
Title: STU-Net: Scalable and Transferable Medical Image Segmentation Models Empowered by Large-Scale Supervised Pre-training
Paper: https://arxiv.org/pdf/2304.06716.pdf
Code: https://github.com/Ziyan-Huang/STU-Net
导读
医学图像分割领域的深度学习模型,分为基于 CNN 和 Transformer 两种类型。其中,U-Net 是医学图像分割的先驱 CNN 模型,后续的研究则在此基础上应用残差连接、注意力机制和不同的特征聚合策略等方法。最近,视觉 Transformer 模型被引入到医学图像分割中,例如使用 UNER 和 SwinUNETR 模型分别采用 Transformer 和 Swin Transformer 作为编码器提取特征。
然而,现有的这些模型不能够适应不同的计算资源和处理不同的医学图像分割任务。此外,虽然大型深度学习模型已经在许多应用领域中表现出非常好的性能,但在医学图像分割领域,最先进的模型仍然非常小,参数数量仅有几千万。
因此,本文提出了一种可扩展和可转移模型 STU-Net,并探讨了在大规模医学图像分割数据集上训练大型深度学习模型的可能性。
创作背景
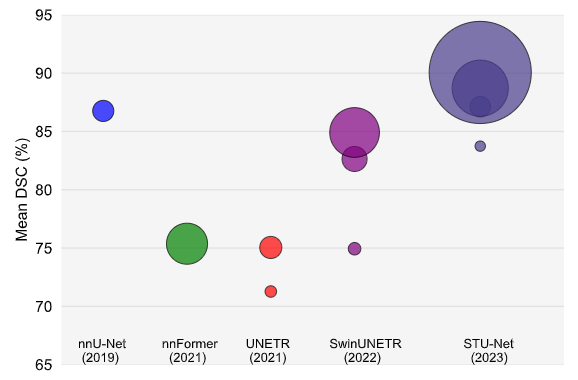
医学图像分割是自动标注医学图像中的解剖结构和病变的重要中间步骤,是许多下游临床任务的关键。近年来,各种特定的医学图像分割任务得到了广泛研究,许多基于深度学习的模型取得了巨大的成功。
然而,这些模型通常需要仔细调整以适应不同的任务,这极大地限制了它们的可转移性。因此,需要一种能够同时处理各种医学分割任务的单一模型,包括不同的输入模态(CT、MRI、PET)和不同的分割目标,例如器官和肿瘤。解决这个问题的关键是在大规模数据集上预训练大模型,以使模型具有可转移性。 从数据集的角度来看,一些公共的大规模医学图像分割数据集正在出现。
