
追踪社会热点,解读 AI 前沿,用开源的算法,促进 AI 知识渗透,以超算/高性能计算为原点,开启人工智能前沿应用视角。OpenMMLab 开源社区联合北京超级云计算中心,共同发布直播栏目【AI 奇妙夜】,每月一期周四晚八点,陪大家一同打开 AI 领域的奇妙之门。
本期精彩
随着深度学习技术的演进,超大规模通用模型技术正在快速的发展,一个模型广泛应用于各种任务并具有某些通用智能特性的时代正在到来。虽然相关技术在自然语言处理领域取得了巨大的进展,如 ChatGPT。但是在计算机视觉领域中,还面临很多的困难和问题。本次分享将介绍清华大学博士生导师代季峰教授和他的团队在这个方向上的努力和进展。
偷偷剧透,在直播过程中,会抽取幸运观众发放 500 元卡时计算资源,还有超多精美周边礼品等你来拿哦!本次课程将在OpenMMLab和北京超级云计算中心的视频号联合播出,欢迎关注与预约。
分享内容
超大规模视觉通用感知模型的发展现状
多模态多任务统一预训练研究进展
超大规模图像主干网络研究进展
Uni-Perceiver 通用视觉任务表征研究进展
BEV 环视自动驾驶感知研究进展
分享时间
北京时间
2023 年 5 月 4日(周四)
20: 00 - 20: 40(分享)
20: 40 - 21: 00(Q&A)
分享嘉宾

代季峰
清华大学电子工程系副教授
博士生导师
OpenGVLab 核心成员
在 2009 年和 2014 年于清华大学自动化系分别获得工学学士和博士学位,博士导师周杰教授。2014 年至 2019 年在微软亚洲研究院视觉组工作,担任首席研究员、研究经理。2019 年至 2022 年在商汤科技研究院工作,担任执行研究总监,二级部门长。2022 年 7 月全职加入清华大学电子工程系。
他的研究兴趣包括计算机视觉、深度学习等。他在相关领域发表国际期刊、会议文章 50 余篇,论文总引用 2 万 6 千余次。多篇论文成为物体识别领域里程碑式的成果,被编入世界一流大学视觉课程讲义,被选入深度学习权威框架 PyTorch 成为标准算子。
