需要源码和数据集请点赞关注收藏后评论区留言私信~~~
在进行实战预测之前,我们先来介绍一下卷积神经网络
使用全连接神经网络处理图像问题时,往往存在以下三个缺陷:
参数过多
随着隐藏层神经元数量的增多,参数的规模也会急剧增加,导致整个神经网络的成本很高,训练效率非常低,且容易出现过拟合
难以捕捉局部特征
全连接前馈网络很难提取局部不变性特征(比如尺度缩放、平移、旋转等操作不影响其语义信息),一般需要进行数据增强来提高其性能
导致信息缺失
由于全连接神经网络在处理图像信息时,首先需要将图像展开为向量,因此部分空间信息容易丢失,导致图像识别的准确率不高
针对全连接前馈神经网络处理图像时存在的缺陷,学者受到生物学上的感受野机制的启发,提出了卷积神经网络(Convolutional Neural Network,CNN),较好地化解了以上的三个缺陷
其核心思想就是通过建立卷积层、池化层以及全连接层实现对图像的精确处理。卷积层负责提取图像中的局部特征,接着利用池化层大幅降低参数数量(降维)从而提高训练效率,最后通过全连接层进行线性转换,输出结果
一、卷积层
提取特征
对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重)做矩阵内积(对应元素相乘再求和)的操作就是所谓的“卷积”,也是卷积神经网络的来源
在具体应用中,往往会有多种卷积核,每种卷积核代表一种图像特征,比如颜色深浅、轮廓等。如果某个图像块与该卷积核内积得到的数值大,则认为非常接近该图像特征。通过卷积核的过滤可以提取图像中的局部特征



二、池化层
池化层(下采样)—— 数据降维,避免过拟合
池化层简单来说就是下采样,用于压缩数据和参数的量,降低位数,减小过拟合的现象,通常来说就是取区域最大或者区域平均
特征不变性:通过池化操作,依然可以保留图像的重要特征
数据降维:通过池化剔除这些冗余的信息,大大降低数据维度,防止过拟合

三、全连接层
全连接层 —— 输出结果
这个部分是整个卷积神经网络的最后一步,经过卷积和池化处理后的数据输入到全连接层,根据回归或者分类问题的需要,选择不同激活函数获得最终想要的结果。也就是跟传统的神经网络神经元的连接方式是一样的,即所有神经元都有权重连接
近年来,由于计算机视觉的飞速发展,卷积神经网络得到了广泛的应用。目前来说二维卷积神经网络的使用范围是最广的,受到了许多计算机爱好者的追捧与研究。因此当我们说卷积神经网络(CNN)时,通常是指用于图像分类的二维卷积,上文中对于卷积神经网络的介绍正是基于二维卷积进行介绍的。其实除了二维卷积神经网络,还有用于预测时间序列的一维卷积神经网络,以及面向视频处理领域(检测动作及人物行为)的三维卷积神经网络
那么,二者究竟有何种区别呢?难道一维卷积就是处理一维数据,而二维卷积就是处理二维数据
这是错误的
无论是一维还是二维,CNN都具有相同的特征并采用相同的方法,关键区别在于输入数据的维度以及特征检测器(卷积核)如何在数据上滑动

一维卷积神经网络
一维卷积神经网络,其卷积核在数据上只能沿一维(水平)方向滑动,通常输入的是一个向量,输出的也是一个向量。当我们希望从整体数据集的较短片段中获取重要的特征,且该特征与空间位置不相关时(比如所有特征都是在同一个位置产生的数据),一维卷积神经网络将非常有效。具体计算如下图

二维卷积神经网络
与一维卷积相比,二维卷积神经网络的卷积核在数据上沿二维方向(水平和竖直方向)滑动。由于二维卷积神经网络可以使用其卷积核从数据中提取空间特征,例如检测图像的边缘、颜色分布等,使得二维卷积神经网络在图像分类和包含空间属性的其他类似数据的处理中功能非常强大,目前来说也是使用范围最广的卷积神经网络

四、PyTorch实现一维卷积神经网络时间序列预测
以2016年北京地铁西直门站每15min客流的进站数据为例,利用PyTorch搭建一维卷积神经网络,实现对进站客流数据的预测
导入数据并且可视化如下

