i] == "$")
{
COL[i] = "#";
break;
}
}
std::cout << "LL(1) 分析表如下" << std::endl;
std::string j;
std::cout << std::left << " |" << std::left << std::setw(6) << "";
for (int k = COL.size() - 1; k >= 0; k--)
{
std::cout << std::left << std::setw(10) << COL[k];
}
std::cout << std::endl;
int num = COL.size() + 1;
std::string space = "----------";
for (int i = 0; i < num; i++)
{
std::cout << std::left << std::setw(10) << space;
}
std::cout << std::endl;
for (std::string i : ROW)
{
std::cout << std::left << std::setw(5) << i << std::left << std::setw(5) << "|";
for (int k = COL.size() - 1; k >= 0; k--)
{
j = COL[k];
std::cout << std::left << std::setw(10) << analysisTable[i][j];
}
std::cout << std::endl;
}
std::cout << std::endl;
}
void ConstructorAnalysisTableByFirst(
std::map<std::string, std::map<std::string, std::string>>& analysisTable,
const std::map<std::string, std::set<std::string>>& First,
const std::map<std::string, std::vector<std::string>>& allRightMap,
const std::vector<std::string>& nonterminalList)
{
for (std::pair<std::string, std::set<std::string>> onefirstSet : First)
{
std::string oneSentence = onefirstSet.first;
if (IsNonterminal(oneSentence, nonterminalList) || oneSentence == "$")
{
continue;
}
for (std::string item : onefirstSet.second)
{
std::string left = GetSartCharByCandidate(oneSentence, allRightMap);
std::string i = left;
std::string j = item;
std::string grammar = left + "->" + oneSentence;
analysisTable[i][j] = grammar;
}
}
}
void ConstructorAnalysisTableByFollow(
std::map<std::string, std::map<std::string, std::string>>& analysisTable,
std::map<std::string, std::set<std::string>> Follow,
const std::map<std::string, std::vector<std::string>>& allRightMap,
const std::vector<std::string>& nonterminalList)
{
for (std::pair<std::string, std::vector<std::string>> oneLeftAllRight : allRightMap)
{
std::string left = oneLeftAllRight.first;
std::vector<std::string> oneAllRight = oneLeftAllRight.second;
for (std::string oneCandidate : oneAllRight)
{
if (oneCandidate == "$")
{
std::string i = left;
auto COL = Follow[left];
for (std::string j : COL)
{
std::string grammar = left + "->$";
analysisTable[i][j] = grammar;
}
}
}
}
}
void InitAnalysisTable(std::map<std::string, std::map<std::string, std::string>>& analysisTable,
const std::vector<std::string>& ROW, const std::vector<std::string>& COL)
{
for (std::string i : ROW)
{
for (std::string j : COL)
{
analysisTable[i][j] = "";
}
}
}
std::map<std::string, std::map<std::string, std::string>> AnalysisTableConstructor(
std::map<std::string, std::set<std::string>> First,
std::map<std::string, std::set<std::string>> Follow,
