1 、用户在客户端执行 SQL 语句时,客户端把这条 SQL 语句发送给服务端,服务端的进程,会处理这条客户端的SQL语句。
2 、服务端进程收集到SQL信息后,会在进程全局区PGA 中分配所需内存,存储相关的登录信息等。
3 、客户端把 SQL 语句传送到服务器后,服务器进程会对该语句进行解析。这个解析的工作是在服务器端所进行的,解析过程又可细化。
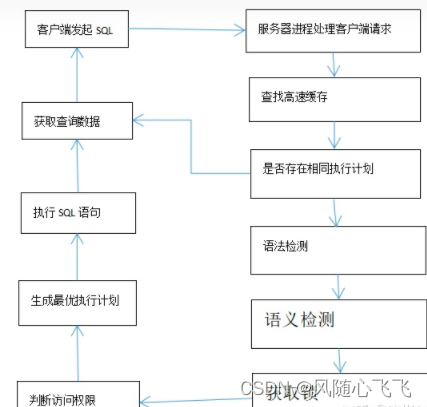
(1 )查询高速缓存
服务器进程在接到客户端传送过来的 SQL 语句时,不会直接去数据库查询。服务器进程把这个 SQL 语句的字符转化为 ASCII 等效数字码,接着这个 ASCII 码被传递给一个 HASH 函数,并返回一个 hash 值,然后服务器进程将到 共享池shared pool 中的 高速缓存中去查找是否存在相同的 hash 值。如果存在,服务器进程将使用这条语句已高速缓存在 共享池shared pool 的 高速缓存中的已分析过的版本来执行,这就是是软解析。如果高速缓存中不存在,则需要进行上图后面的步骤,这就是硬解析。硬解析通常占整个 SQL 执行的 60% 左右的时间,硬解析会生成执行树,执行计划,等等。所以,采用高速数据缓存可以提高 SQL 语句的查询效率。主要是因为:一方面是从内存中读取数据要比从硬盘中的数据文件中读取数据效率要高很多,另一方面也是因为避免语句解析而节省大量时间。
(2)语法检查
当在高速缓存中找不到对应的 SQL 语句时,则服务器进程就会开始检查这条语句的合法性。这里主要是对 SQL 语句的语法进行检查,看看其是否合乎语法规则。如果服务器进程认为这条 SQL 语句不符合语法规则的时候,就会把这个错误信息反馈给客户端。在这个语法检查的过程中,不会对 SQL 语句中所包含的表名、列名等等进行检查,只是检查语法。
(3)语义检查
如果SQL 语句符合语法上的定义的话,则服务器进程接下去会对语句中涉及的表、索引、视图等对象进行解析,并对照数据字典检查这些对象的名称以及相关结构,看看这些字段、表、视图等是否在数据库中。如果表名与列名不准确的话,则数据库会就会反馈错误信息给客户端。
(4)获得对象解析锁
为了保证数据的一致性,防止我们在查询的过程中,其他用户修改这个对象。系统就会对我们需要查询的对象加锁。
(5)数据访问权限确认
当语法、语义通过检查之后,客户端还不一定能够取得数据,服务器进程还会检查连接用户是否有这个数据访问的权限。若用户不具有数据访问权限的话,则客户端就不能够取得这些数据。要注意的是数据库服务器进程先检查语法与语义,然后才会检查访问权限。
(6)生成最优执行计划
当语法、语义、权限检测等都通过,服务器进程会根据一定的规则(如基于成本),对这条语句进行优化。最终确定可能的最低成本的执行计划。
4 、绑定变量赋值
如果 SQL 语句中使用了绑定变量,扫描绑定变量的声明,给绑定变量赋值,将变量值带入执行计划。
5 、语句执行
语句解析只是对 SQL 语句的语法进行解析,以确保服务器能够知道这条语句到底表达的是什么意思。等到语句解析完成之后,数据库服务器进程才会真正的执行这条 SQL 语句。
(1)对于 SELECT 语句:
第一、首先服务器进程要判断所需数据是否在 db buffer 存在,如果存在且可用,则直接获取
第二、若数据不在缓冲区中,则服务器进程将从数据库文件中查询相关数据,并把这些数据放入到数据缓冲区中( buffer cache )。
(2)对于 insert 、 delete 、 update 语句:
第一、检查所需的数据是否已经被读取到缓冲区缓存中。如果已经存在缓冲区缓存,则直接执行步骤
A 若所需的数据并不在缓冲区缓存中,则服务器将数据块从数据文件读取到缓冲区缓存中;
B 对想要修改的表取得的数据行锁定,之后对所需要修改的数据行取得独占锁;
C 将数据的 Redo 记录复制到 redo log buffer ;
D 产生数据修改的 undo 数据;
