链接:https://arxiv.org/abs/2012.15688
github:https://github.com/PaddlePaddle/ERNIE/tree/repro/ernie-doc
Abstract
Transformers由于内存和时间的二次增长,从而不适用于长文本。简单的长文本截断或者稀疏自注意力机制将会导致其他的问题。ERNIE-DOC是基于Recurrence Transformers的长文本的预训练模型。其中主要的设计技术是:retrospective feed mechanism和recurrence mechanism。
Introduction
在问答,文本分类任务上,Transformers已经取得了很好的表现。Transformers由于自注意力机制,使得网络能够从文本中捕获上下文的信息。自注意力机制的内存消耗和计算复杂度导致了额外的代价。当前的bert主要使用固定512长度的token,所以长文本必须进行切割,然后由于片段之间没有交互,导致上下文信息的丢失(图1a),Recurrence Transformers(图1b)通过memory的机制来实现上下文的交互。现有的解决策略都不能为每个片段提供完整的上下文信息。

人阅读长文本先略读然后精读,受此启发,ERNIE-DOC设计了retrospective feed mechanism,也就是一个片段是被输入两次的,避免了信息的碎片化。retrospective feed mechanism受限于层数而使得上下文长度仍然受到限制,因此提出了enhanced recurrence mechanism(增强循环机制)。
此外,本文引入了片段顺序预测的任务,从而构建了片段之间的关系。
Method
长文本 划分为
,其中
是有L个tokens的第t个片段。Vanilla, Sparse, and Recurrence Transformers的对于片段
的 隐藏层
:
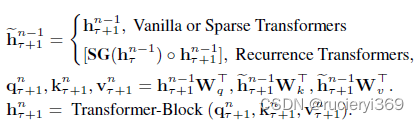
表示不进行梯度操作。
Vanilla or Sparse Transformers的 仅仅是利用自己的信息产生的;Recurrence Transformers进行了片段之间的交互,但是对于每一个片段,整个文档的上下文信息并不能够获取。

-
Retrospective Feed Mechanism
retrospective feed mechanism模仿了人类的第一遍略读和第二遍精读,在略读阶段,利用循环机制为每一个片段缓存隐藏状态,在精读阶段,重新使用了隐藏状态值。方程1可重写成:

表示
个片段在略读阶缓存的隐藏状态,
是每个片段的长度,
是层数;
捕获了整个文档的双向上下文信息,但是又会导致内存和计算代价。为了处理这个问题,
将每
步取每个片段隐藏层的状态 :
![]()
Enhanced Recurrence Mechanism
一种增强循环机制,当前片段的当前层的隐藏状态和上一个片段的下层的隐层状态:
![]()
以上的操作构建了更长的上下文长度。
Experiments
word-level LM

long-text classification

Conclusion
ERNIE-DOC是一个文档级别的预训练模型,可以处理更长的文本。各种实验证明了ERNIE-DOC优于现有的各种预训练模型。