const std::vector<std::string>& terminatorList,
const std::vector<std::string>& nonterminalList,
std::map<std::string, std::vector<std::string>> allRightMap)
{
std::map<std::string, std::map<std::string, std::string>> analysisTable;
std::vector<std::string> ROW = nonterminalList;
std::vector<std::string> COL = terminatorList;
for (int i = 0; i < COL.size(); i++)
{
if (COL[i] == "$")
{
COL[i] = "#";
break;
}
}
InitAnalysisTable(analysisTable, ROW, COL);
ConstructorAnalysisTableByFirst(analysisTable, First, allRightMap, nonterminalList);
ConstructorAnalysisTableByFollow(analysisTable, Follow, allRightMap, nonterminalList);
return analysisTable;
}
(五)符号串分析
#pragma once
#include "AnalysisTable.h"
void MyPush(std::stack<std::string>& analysisStack, std::string string0)
{
std::vector<std::string> charList;
std::string ch;
int len = string0.length();
for (int i = 0; i < len; i++)
{
ch = string0.substr(i, 1);
if (i + 1 < len && string0.substr(i + 1, 1) == "'")
{
ch = string0.substr(i, 2);
i++;
}
charList.push_back(ch);
}
for (int i = charList.size() - 1; i >= 0; i--)
{
analysisStack.push(charList[i]);
}
}
std::string GetAnalysisByStack(const std::stack<std::string>& analysisStack)
{
std::stack<std::string> tempAnalysisStack = analysisStack;
std::vector<std::string> charList;
std::string string0;
int size = tempAnalysisStack.size();
for (int i = 0; i < size; i++)
{
charList.push_back(tempAnalysisStack.top());
tempAnalysisStack.pop();
}
for (int i = charList.size() - 1; i >= 0; i--)
{
string0 += charList[i];
}
return string0;
}
std::string GetStringByStack(const std::stack<std::string>& stringStack)
{
std::stack<std::string> tempStringStack = stringStack;
std::string string0;
int size = tempStringStack.size();
for (int i = 0; i < size; i++)
{
string0 += tempStringStack.top();
tempStringStack.pop();
}
return string0;
}
void PrintStack(const std::stack<std::string>& analysisStack)
{
std::stack<std::string> tempStack = analysisStack;
while (tempStack.size() != 0)
{
std::string ch = tempStack.top();
tempStack.pop();
std::cout << ch << std::endl;
}
}
void InitStringStack(std::stack<std::string>& stringStack, std::string string0)
{
stringStack.push("#");
MyPush(stringStack, string0);
}
void InitAnalysisStack(std::stack<std::string>& analysisStack, std::string startChar)
{
analysisStack.push("#");
analysisStack.push(startChar);
}
std::string GetGrammar(std::string analysisTop, std::string stringTop, std::map<std::string, std::map<std::string, std::string>> analysisTable)
{
return analysisTable[analysisTop][stringTop];
}
void PrintAllStep(const std::vector<std::vector<std::string>>& allStep, std::string string0)