他连续两年获得物体识别领域权威的 COCO 比赛冠军,之后历届冠军系统也使用了他提出的算法。他提出的算法获得自动驾驶感知领域权威的 Waymo 2022 竞赛冠军。他是顶刊 IJCV 的编委,顶会 NeurIPS 2023, ICCV 2023,CVPR 2023,CVPR 2021,ECCV 2020 的领域主席,ICCV 2019 的宣传主席。
主持人

李亦宁
上海人工智能实验室青年研究员
OpenMMLab 多个框架负责人,香港中文大学博士。主要研究方向为 Human-Centric 机器视觉,包括属性、姿态识别,图像生成,度量学习等。
内容详情
通用感知模型引领着通用人工智能进步,其由 NLP 发源,正在往更多模态发展。多模态技术拓宽了 AIGC 技术的应用广度。多模态技术将不同模态(图像、声 音、语言等)融合在预训练模型中,使得预训练模型从单一的 NLP、CV 发展成音视频、语言文字、文本图像等多模态、跨模态模型。
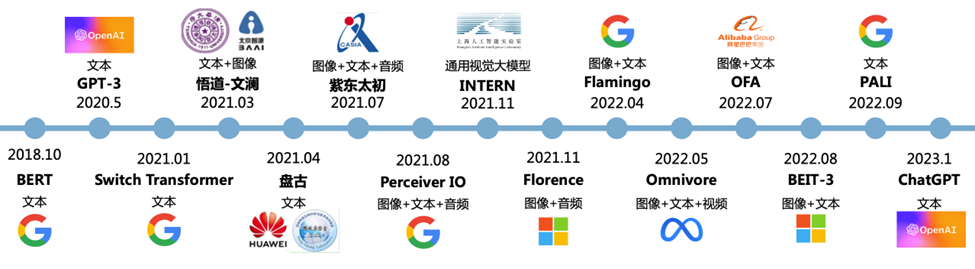
同时,通用感知模型也存在许多挑战和困难,比如:
网络参数量庞大(超十亿参数 vs 不到千万参数):训练稳定性、收敛性、过拟合等问题较小网络挑战大很多;
训练流程复杂(数十亿异质低质量图片、图文对 vs 千万同质精细标注图片):多步训练以利用异质的多模态多任务数据,流程复杂,灾难性遗忘,难以定位精度问题;
实验成本高(上千块GPU 并行训练数周 vs 8 块 GPU 训练数小时):需要研究者有敏锐的分析能力和扎实的知识功底;
工程挑战多:海量数据的吞吐,大型 GPU集群上的并行算法,超大参数量模型的内存管理。
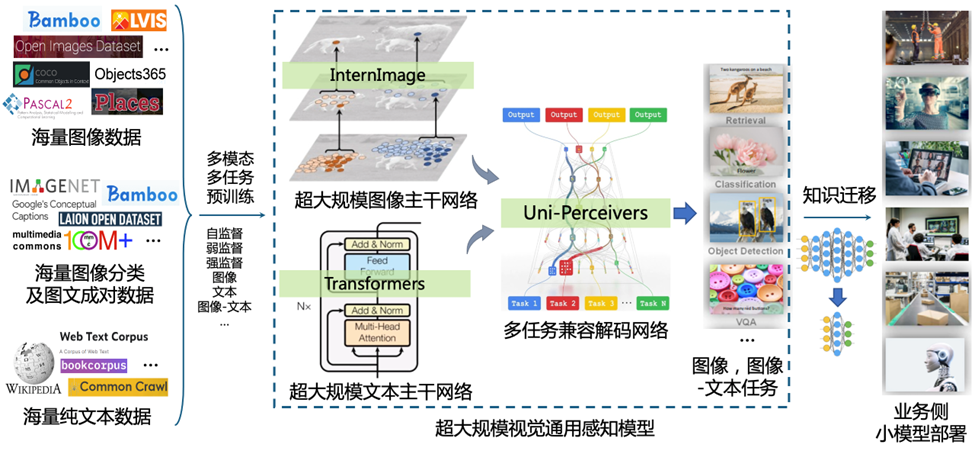
针对以上这些问题,接下来将介绍我们四个近期的研究成果,希望能带给研究者们好的启发。
研究进展一:多模态多任务统一预训练
为了能够高效地在互联网尺度图像、图文对上训练超大规模视觉模型,我们提出了“最大化互信息统一预训练”, 首次将现有各种预训练算法统一在一个框架中,首次实现多模态多任务统一预训练,一步完成多数据源的多模态多任务预训练,训练流程简洁高效,训练过程易于监控排除故障。解决了已有多模态多任务训练时训练流程复杂不鲁棒,难以分析定位训练问题,灾难性遗忘,犯错成本高的问题。