此外,大模型通常需要更多的计算成本,特别是当使用三维高分辨率医学图像进行训练时,这一问题会更加严重。因此,本文提出希望这个大模型能够可扩展到不同的尺寸以适应不同的计算预算。
为了实现这一目标,本文提出了一系列可扩展和可转移的 U-Net 模型,称为 STU-Net,其参数大小范围从 1400 万到 14 亿不等。此外,为了确保模型的转移能力,我们使用监督学习的方式在大规模数据集上预训练这些模型。
本文基于 nnU-Net 框架构建了这些模型,因为该框架具有最先进的基线性能,并且被研究人员广泛使用。使用该框架开发大模型存在两个障碍:
- 基本的卷积块可能不适合扩展。
nnU-Net架构不能被轻易地微调,因为它们被视为超参数,因此具有任务特定性。
为了解决这些问题,本文对 nnU-Net 进行了改进和扩展,提出了一种新的可扩展和可转移的大规模医学图像分割模型 STU-Net。此外,在大规模数据集上验证了 STU-Net 的有效性,并在多个下游数据集上展现了出色的转移性能。
方法
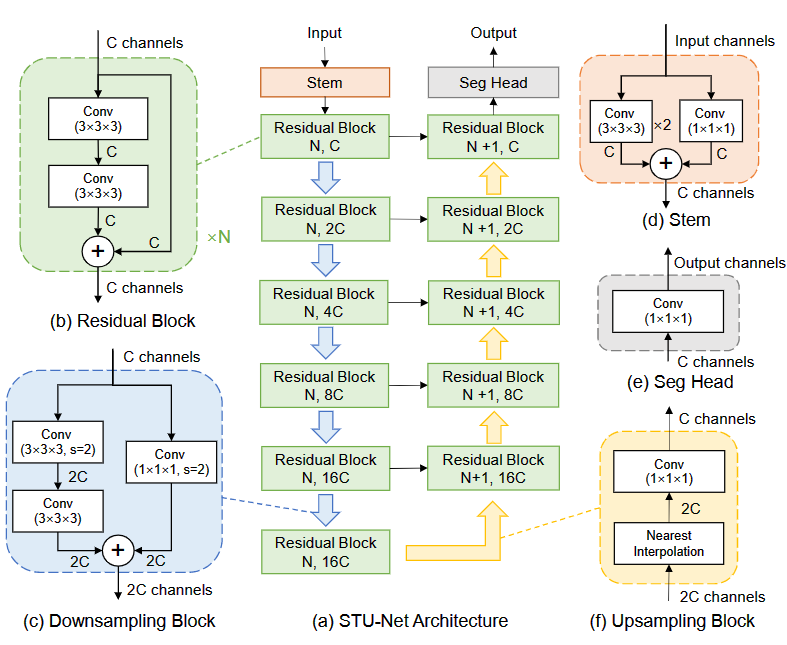
STU-Net 是基于 nnU-Net 框架构建的,该框架可以自动配置任务特定的超参数,并在各种任务上实现最先进的性能。
nnU-Net 架构
nnU-Net 采用了基于跳跃连接的对称编码器-解码器体系结构,其中包含各种分辨率阶段。每个阶段由两个卷积层组成,后跟 Instance Normalization 和 Leaky ReLU (Conv-IN-LeakyReLU)。
由于其不包含残差连接,简单地在每个阶段堆叠更多层可能会遭受梯度扩散,使整个模型难以优化。这限制了 nnU-Net 的深度,并进一步限制了其可扩展性。
另一方面,nnU-Net 根据数据集属性确定输入 patch 大小和输入间距。然后,使用数据集特定的 patch 大小和间距来设置与网络体系结构相关的超参数,例如分辨率阶段的数量、卷积核和下采样/上采样比率。因此,这些与体系结构相关的超参数在任务之间有所不同,导致不同的任务具有不同的网络体系结构。此外,训练在一个任务上的模型不能直接转移到其他任务中,这限制了模型的传递能力评估。