{
std::cout << "符号串 " << string0 << " 的分析过程" << std::endl;
for (std::vector<std::string> oneStep : allStep)
{
std::cout << std::left << std::setw(6) << oneStep[0]
<< std::left << std::setw(10) << oneStep[1]
<< std::right << std::setw(10) << oneStep[2] << " "
<< std::left << std::setw(10) << oneStep[3]
<< std::endl;
}
}
std::string GetRight(std::string oneGrammar)
{
std::string firstChar = GetFirstChar(oneGrammar);
std::string right;
if (oneGrammar.substr(firstChar.length(), 3) == "::=")
{
right = oneGrammar.substr(firstChar.length() + 3);
return right;
}
else if (oneGrammar.substr(firstChar.length(), 2) == "->")
{
right = oneGrammar.substr(firstChar.length() + 2);
return right;
}
else
{
std::cout << "right 出错了" << std::endl;
return "";
}
}
std::vector<std::vector<std::string>> Func(std::stack<std::string>& analysisStack, std::stack<std::string>& stringStack, std::map<std::string, std::map<std::string, std::string>> analysisTable, int& step)
{
std::string analysisTop;
std::string stringTop;
std::string oneGrammar;
std::string right;
bool sucess = true;
std::vector<std::vector<std::string>> allStep;
std::vector<std::string> oneStep;
std::string analysisStackList;
std::string stringStackList;
while (!(analysisStack.top() == "#" && stringStack.top() == "#") || step >= 100)
{
step++;
oneStep.clear();
oneStep.push_back(std::to_string(step));
analysisStackList = GetAnalysisByStack(analysisStack);
stringStackList = GetStringByStack(stringStack);
oneStep.push_back(analysisStackList);
oneStep.push_back(stringStackList);
analysisTop = analysisStack.top();
stringTop = stringStack.top();
if (analysisTop == stringTop)
{
oneStep.push_back("");
allStep.push_back(oneStep);
analysisStack.pop();
stringStack.pop();
continue;
}
oneGrammar = GetGrammar(analysisTop, stringTop, analysisTable);
oneStep.push_back(oneGrammar);
allStep.push_back(oneStep);
if (oneGrammar == "")
{
sucess = false;
break;
}
right = GetRight(oneGrammar);
analysisStack.pop();
if (right != "$")
{
MyPush(analysisStack, right);
}
}
std::vector<std::string> successStep = {
std::to_string(++step), "#", "#", "SUCCESS" };
std::vector<std::string> failStep = {
std::to_string(++step), "?", "?", "FAIL" };
allStep.push_back(sucess ? successStep : failStep);
return allStep;
}
std::vector<std::vector<std::string>> StringAnalysis(std::string string0,
std::string startChar, std::map<std::string, std::map<std::string,
std::string>> analysisTable)
{
std::stack<std::string> analysisStack;
std::stack<std::string> stringStack;
InitAnalysisStack(analysisStack, startChar);
InitStringStack(stringStack, string0);
int step = 0;
