需要源码请点赞关注收藏后评论区留言私信~~~
1:数据准备
使用的数据集为深圳市2015年1月1日至1月31日的出租车轨迹数据集。实验数据主要包括两部分,一个是156×156邻接矩阵,描述道路之间的空间关系。每行代表一条道路,矩阵中的值代表道路之间的连通性。另一个是特征矩阵,它描述了每条道路上的速度随时间的变化。每一行代表一条路,每一列是不同时间段道路上的交通速度。每15分钟汇总一次每条路上的交通速度,数据维度为2976×156,使用过去10个时间步的数据预测未来1个时间步的数据。选取80%的数据作为训练集,20%数据作为测试集,又将训练集中10%的数据作为验证集,对交通速度进行实时预测
自定义函数的参数含义见下表
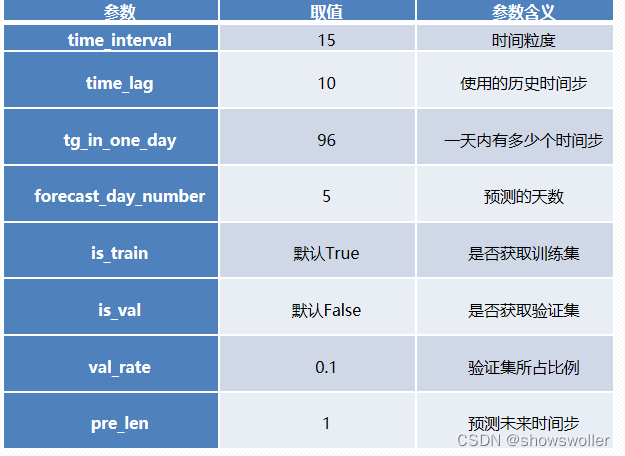
构建一个将数据集划分为训练集、验证集和测试集
在PyTorch中,DataLoader是进行数据载入的部件,必须将数据载入后再进行深度学习模型的训练
2:模型构建
构建GCN层,首先计算公式中的固定值D ̂^−1/2A ̂D ̂^−1/2
初始化GCN层时,确定每个节点的输入特征个数in_features以及输出特征个数out_features
两层GCN网络以及三层全连接网络堆叠
3:模型终止与评价
模型终止部分采用early stopping技术
使用了均方根误差RMSE,皮尔逊相关系数R2,平均绝对误差MAE,加权平均绝对百分比误差WMAPE四个指标对模型进行评价
4:模型训练及测试
在模型训练:加载数据,运用model得到预测值、loss,并返回损失值进行参数更新
在模型测试部分,首先需要利用torch.load函数将训练过程中保存的模型导入进来,然后利用model.load_state_dict将保存的参数字典加载到模型中
5:结果展示
结果展示如下 可见模型对于大部分时候的交通速度预测的十分精确,但是在部分极大值和极小值上预测的误差十分大,这也是模型改进的目标方向
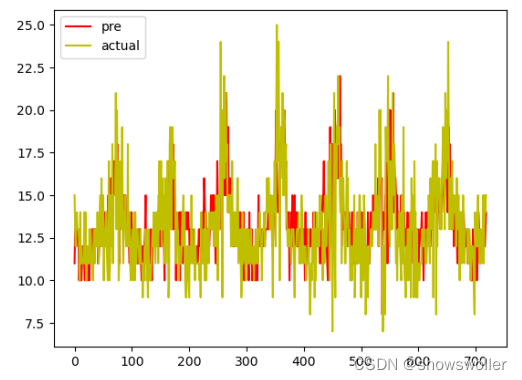
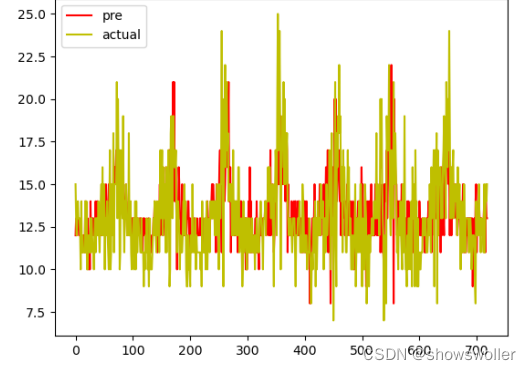
6:代码
最后 部分代码如下 需要全部代码和数据集请点赞关注收藏后评论区留言私信~~~
项目结构如下

![]()
import torch
from torch.utils.data import Dataset
import numpy as np
"""
Parameter:
time_interval, time_lag, tg_in_one_day, forecast_day_number, is_train=True, is_val=False, val_rate=0.1, pre_len
"""
class Traffic_speed(Dataset):
def __init__(self, time_interval, time_lag, tg_in_one_day, forecast_day_number, speed_data, pre_len, is_train=True, is_val=False, val_rate=0.1):
super().__init__()
# 此部分的作用是将数据集划分为训练集、验证集、测试集。
# 完成后X的维度为 num*276*10,10代表10个时间步,Y的维度为 num*276*1
# X为临近同一时段的10个时间步
# Y为156条主干道未来1个时间步
self.time_interval = time_interval
self.time_lag = time_lag
self.tg_in_one_day = tg_in_one_day
self.forecast_day_number = forecast_day_number
self.tg_in_one_week = self.tg_in_one_day*self.forecast_day_number
self.speed_data = np.loadtxt(speed_data, delimiter=",").T # 对数据进行转置
self.max_speed = np.max(self.speed_data)
self.min_speed = np.min(self.speed_data)
self.is_train = is_train
self.is_val = is_val
self.val_rate = val_rate
self.pre_len = pre_len
# Normalization
self.speed_data_norm = np.zeros((self.speed_data.shape[0], self.speed_data.shape[1]))
for i in range(len(self.speed_data)):
for j in range(len(self.speed_data[0])):
self.speed_data_norm[i, j] = round((self.speed_data[i, j]-self.min_speed)/(self.max_speed-self.min_speed), 5)
if self.is_train:
self.start_index = self.tg_in_one_week + time_lag
self.end_index = len(self.speed_data[0]) - self.tg_in_one_day * self.forecast_day_number - self.pre_len
else:
self.start_index = len(self.speed_data[0]) - self.tg_in_one_day * self.forecast_day_number
self.end_index = len(self.speed_data[0]) - self.pre_len
self.X = [[] for index in range(self.start_index, self.end_index)]
self.Y = []
self.Y_original = []
# print(self.start_index, self.end_index)
for index in range(self.start_index, self.end_index):