基于 nnU-Net 改进

nnU-Net 的任务特定的超参数可以分为与模型权重相关的 (如卷积核大小、分辨率级数) 和与模型权重无关的 (例如池化核大小、输入图像块大小和间距等)。
为了使模型架构更适合转移到其他任务中,我们固定了与模型权重相关的超参数,即将所有任务的分辨率级数保持为 6,并对所有卷积层使用等向性的卷积核(3,3,3)。对于与模型权重无关的超参数,我们采用了 nnU-Net 的默认设置,以确保其在各项任务上具有最先进的性能。本文还将我们的设置与 nnU-Net 和 3D U-Net 进行了比较。
基本块
nnU-Net 的每个阶段都由一个基础块构成,每个基础块由 两个Conv-Instance Normalization- LeakyReLU 层组成。但当增加每个阶段中的基础块数量时,会由于梯度扩散而出现优化问题。
为了解决这个问题,我们在基础块中引入了残差连接。此外,为了使整个架构更加紧凑,我们还将降采样集成到每个阶段的第一个残差块中。这种降采样块具有与常规残差块相似的残差架构,由左、右两个分支组成,其中左分支有两个不同步长的 3×3×3 卷积,而右分支使用步长为 2 的 1×1×1 卷积核。这种基础块的改进使得整个架构更加紧凑,同时还能解决梯度扩散的问题。
上采样
nnU-Net 的上采样默认使用转置卷积 (transpose convolution) 进行。但对于不同任务,卷积核和步长可能会在相同的分辨率阶段内变化,这会导致转置卷积的权重形状不同,从而使得在不同任务之间进行权重传递时出现权重不匹配的问题。
为了解决这个问题,我们使用插值 (interpolation) 加上一个步长为 1 的 1×1×1 卷积层来替代转置卷积。这种权重自由的插值方法可以解决权重形状不匹配的问题。我们使用最近邻插值 (nearest neighbor interpolation) 来进行上采样,实验结果表明,最近邻插值不仅速度更快,而且还能够达到与双立方插值 (cubic linear interpolation) 相当的性能。