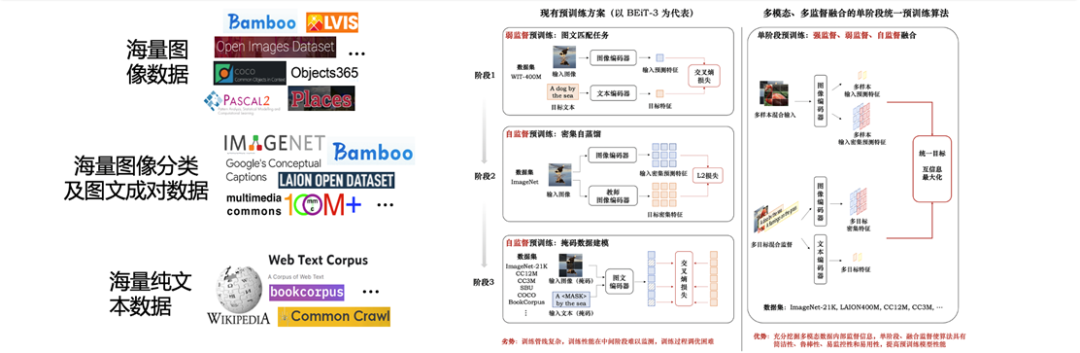
Code:https://github.com/OpenGVLab/M3I-Pretraining
研究进展二:超大规模图像主干网络
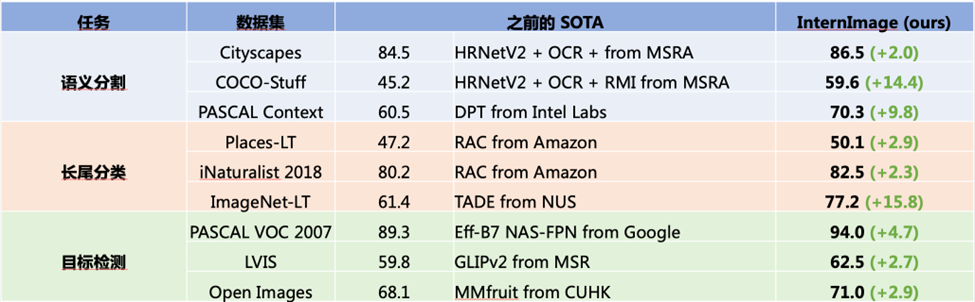
为了获得高质量的图像主干网络,使其能够适用于各种异质的视觉任务,我们提出了 InternImage大模型,以可变形卷积的方式取得了图像领域标杆任务的最优性能,打破了 Vision Transformer 对视觉大模型的垄断,超越包括微软、Meta、谷歌等机构的视觉大模型。在超大规模图像主干网络的研究中,我们需要多方面的问题:
大模型设计的范式:考虑网络深度/宽度/分辨率/分组计算数量的 scaling up 策略、针对大网络收敛不稳定的特征及梯度调整策略、针对大模型收敛慢的初始化策略、针对大模型容易过拟合的训练策略等;
大规模加速训练框架:PyTorch DDP、FSDP、DeepSpeed ZeROs、混合精度计算、融合算子、kernel 级别加速、梯度累加、梯度 checkpointing、高效数据读取、数据切分、集群文件和计算系统排疑、训练异常自动监控推送及重启、profiler等;
多任务模型训练框架:支持多网络/多任务/多数据集/多模态的联合训练(设计实现高自由度模块化的 Meta Dataloader & Sampler 和 Meta Training & inference Pipeline)、数十个任务-数据集对同时高效读取及预处理、多任务多数据集采样、基于代理任务的自动超参搜索、多任务梯度/Loss/Acc 等统计量对比监控等。
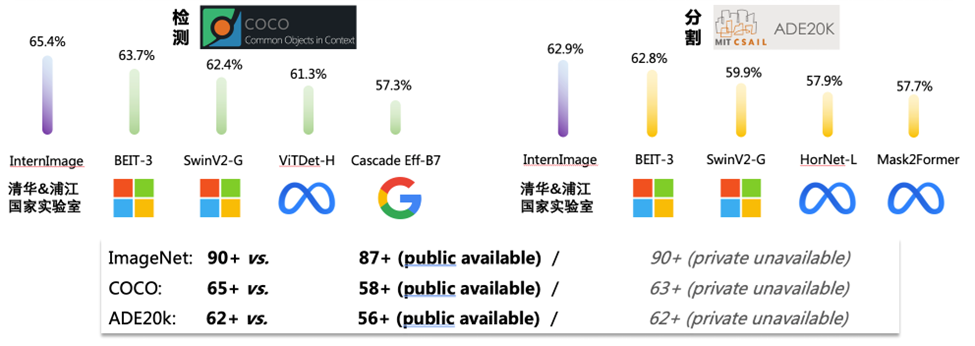
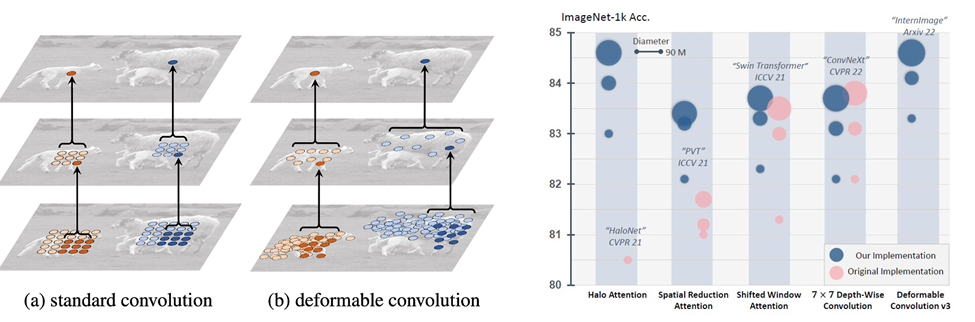
我们提出的 InternImage 模型在数十个视觉任务数据集全面领先,并于 2023 年 3 月初开源,GitHub Star 总数已达到 1K+,正快速增长中。
Code:https://github.com/opengvlab/internimage