temp = self.speed_data_norm[:, index - self.time_lag: index] # 邻近几个时间段的进站量
temp = temp.tolist()
self.X[index - self.start_index] = temp
self.Y.append(self.speed_data_norm[:, index:index + self.pre_len])
self.X, self.Y = torch.from_numpy(np.array(self.X)), torch.from_numpy(np.array(self.Y)) # (num, 276, time_lag)
# if val is not zero
if self.val_rate * len(self.X) != 0:
val_len = int(self.val_rate * len(self.X))
train_len = len(self.X) - val_len
if self.is_val:
self.X = self.X[-val_len:]
self.Y = self.Y[-val_len:]
else:
self.X = self.X[:train_len]
self.Y = self.Y[:train_len]
print("X.shape", self.X.shape, "Y.shape", self.Y.shape)
if not self.is_train:
for index in range(self.start_index, self.end_index):
self.Y_original.append(self.speed_data[:, index:index + self.pre_len]) # the predicted speed before normalization
self.Y_original = torch.from_numpy(np.array(self.Y_original))
def get_max_min_speed(self):
return self.max_speed, self.min_speed
def __getitem__(self, item):
if self.is_train:
return self.X[item], self.Y[item]
else:
return self.X[item], self.Y[item], self.Y_original[item]
def __len__(self):
return len(self.X)
from data.datasets import Traffic_speed
from torch.utils.data import DataLoader
speed_data = "./data/sz_speed-论文数据.csv"
def get_speed_dataloader(time_interval=15, time_lag=5, tg_in_one_day=72, forecast_day_number=5, pre_len=1, batch_size=32):
# train speed data loader
print("train speed")
speed_train = Traffic_speed(time_interval=time_interval, time_lag=time_lag, tg_in_one_day=tg_in_one_day, forecast_day_number=forecast_day_number,
pre_len=pre_len, speed_data=speed_data, is_train=True, is_val=False, val_rate=0.1)
max_speed, min_speed = speed_train.get_max_min_speed()
speed_data_loader_train = DataLoader(speed_train, batch_size=batch_size, shuffle=False)
# validation speed data loader
print("val speed")
speed_val = Traffic_speed(time_interval=time_interval, time_lag=time_lag, tg_in_one_day=tg_in_one_day, forecast_day_number=forecast_day_number,
pre_len=pre_len, speed_data=speed_data, is_train=True, is_val=True, val_rate=0.1)
speed_data_loader_val = DataLoader(speed_val, batch_size=batch_size, shuffle=False)
# test speed data loader
print("test speed")
speed_test = Traffic_speed(time_interval=time_interval, time_lag=time_lag, tg_in_one_day=tg_in_one_day, forecast_day_number=forecast_day_number,
pre_len=pre_len, speed_data=speed_data, is_train=False, is_val=False, val_rate=0)
speed_data_loader_test = DataLoader(speed_test, batch_size=batch_size, shuffle=False)
return speed_data_loader_train, speed_data_loader_val, speed_data_loader_test, max_speed, min_speed
import numpy as np
import os, time, torch
from torch import nn
from torch.utils.tensorboard import SummaryWriter