缩放策略

深度网络通常具有更大的感受野和更好的表示能力,而宽网络则往往在每个层中提取更丰富的多尺度特征。根据 EfficientNet 的研究结果显示,深度缩放和宽度缩放不是独立的,为了达到更好的准确性和效率,最好以复合方式缩放网络的深度和宽度。
为了简化缩放问题,我们采用了对称结构的模型,即同时缩放编码器和解码器,并在每个分辨率阶段中以相同的比例缩放深度和宽度。表2展示了 STU-Net 的不同规模,其中后缀“S,B,L,H”分别表示 “Small, Base, Large, Huge”。
大规模监督预训练
我们使用 Total Segmentator 数据集对 STU-Net 进行了预训练,STU-Net 最终的 1×1×1 卷积层有 105 个通道,对应于 Total Segmentator 中目标注释类别的总数。
为了使预训练模型更加通用和可转移,我们对 nnU-Net 中的标准训练过程进行了一些修改。与 nnU-Net 中默认的 1000 个训练 epoch 相比,我们将模型预训练了 4000 个 epoch。此外,我们发现使用镜像数据增强可以提高模型在下游任务上的转移性能。
预训练模型可以直接对由 CT 图像组成且包含上游 104 个类别目标分割类别的下游数据集进行直接推理,无需作进一步的调整。
对于具有新标签或不同模态的下游任务,我们使用训练好的模型作为初始化,并随机初始化分割输出层以匹配目标输出类别的数量。在微调过程中,分割头部是随机初始化的,而其余层的权重则从预训练模型中加载。这些权重使用比分割头部更小的学习率 (0.1倍) 进行微调,从而获得更好的结果。
实验

STU-Net-B模型在所有类别的平均DSC方面分别超过基于CNN的最佳模型nnU-Net和基于Transformer的最佳模型SwinUNETR-B 0.36%和4.48%。
将我们的基础模型进一步扩展到大尺寸和超大尺寸分别导致平均
DSC分数提高1.59%和2.94%。