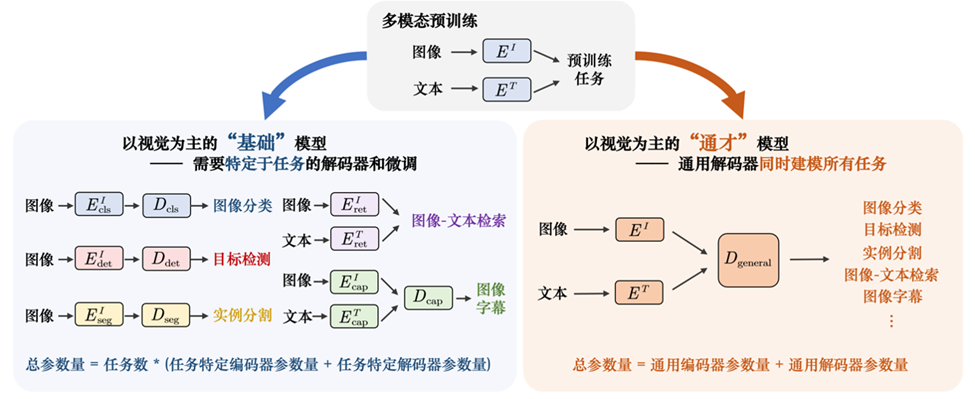
研究进展三:Uni-Perceiver 通用视觉任务表征
在计算机视觉领域,不同任务的表征差异巨大。为构建视觉任务通用的解码器网络,实现任务级别的泛化的目标,我们提出了Uni-Perceiver系列,该方法是通用视觉任务表征模型研究的先驱,首次将数十种视觉任务统一在一个表征框架下。其中Uni-Perceiver v2 已在在物体检测、实例分割等视觉核心问题上取得和专有模型相当的性能。
Code:https://github.com/fundamentalvision/Uni-Perceiver
研究进展四:BEV 环视自动驾驶感知
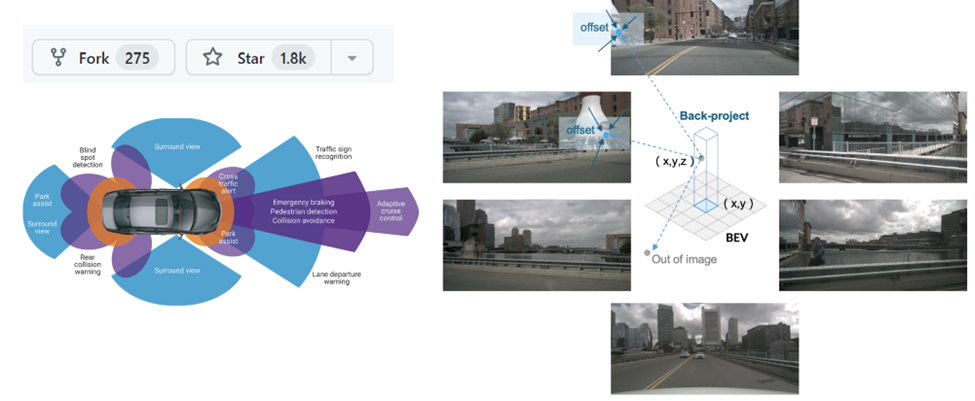
当前,工业界对相机 3D 感知有不同的探索路径,大体上可以分为 Image-view 和 BEV 方法两种。Image-view 方案使用不同网络完成感知子任务,最后通过以规则为主的融合方法对不同网络的感知结果进行融合。区别于 Image view 方案,BEV 方案通常采用 Transformer 将 Image feature 转换至 BEV 视角进行相关感知任务。针对现阶段基于视觉的 3D 目标检测方法并没有充分利用时序信息的问题,BEVFormer 提出了基于可变形注意力机制(Deformable Attention)实现的一种融合多视角相机(multi-camera)和时序特征的端到端框架,适用于多种自动驾驶感知任务,检测算法具有鲁棒性。BEVFormer入选了“Top-10 most influential papers of ECCV 2022“,也在Waymo 纯视觉 3D 检测挑战赛中斩获第一。
Code:https://github.com/fundamentalvision/BEVFormer
相关资料
Paper:
Su et. al., Towards All-in-one Pre-training via Maximizing Multi-modal Mutual Information. CVPR 2023.