from utils.utils import GetLaplacian
from model.main_model import Model
import matplotlib.pyplot as plt
from utils.metrics import Metrics, Metrics_1d
from data.get_dataloader import get_speed_dataloader
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
epoch_num = 1000
lr = 0.001
time_interval = 15
time_lag = 10
tg_in_one_day = 72
forecast_day_number = 15
pre_len = 1
batch_size = 32
station_num = 156
# model_type = 'ours'
# TIMESTAMP = str(time.strftime("%Y_%m_%d_%H_%M_%S"))
# save_dir = './save_model/' + model_type + '_' + TIMESTAMP
# if not os.path.exists(save_dir):
# os.makedirs(save_dir)
speed_data_loader_train, speed_data_loader_val, speed_data_loader_test, max_speed, min_speed = \
get_speed_dataloader(time_interval=time_interval, time_lag=time_lag, tg_in_one_day=tg_in_one_day, forecast_day_number=forecast_day_number, pre_len=pre_len, batch_size=batch_size)
# get normalized adj
adjacency = np.loadtxt('./data/sz_adj1.csv', delimiter=",")
adjacency = torch.tensor(GetLaplacian(adjacency).get_normalized_adj(station_num)).type(torch.float32).to(device)
global_start_time = time.time()
writer = SummaryWriter()
model = Model(time_lag, pre_len, station_num, device)
if torch.cuda.is_available():
model.cuda()
model = model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
mse = torch.nn.MSELoss().to(device)
path = './save_model/ours_2021_08_25_08_40_23/model_dict_checkpoint_2929_0.00017515.pth'
checkpoint = torch.load(path)
model.load_state_dict(checkpoint, strict=True)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
# test
result = []
result_original = []
if not os.path.exists('result/prediction'):
os.makedirs('result/prediction/')
if not os.path.exists('result/original'):
os.makedirs('result/original')
with torch.no_grad():
model.eval()
test_loss = 0
for speed_te in enumerate(speed_data_loader_test):
i_batch, (test_speed_X, test_speed_Y, test_speed_Y_original) = speed_te
test_speed_X, test_speed_Y = test_speed_X.type(torch.float32).to(device), test_speed_Y.type(torch.float32).to(device)
target = model(test_speed_X, adjacency)
loss = mse(input=test_speed_Y, target=target)
test_loss += loss.item()
# evaluate on original scale
# 获取result (batch, 276, pre_len)
clone_prediction = target.cpu().detach().numpy().copy() * max_speed # clone(): Copy the tensor and allocate the new memory
# print(clone_prediction.shape) # (16, 276, 1)
for i in range(clone_prediction.shape[0]):
result.append(clone_prediction[i])
# 获取result_original
test_speed_Y_original = test_speed_Y_original.cpu().detach().numpy()
# print(test_OD_Y_original.shape) # (16, 276, 1)
for i in range(test_speed_Y_original.shape[0]):
result_original.append(test_speed_Y_original[i])
print(np.array(result).shape, np.array(result_original).shape) # (num, 276, 1)
