头插法
核心代码:
head->next = NULL;
s->next = head->next;
head->next = s;
单个结点

原始状态

第一个元素插入的过程(注意:1和2的顺序不能颠倒,不然会导致链表缺失)

第一个元素插入后

第二个元素插入的过程(其余元素插入的过程也类似)
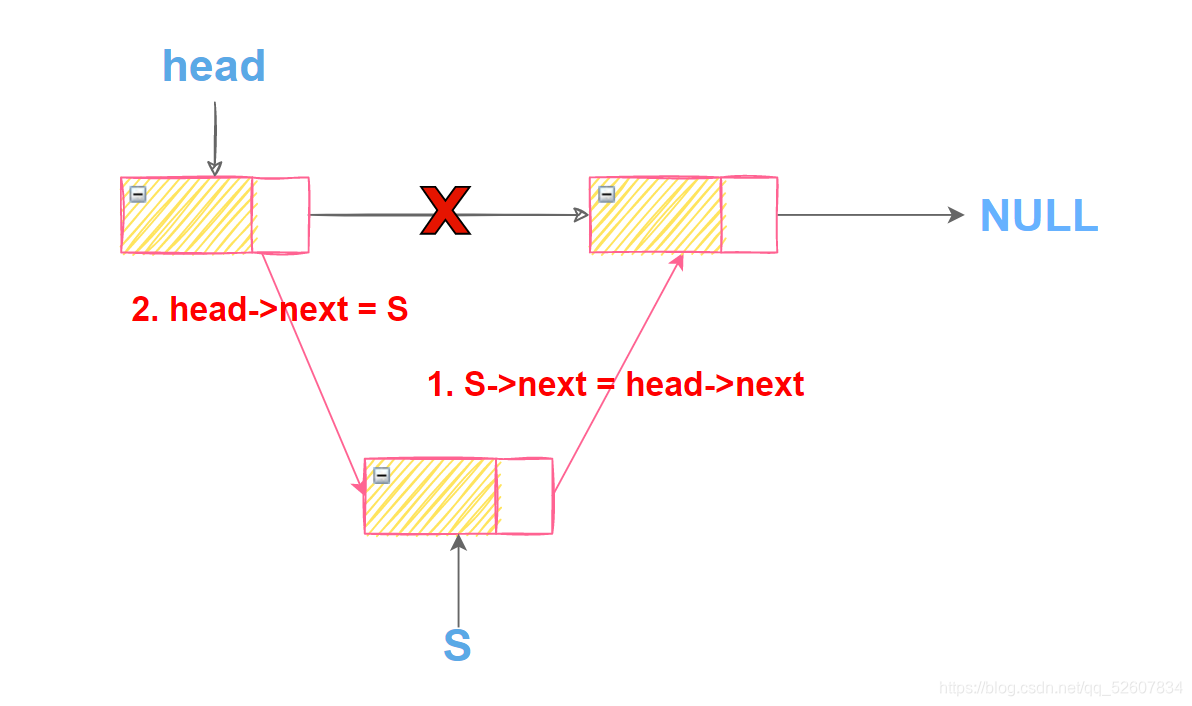
第二个元素插入后

尾插法
核心代码:
tail = head;
s->next = NULL;
tail->next = s;
tail = s;
原始状态

第一个元素插入的过程(注意:2和3的顺序不能颠倒,不然会导致链表的生成出错)