Wang et. al., InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions. CVPR 2023.
Zhu et. al., Uni-perceiver: Pre-training unified architecture for generic perception for zero-shot and few-shot tasks. CVPR 2022.
Zhu et. al., Uni-Perceiver-MoE: Learning Sparse Generalist Models with Conditional MoEs. NeurIPS 2022.
Li et. al., Uni-Perceiver v2: A Generalist Model for Large-Scale Vision and Vision-Language Tasks. CVPR 2023.
Li et. al., BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers. ECCV 2022.
Yang et. al., BEVFormer v2: Adapting Modern Image Backbones to Bird's-Eye-View Recognition via Perspective Supervision. CVPR 2023.
互动有奖
1. 观看直播即可参与抽奖互动,免费领取 500 元卡时计算资源。

2. 直播期间,在 OpenMMLab 视频号、B 站或北京超算视频号、B 站参与弹幕讨论,小助手将在各平台抽取 2 名同学送出 OpenMMLab 精美周边 1 份【添加小助手:OpenMMLabwx,领取奖品】。

交流群
同时为了方便大家交流沟通,我们还建立了以【AI 奇妙夜】为主题的社群,直播相关的所有资料都将在群里分享,还能与大佬 1v1,赶紧扫码加入我们吧~

活动组织方
指导单位:中国计算机学会高性能计算专业委员会、北京市科学技术协会
主办单位:OpenMMLab、北京超级云计算中心
协办单位:北京图象图形学学会、OpenGVLab、TechBeat 人工智能社区
OpenMMLab
OpenMMLab 开源社区具备深度学习时代最完整的计算机视觉开源算法体系,是产学研用四位一体的开放开源算法平台。
OpenMMLab 专注于视觉深度学习领域,涵盖 30+ 计算机视觉方向,支持 300+ 算法,提供 2,300+ 预训练模型。所有的工具箱都基于统一架构,提供代码工程组织架构优秀、拥有大量高质量算法内容的代码库,与提供模型训练能力的 PyTorch 等深度学习框架协同互补。
OpenMMLab 可以帮助使用者降低算法复现难度,方便复现算法基准并与之比较。与此同时,还可以帮助使用者避免重复踩坑,解决算法落地过程产生的多样化版本问题,提升人工智能算法的应用和部署效率。
北京超级云计算中心
北京超级云计算中心(简称“北京超算”),成立于 2011 年,是由北京市人民政府主导、院市共建的“北京超级云计算和国家重要信息化基础平台”,现坐落于北京市怀柔综合性国家科学中心 -- 怀柔科学城。自 2019 年起,北京超算在北京、宁夏、内蒙古等地布局了三个主算力枢纽,以构建跨域资源协同调度体系,优化算力之间的统筹联动,提高科研生产效率,降低企业研发成本,为国家“东数西算”工程的实施做出了有力的响应。
2020 年、2021 年、2022 年,北京超算连续三年入围中国 HPC TOP 前 100,连续三次获得“通用 CPU 算力性能第一名”。同时在 2021 年 AIPerf 500 榜单中, 北京超算 10 套 AI 算力系统上榜,获得总量份额第一名。

(扫码添加喵喵小助手微信)

整理不易,请点赞和在看![]()