场景预设和一般hash算法:
先预设一个场景,有10000份文件,需要缓存到五台缓存服务器之上
那么按照最常规,每个服务器平均分配2000份文件
那么用一个取余操作就可以完成
比如说是第2513的图片,那么用一个公式
需要缓存的文件数%服务器数量就可以得到文件需要存在几号服务器上
2513%5=3,那么低2513号文件就可以缓存到3号服务器上面
一般hash算法的缺陷:
当缓存服务器数量需要增加或者减少的时候,这时候取模数发生了变化,文件取hash后不是原来的服务器,造成缓存失效,失效后就需要从后台服务器去取到指定的文件
举个例子,当一台服务器故障的时候,会造成缓存雪崩,后端服务器突然出现了巨大的压力,整个系统就会被压垮,于是就需要一致性哈希算法1去解决这个问题
一致性哈希算法:
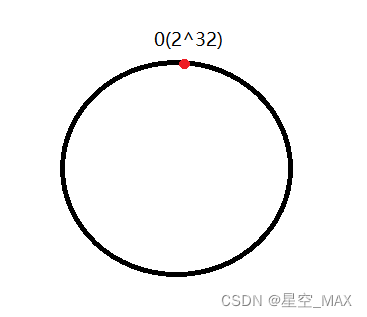
先假设一个哈希环,由2^32个点组成
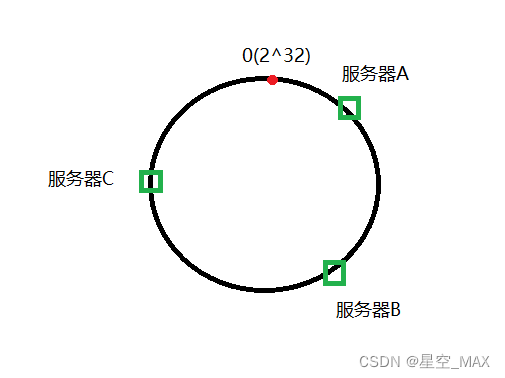
在节点之间分配三个服务器
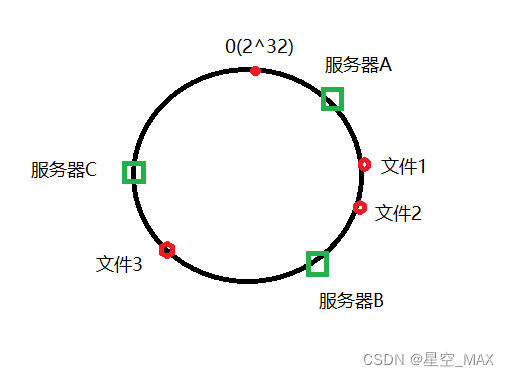
用公式文件 % 2^32,得到文件1和文件2在服务器A和服务器B节点之间
那么顺时针旋转,找到一个服务器节点,找到服务器B,那么服务器B就作为存储节点
同理文件3找到服务器C作为存储节点
这时候服务器C挂掉了,那么就会顺时针找到服务器A作为存储节点
文件1和文件2依旧在服务器B上面
位置没有发生改变,这就是哈希一致性算法的区别
哈希环倾斜:
未倾斜的情况:

发生倾斜的情况:
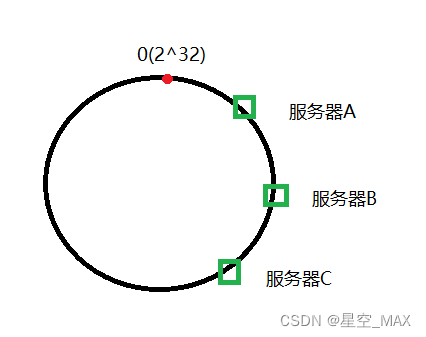
这时候大量的文件会缓存到服务器A,A的压力巨大,这时候就需要虚拟节点:
虚拟节点:
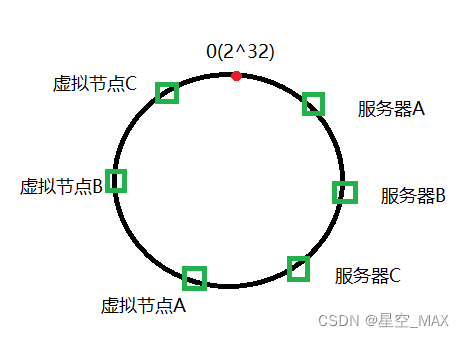
在哈希环上面再分配虚拟节点,比如算到虚拟节点A的也会交给服务器A缓存,这样就可以实现相对平均的分配