E 修改 db buffer ;
F dbwr 将修改写入数据文件;
第二、服务器将数据从数据文件读取到 db buffer 要通过以下步骤:
A 首先服务器进程将在表头部请求 TM 锁(保证此事务执行过程其他用户不能修改表的结构),如果成功加 TM 锁,再请求一些行级锁( TX 锁),如果 TM 、 TX 锁都成功加锁,那么才开始从数据文件读数据。
B 在读数据之前,要先为读取的文件准备好 buffer 空间。服务器进程需要扫描 LRU list 寻找 free db buffer ,扫描的过程中,服务器进程会把发现的所有已经被修改过的 db buffer 注册到 dirty list 中。如果 free db buffer 及非脏数据块缓冲区不足时,会触发 dbwr 将 dirty buffer 中指向的缓冲块写入数据文件,并且清洗掉这些缓冲区来腾出空间缓冲新读入的数据。
C 找到了足够的空闲 buffer ,服务器进程将从数据文件中读入这些行所在的每一个数据块( db block )( DB BLOCK 是 ORACLE 的最小操作单元,即使你想要的数据只是 DB BLOCK 中很多行中的一行或几行, ORACLE 也会把这个 DB BLOCK 中的所有行都读入 Oracle DB BUFFER 中)放入 db buffer 的空闲的区域或者覆盖已被挤出 LRU list 的非脏数据块缓冲区,并且排列在 LRU 列表的头部,也就是在数据块放入 db buffer 之前也是要先申请 db buffer 中的锁存器,成功加锁后,才能读数据到 db buffer 。若数据块已经存在于 db buffer cache (有时也称 db buffer 或 db cache ),即使在 db buffer 中找到一个没有事务,而且 SCN 比自己小的非脏缓存数据块,服务器进程仍然要到表的头部对这条记录申请加锁,加锁成功才能进行后续动作,如果不成功,则要等待前面的进程解锁后才能进行动作(这个时候阻塞是 tx 锁阻塞)。
第三、记录 redo 日志
A 数据被读入到 db buffer 后,服务器进程将该语句所影响的并被读入 db buffer 中的这些行数据的 rowid 及要更新的原值和新值及 scn 等信息从 PGA 逐条的写入 redo log buffer 中。在写入 redo log buffer 之前也要事先请求 redo log buffer 的锁存器,成功加锁后才开始写入。
B 当写入达到 redo log buffer 大小的三分之一或写入量达到 1M 或超过三秒后或发生检查点时或者 dbwr 之前发生,都会触发 lgwr 进程把 redo log buffer 的数据写入磁盘上的 redo file 文件中(这个时候会产生 log file sync 等待事件)。
C 已经被写入 redo file 的 redo log buffer 所持有的锁存器会被释放,并可被后来的写入信息覆盖, redo log buffer 是循环使用的。 Redo file 也是循环使用的,当一个 redo file 写满后, lgwr 进程会自动切换到下一 redo file (这个时候可能出现 log file switch ( check point complete )等待事件)。如果是归档模式,归档进程还要将前一个写满的 redo file 文件的内容写到归档日志文件中(这个时候可能出现 log file switch ( archiving needed )。
第四、为事务建立 undo 信息
A 在完成本事务所有相关的 redo log buffer 之后,服务器进程开始改写这个 db buffer 的块头部事务列表并写入 scn (一开始 scn 是写在 redo log buffer 中的,并未写在 db buffer )。