第一个元素插入后

第二个元素插入的过程(其余元素插入的过程也类似)
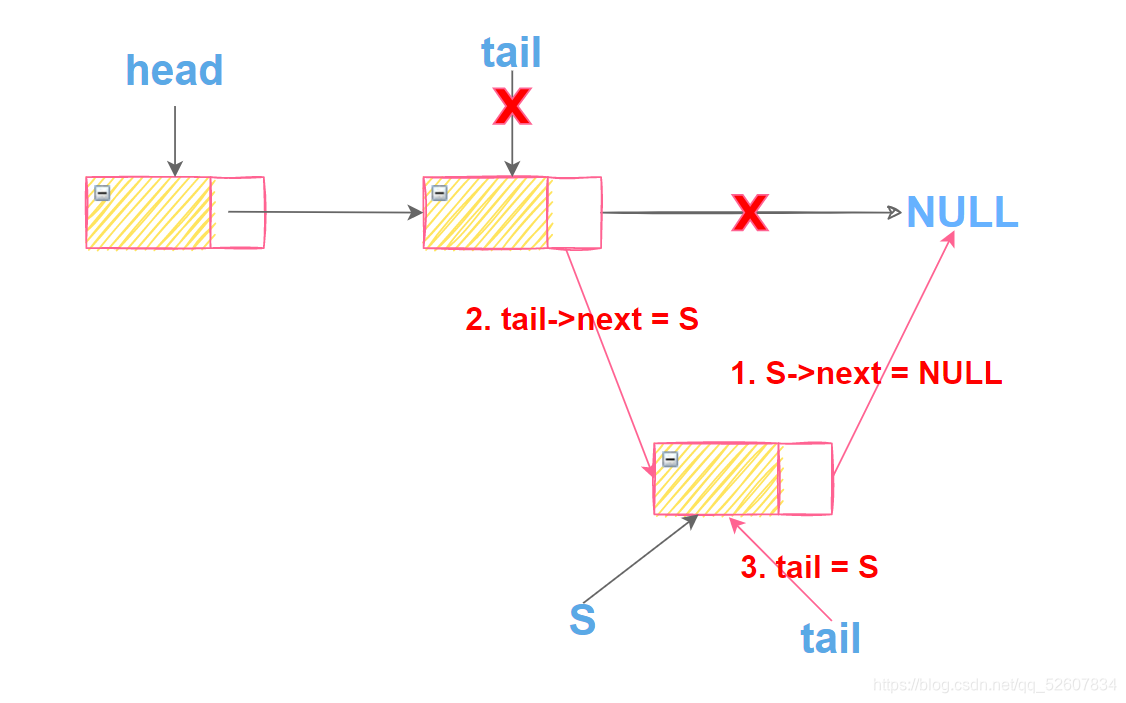
第二个元素插入后

头插法和尾插法的对比
头插法建立链表的算法简短易懂,但是生成链表的结点顺序与原来输入的顺序相反,而用尾插法建立链表可使输入和生成的结点顺序相同
为什么会这样呢?
根据上面的头插法和尾插法的算法,我们很容易知道,当用头插法依次插入值分别为1,2,3,4,5的结点(也叫做元素)后,单链表会如下图所示:

但是用尾插法同样插入值分别为1,2,3,4,5的结点后,单链表却会如下图所示:

而在这两个链表中,输出链表中各个元素的值只能从已知的头结点head开始遍历,所以分别用头插法和尾插法创建链表后,依次输出的元素的值刚好是相反的
验证小例子:
#include <stdio.h>
#include <malloc.h>
typedef struct node
{
struct node* next;
int data;
}LinkList;
//定义LinkList为struct node类型,即struct node可直接用LinkList来表示,方便定义
//头插法创建单链表
int main (void)
{
int i, len = 5;
//len表示链表的长度
LinkList* head, * s;
//head为LinkList*类型的指针变量,表示头指针
head = (LinkList*)malloc (sizeof (LinkList));
//malloc (sizeof (LinkList))意思是让系统分配内存大小为sizeof (LinkList)的空间
head->next = NULL;
//令头指针的所指向结点的指针域为空
for (i = 0; i < len; i++)
{
s = (LinkList*)malloc (sizeof (LinkList));
printf ("请输入该元素的值:");
scanf ("%d", &s->data);
s->next = head->next;
head->next = s;
}
//以下代码是为了将单链表中各个元素的值依次打印出来
LinkList* q;
q = (LinkList*)malloc (sizeof (LinkList));
q = head->next;
while (q != NULL)
{
printf ("%d", q->data);
q = q->next;
}
return 0;
}
结果:
请输入该元素的值:1
请输入该元素的值:2
请输入该元素的值:3
请输入该元素的值:4
请输入该元素的值:5
54321
#include <stdio.h>
#include <malloc.h>
typedef struct node
{
struct node* next;
int data;
}LinkList;
//尾插法创建单链表
int main (void)
{
int i, len = 5;
LinkList* head,* s,* tail;
//tail表示尾指针
head = (LinkList*)malloc (sizeof (LinkList));
tail = head;
for (i = 0; i < len; i++)
{
s = (LinkList*)malloc (sizeof (LinkList));
printf ("请输入该元素的值:");
scanf ("%d", &s->data);
s->next = NULL;
tail->next = s;
tail = s;
}
//以下代码是将单链表中各个元素的值依次打印出来
LinkList* q;
q = head->next;
while (q != NULL)
{
printf ("%d", q->data);
q = q->next;
}
return 0;
}
结果:
请输入该元素的值:1
请输入该元素的值:2
请输入该元素的值:3
请输入该元素的值:4
请输入该元素的值:5
12345