std::vector<std::vector<std::string>> allStep = Func(analysisStack, stringStack, analysisTable, step);
return allStep;
}
(六)主函数
#include "EliminateLeftRecursion.h"
#include "MyFirst.h"
#include "MyFollow.h"
#include "AnalysisTable.h"
#include "StringAnalysis.h"
int main()
{
std::vector<std::string> grammarList;
std::vector<std::string> terminatorList;
std::vector<std::string> nonterminalList;
ReadGrammerFile(grammarList, "code.txt");
std::cout << "原始文法如下" << std::endl;
PrintGrammerList(grammarList);
GetTerminator_Nonterminal(grammarList, terminatorList, nonterminalList);
EliminateLeftRecursion(nonterminalList, grammarList);
std::cout << "消除左递归文法如下" << std::endl;
PrintGrammerList(grammarList);
std::map<std::string, std::set<std::string>> First;
std::map<std::string, std::vector<std::string>> allRightMap;
GetTerminator_Nonterminal(grammarList, terminatorList, nonterminalList);
GetAllRightMap(allRightMap, grammarList);
First = GetFirstSet(terminatorList, nonterminalList, allRightMap);
PrintFirst(First);
std::string grammarStartChar = GetFirstChar(grammarList[0]);
std::map<std::string, std::set<std::string>> Follow;
Follow = GetFollowSet(terminatorList, nonterminalList, allRightMap, grammarStartChar);
PrintFollow(Follow);
std::map<std::string, std::map<std::string, std::string>> analysisTable;
analysisTable = AnalysisTableConstructor(First, Follow, terminatorList, nonterminalList, allRightMap);
PrintAnalysisTable(analysisTable, terminatorList, nonterminalList);
std::string string0 = "i+i*i";
auto allStep = StringAnalysis(string0, grammarStartChar, analysisTable);
PrintAllStep(allStep, string0);
return 0;
}
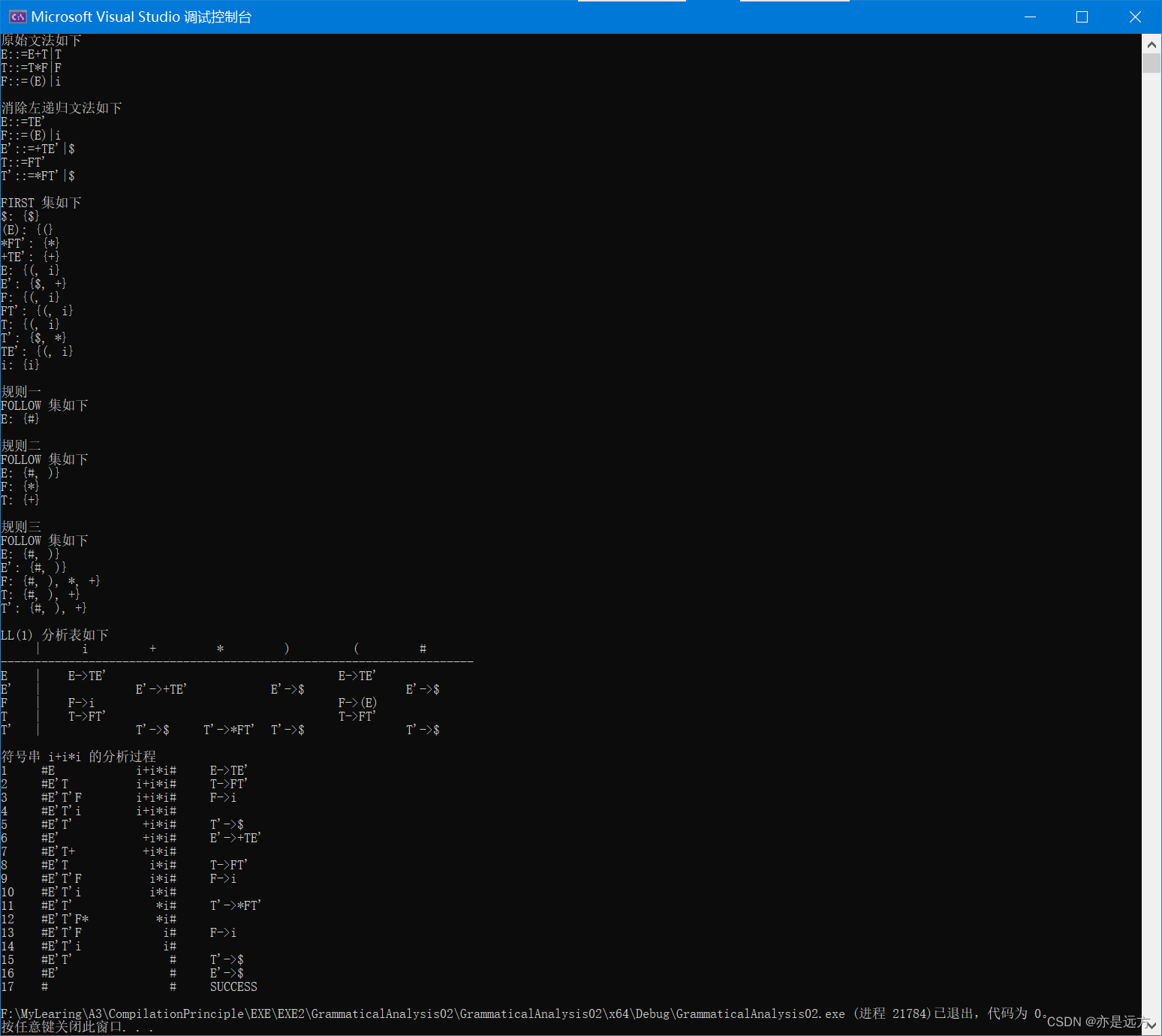
三、实验结果
原始文法如下
E::=E+T|T
T::=T*F|F
F::=(E)|i
消除左递归文法如下
E::=TE'
F::=(E)|i
E'::=+TE'|$
T::=FT'
T'::=*FT'|$
FIRST 集如下
$: {
$}
(E): {
(}
*FT': {
*}
+TE': {
+}
E: {
(, i}
E': {
$, +}
F: {
(, i}
FT': {
(, i}
T: {
(, i}
T': {
$, *}
TE': {
(, i}
i: {
i}
规则一
FOLLOW 集如下
E: {
#}
规则二
FOLLOW 集如下
E: {
#, )}
F: {
*}
T: {
+}
规则三
FOLLOW 集如下
E: {
#, )}
E': {
#, )}
F: {
#, ), *, +}
T: {
#, ), +}
T': {
#, ), +}
LL(1) 分析表如下
| i + * ) ( #
----------------------------------------------------------------------
E | E->TE' E->TE'
E' | E'->+TE' E'->$ E'->$
F | F->i F->(E)
T | T->FT' T->FT'
T' | T'->$ T'->*FT' T'->$ T'->$
符号串 i+i*i 的分析过程
1 #E i+i*i# E->TE'
2 #E'T i+i*i# T->FT'
3 #E'T'F i+i*i# F->i
4 #E'T'i i+i*i#
5 #E'T' +i*i# T'->$
6 #E' +i*i# E'->+TE'
7 #E'T+ +i*i#
8 #E'T i*i# T->FT'
9 #E'T'F i*i# F->i
10 #E'T'i i*i#
11 #E'T' *i# T'->*FT'
12 #E'T'F* *i#
13 #E'T'F i# F->i
14 #E'T'i i#
15 #E'T' # T'->$
16 #E' # E'->$
17 # # SUCCESS
四、视频讲解
B站详细讲解
五、全部源代码
点我查看全部源代码