B 然后 copy 包含这个块的头部事务列表及 scn 信息的数据副本放入回滚段中,将这时回滚段中的信息称为数据块的“前映像”,这个“前映像”用于以后的回滚、恢复和一致性读。(回滚段可以存储在专门的回滚表空间中,这个表空间由一个或多个物理文件组成,并专用于回滚表空间,回滚段也可在其它表空间中的数据文件中开辟)。
第五|、修改信息写入数据文件
A 改写 db buffer 块的数据内容,并在块的头部写入回滚段的地址。
B 将 db buffer 指针放入 dirty list 。如果一个行数据多次 update 而未 commit ,则在回滚段中将会有多个“前映像”,除了第一个“前映像”含有 scn 信息外,其他每个 " 前映像 " 的头部都有 scn 信息和 " 前前映像 " 回滚段地址。一个 update 只对应一个 scn ,然后服务器进程将在 dirty list 中建立一条指向此 db buffer 块的指针(方便 dbwr 进程可以找到 dirty list 的 db buffer 数据块并写入数据文件中)。接着服务器进程会从数据文件中继续读入第二个数据块,重复前一数据块的动作,数据块的读入、记日志、建立回滚段、修改数据块、放入 dirty list 。
C 当 dirty queue 的长度达到阀值(一般是 25% ),服务器进程将通知 dbwr 把脏数据写出,就是释放 db buffer 上的锁存器,腾出更多的 free db buffer 。前面一直都是在说明 oracle 一次读一个数据块,其实 oracle 可以一次读入多个数据块( db_file_multiblock_read_count 来设置一次读入块的个数)
第六、当执行 commit
1 ) commit 触发 lgwr 进程,但不强制 dbwr 立即释放所有相应 db buffer 块的锁。也就是说有可能虽然已经 commit 了,但在随后的一段时间内 dbwr 还在写这条 sql 语句所涉及的数据块。表头部的行锁并不在 commit 之后立即释放,而是要等 dbwr 进程完成之后才释放,这就可能会出现一个用户请求另一用户已经 commit 的资源不成功的现象。
2 )从 Commit 和 dbwr 进程结束之间的时间很短,如果恰巧在 commit 之后, dbwr 未结束之前断电,因为 commit 之后的数据已经属于数据文件的内容,但这部分文件没有完全写入到数据文件中。所以需要前滚。由于 commit 已经触发 lgwr ,这些所有未来得及写入数据文件的更改会在实例重启后,由 smon 进程根据重做日志文件来前滚,完成之前 commit 未完成的工作(即把更改写入数据文件)。
3 )如果未 commit 就断电了,因为数据已经在 db buffer 更改了,没有 commit ,说明这部分数据不属于数据文件。由于 dbwr 之前触发 lgwr 也就是只要数据更改,(肯定要先有 log )所有 dbwr 在数据文件上的修改都会被先一步记入重做日志文件,实例重启后, SMON 进程再根据重做日志文件来回滚。
其实 smon 的前滚回滚是根据检查点来完成的,当一个全部检查点发生的时候,首先让 LGWR 进程将 redologbuffer 中的所有缓冲(包含未提交的重做信息)写入重做日志文件,然后让 dbwr 进程将 dbbuffer 已提交的缓冲写入数据文件(不强制写未提交的)。然后更新控制文件和数据文件头部的 SCN ,表明当前数据库是一致的,在相邻的两个检查点之间有很多事务,有提交和未提交的。
第七、如果执行 rollback
服务器进程会根据数据文件块和 db buffer 中块的头部的事务列表和 SCN 以及回滚段地址找到回滚段中相应的修改前的副本,并且用这些原值来还原当前数据文件中已修改但未提交的改变。如果有多个”前映像“,服务器进程会在一个“前映像”的头部找到“前前映像”的回滚段地址,一直找到同一事务下的最早的一个“前映像”为止。一旦发出了 commit ,用户就不能 rollback ,这使得 commit 后 dbwr 进程还没有全部完成的后续动作得到了保障。