简介
首先我们需要知道什么是哈希,哈希一般都是将一个大数字取模然后分散到不同的容器里面,在一个分布式的服务器系统之中,通常会使用哈希的算法来处理服务器的负载均衡问题,每一个服务器就是一个容器,我们把数据按照哈希算法分布在不同的服务器,这样就可以减小服务器的负载,提高服务器的处理能力。
一致性哈希和普通哈希
那么,一致性哈希和普通哈希有什么区别呢?其实一般的哈希都是不一致的。例如这里有6个数字,123456,把它们分别对2取模,然后按照结果分布在两个哈希桶里面,
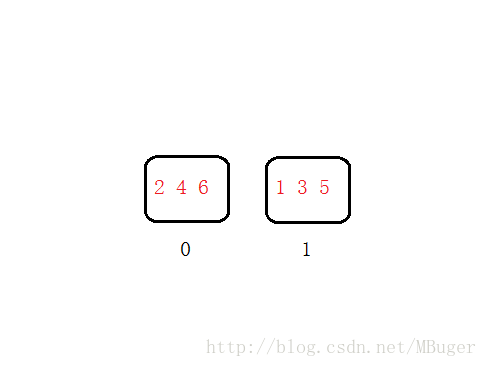
之后我们觉得这样每个桶里的数据太多了,想要再加一个桶(即服务器需要分流负载了),此时我们加一个桶则需要对数据重新进行分配,让数据对3取模再分配到对应的桶,
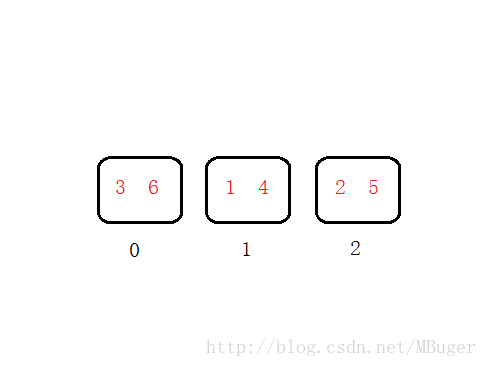
这就是普通的哈希算法,很明显在进行哈希表扩容的时候,所有的数据都会进行重新的分配。分布式的存储系统中,每个桶就相当于一个机器,文件分布在哪台机器由哈希算法来决定,这个系统想要加一台机器时就需要停下来等所有文件重新分布一次才能对外提供服务,而当一台机器掉线的时候尽管只掉了一部分数据,但所有数据访问路由都会出问题。这样整个服务就无法平滑的扩缩容。一致性的意思也就是说局部增减容器的数量 不会对全局造成影响。
要实现平滑的扩容和缩容我们则需要使用一致性哈希算法,一致性哈希中我们假定有很多桶,比如这里我们假设有7个桶,哈希算法还是同样的取模,只不过现在分桶分到的很可能是不存在的桶,那么就往下找找到第一个真实存在的桶放进去,如图所示
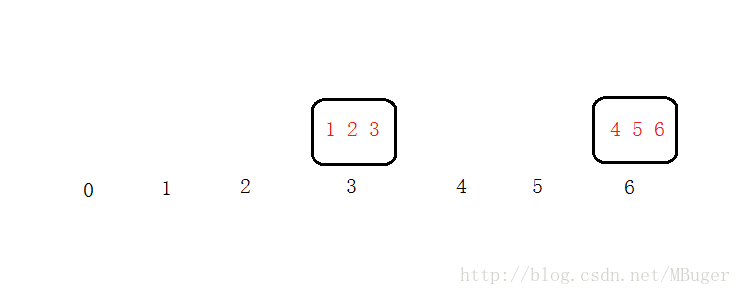
此时我们再需要加一个桶4,按照取模的算法,3号桶内的数据都是小于等于三的,所以我们只需要从桶6拉取数字符合4号位置的数字到4号桶内就可以了,
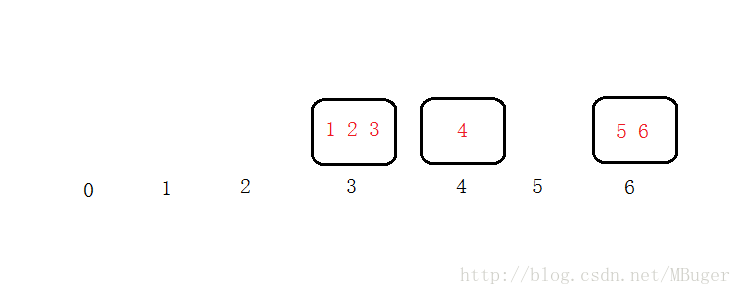
这样不论有多少个桶,每次再增加桶的时候只会影响一个桶的数据分布。这样增加一个服务器只需要和他后面的机器同步一下数据就可以开始工作了,下线一个机器需要先把他的数据同步到后面一台机器再下线。如果突然掉了一台机器也只会影响这台机器上的数据。实现中可以让每台机器同步一份自己前面机器的数据,这样即使掉线也不会影响这一部分的数据服务。
新的问题
当然,新的处理方案也会带来新的问题,那就是当服务器中最尾一个服务器下线的时候,它的数据应该交给谁了负担呢,因为它是最末尾一个,所以没有办法把它的数据托管给下一个服务器。所以往往分布式的服务器设计会是环形的,当最尾的服务器挂掉,他会接着把数据托管给前面的服务器。这也就形成了一致性哈希的基本结构。