# 取整&非负取0
result = np.array(result).astype(np.int)
result[result < 0] = 0
result_original = np.array(result_original).astype(np.int)
result_original[result_original < 0] = 0
# # 取出多个车站进行画图 # (num, 276, 1) # (num, 276, 2) # (num, 276, 3)
x = [[], [], [], [], []]
y = [[], [], [], [], []]
for i in range(result.shape[0]):
x[0].append(result[i][4][0])
y[0].append(result_original[i][4][0])
x[1].append(result[i][18][0])
y[1].append(result_original[i][18][0])
x[2].append(result[i][30][0])
y[2].append(result_original[i][30][0])
x[3].append(result[i][60][0])
y[3].append(result_original[i][60][0])
x[4].append(result[i][94][0])
y[4].append(result_original[i][94][0])
result = np.array(result).reshape(station_num, -1)
result_original = result_original.reshape(station_num, -1)
RMSE, R2, MAE, WMAPE = Metrics(result_original, result).evaluate_performance()
avg_test_loss = test_loss / len(speed_data_loader_test)
print('test Loss:', avg_test_loss)
RMSE_y0, R2_y0, MAE_y0, WMAPE_y0 = Metrics_1d(y[0], x[0]).evaluate_performance()
RMSE_y1, R2_y1, MAE_y1, WMAPE_y1 = Metrics_1d(y[1], x[1]).evaluate_performance()
RMSE_y2, R2_y2, MAE_y2, WMAPE_y2 = Metrics_1d(y[2], x[2]).evaluate_performance()
RMSE_y3, R2_y3, MAE_y3, WMAPE_y3 = Metrics_1d(y[3], x[3]).evaluate_performance()
RMSE_y4, R2_y4, MAE_y4, WMAPE_y4 = Metrics_1d(y[4], x[4]).evaluate_performance()
# L3, = plt.plot(x[0], color="r")
# L4, = plt.plot(y[0], color="b")
# plt.legend([L3, L4], ["L3-prediction", "L4-true"], loc='best')
# plt.show()
ALL = [RMSE, MAE, WMAPE]
y0_ALL = [RMSE_y0, MAE_y0, WMAPE_y0]
y1_ALL = [RMSE_y1, MAE_y1, WMAPE_y1]
y2_ALL = [RMSE_y2, MAE_y2, WMAPE_y2]
y3_ALL = [RMSE_y3, MAE_y3, WMAPE_y3]
y4_ALL = [RMSE_y4, MAE_y4, WMAPE_y4]
np.savetxt('result/lr_' + str(lr) + '_batch_size_' + str(batch_size) + '_ALL.txt', ALL)
np.savetxt('result/lr_' + str(lr) + '_batch_size_' + str(batch_size) + '_y0_ALL.txt', y0_ALL)
np.savetxt('result/lr_' + str(lr) + '_batch_size_' + str(batch_size) + '_y1_ALL.txt', y1_ALL)
np.savetxt('result/lr_' + str(lr) + '_batch_size_' + str(batch_size) + '_y2_ALL.txt', y2_ALL)
np.savetxt('result/lr_' + str(lr) + '_batch_size_' + str(batch_size) + '_y3_ALL.txt', y3_ALL)
np.savetxt('result/lr_' + str(lr) + '_batch_size_' + str(batch_size) + '_y4_ALL.txt', y4_ALL)
np.savetxt('result/X_original.txt', x)
np.savetxt('result/Y_prediction.txt', y)
print("ALL:", ALL)
print("y0_ALL:", y0_ALL)
print("y1_ALL:", y1_ALL)
print("y2_ALL:", y2_ALL)
print("y3_ALL:", y3_ALL)
print("y4_ALL:", y4_ALL)
print("end")
x = x[1]
y = y[1]
plt.xlabel("Time granularity=15min")
plt.ylabel("Speed")
L1, = plt.plot(x, color="r")
L2, = plt.plot(y, color="y")
plt.legend([L1, L2], ["pre", "actual"], loc='best')
plt.show()
创作不易 觉得有帮助请点赞关注收藏~~~