入西直门地铁站进站客流数据后,需要划分训练集和测试集。共有1799个时间段的客流数据,以数据集的后300个作为测试集。为了获得更好的训练效果,将客流数据进行归一化处理,归一化到[-1,1]区间
为提高预测的精确度,该一维卷积神经网络采取了两层卷积层、一层最大池化层以及两层全连接层堆叠而成,使用ReLU作为激活函数,在池化作用后还使用dropout函数避免训练出现过拟合现象。
接着就是定义损失函数和优化器。本实验选择MSELoss作为训练的损失函数,选择Adam作为训练的优化器,学习率lr=0.0005
以上就是卷积神经网络的搭建过程,接下来需要对网络进行训练。首先定义迭代次数epoch = 20,同时将网络调整为训练模式。接着利用for循环遍历训练所用的样本数据,需要注意的是在每次更新参数前需要进行梯度归零和初始化。由于输入的数据形状不符合网络输入的格式,还需要对样本数据的形状进行调整,调整为conv1的input_size: (batch_size, in_channels, series_legth)
训练结果迭代如下

模型训练完成以后,选取序列最后的72个数据开始预测。首先将网络模式设为eval模式,由于需要预测数据集的后300个数据,因此需要遍历300次,循环的每一步表示时间窗口向时间序列向后滑动一格,这样每一次最近时刻的真实值都会加入数据集作输入去预测输出新的客流数据,最新加入到时间窗口的值为真实值,而非预测值,可以一定程度上避免误差累积。同时因为是使用训练好的模型进行预测,因此不需要再对模型的权重和偏差进行反向传播和优化。另外在预测完成以后,为了体现预测的效果,将预测值进行逆归一化操作还原为真实的客流值,便于与实际客流进行比较
预测结果如下
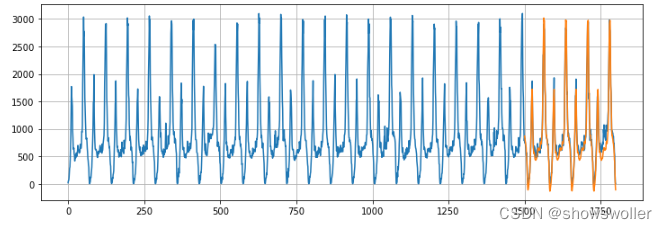
可见大体上还是拟合的非常不错的,除了部分极大值和波动频繁的时间段稍微有点出入,这也是模型改进的目标方向
最后 部分代码如下
import torch
import torch.nn as nn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
# 导入北京地铁站点15min进站客流
df = pd.read_csv('./15min_in.csv', index_col = 0, encoding = "gbk", parse_dates = True)
len(df)
df.head() # 观察数据集,这是一个单变量时间序列
试集和训练集,最后300个作为测试集
test_size = 300
train_iter = y[
# 创建时间序列训练集
train_set = torch.FloatTensor(train_norm).view(-1)
# 定义时间窗口
Time_window_size = 72
# 从原时间序列中抽取出训练样本,用第1个值到第72个值作为X输入,预测第73个值作为y输出,这是一个用于训练的数据点,时间窗口向后滑动以此类推
def input_data(seq, ws):
out = []
L = len(seq)
for i in range(L-ws):
window = seq[i:i + ws]
label = seq[i + ws:i + ws + 1]
out.append((window, label))
return out
train_data = input_data(train_set, Time_window_size)
len(train_data) # 等于1799(原始数据集长度)-300(测试集长度)-72(时间窗口)
from numpy.lib.stride_tricks import sliding_window_view
output = slidCNNnetwork, self).__init__()
self.conv1 = nn.Conv1d(in_channels=1, out_channels=64, kernel_size=2)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv1d(in_channels=64, out_channels=32, kernel_size=2)
self.pool = nn.MaxPool1d(kernel_size=2,stride=2)
self.fc1 = nn.Linear(32*35, 640)
self.fc2 = nn.Linear(640, 1)
# self.fc1 = nn.Linear(32*70, 640)
self.drop = nn.Dropout(0.5)
def forward(self,x):
x = self.conv1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.relu(x)
x = self.pool(x)
x = self.relu(x)
x = self.fc2(x)
return x
device = torch.device("cuda")
net = CNNnetwork().to(device)
# 开始训练模型
epochs = 20
net.train()
for epoch in range(epochs):
for seq, y_train in train_data:
# 每次更新参数前都梯度归零和初始化
optimizer.zero_grad()
y_train = y_train.to(device)
# 对mizer.step()
print(f'Epoch: {epoch + 1:2} Loss:{loss.item():10.8f}')
future = 300
# 选取序列最后12个值开始预测
preds = train_set[-Time_window_size:].tolist()
# 设置成eval模式
net.eval()
for i in range(future):
seq = torch.FloatTensor(preds[-Time_window_size:])
with torch.no_grad():
seq = seq.reshape(1,1,-1).to(device)
preds.append(net(seq).item())
# 逆归re(figsize=(12, 4))
plt.grid(True)
plt.plot(y)
x = np.arange(1500, 1800)
plt.plot(x, true_predictions)
plt.show()创作不易 觉得有帮助请点赞关注收藏~~~