STU-Net-H在Total Segmentator数据集中的所有类别和五个子类组中实现了最高的平均DSC。 结果显示了我们对nnU-Net和扩展策略的架构改进的有效性。
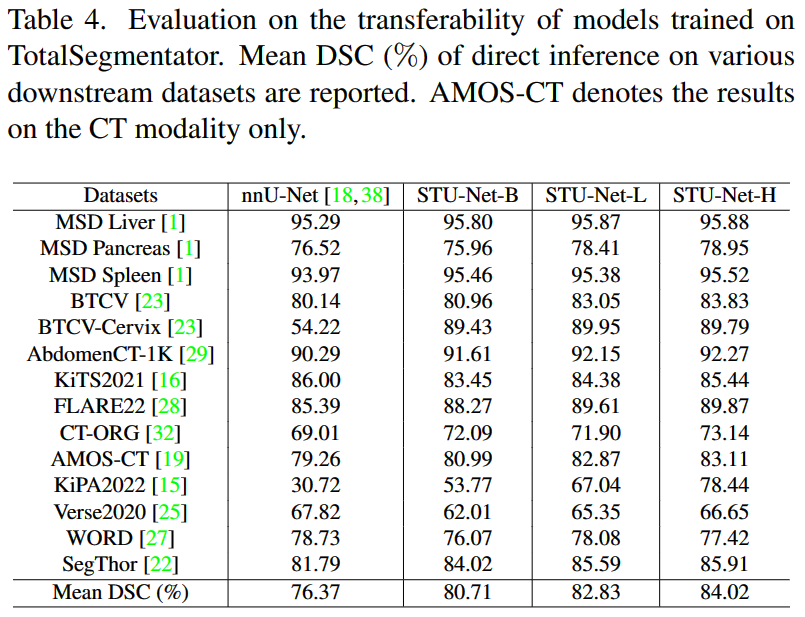
使用
Total Segmentator进行预训练时,规模较大的模型通常在所有这14个数据集中具有更高的平均DSC分数。
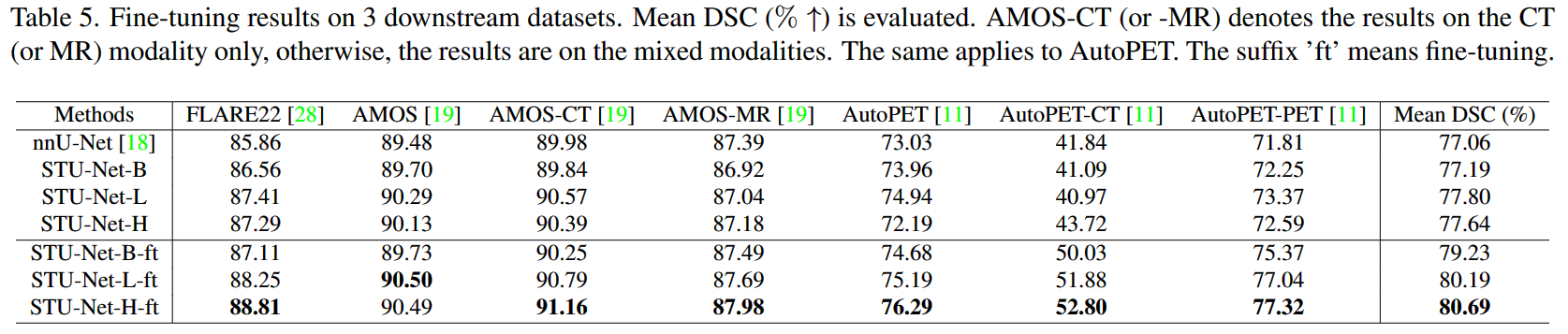
与在下游数据集上从头开始训练的模型相比,微调我们在
Total Segmentator上预训练的STU-Net模型可以获得更好的分割性能。
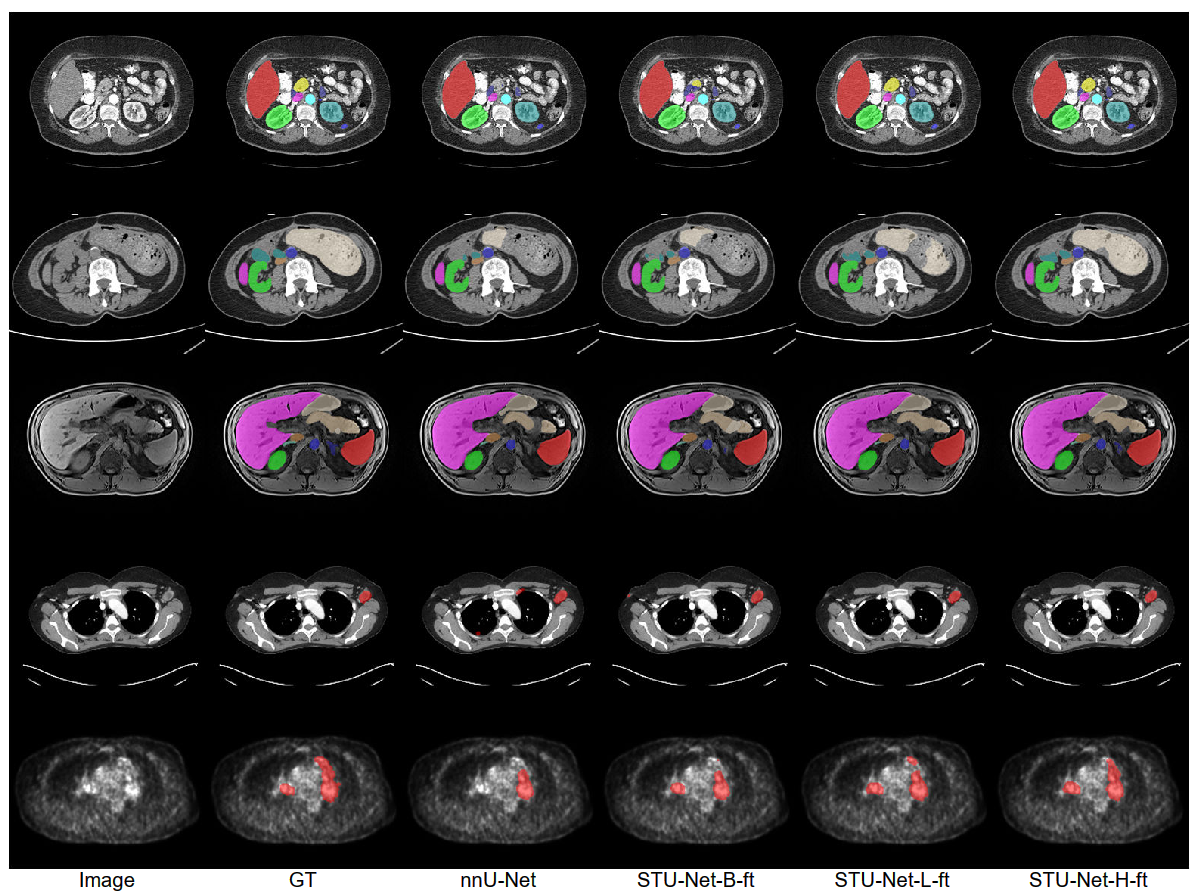
可以很直观地看出,
STU-Net的分割结果在完整度和细腻度上都比其他的模型表现更好,这更充分地证明了STU-Net在医学图像分割领域中的先进性与通用性。
总结
本文介绍了一种基于 nnU-Net 框架的可扩展和可转移的医学图像分割模型 STU-Net。STU-Net 最大包含 14 亿个参数,是迄今为止最大的医学图像分割模型。通过在大规模的 Total Segmentator 数据集上训练 STU-Net 模型,我们证明了模型规模的扩展在转移到各种下游任务时产生了显着的性能提升,同时这验证了大模型在医学图像分割领域的潜力。
此外,STU-Net-H 模型在 Total Segmentator 数据集上训练,在多个下游数据集中表现出强大的直接推断和微调可转移性。这一观察结果强调了利用大规模预训练模型进行医学图像分割任务的实际价值。
总之,可扩展和可转移的 STU-Net 模型的发展有望推动医学图像分割技术的发展,为医学图像分割社区的研究和创新开辟了新的途径。
如果您也对人工智能和计算机视觉全栈领域感兴趣,强烈推荐您关注有料、有趣、有爱的公众号『CVHub』,每日为大家带来精品原创、多领域、有深度的前沿科技论文解读及工业成熟解决方案!欢迎添加小编微信号: cv_huber,备注"CSDN",加入 CVHub 官方学术&技术交流群,一起探讨更多有趣的话题!