文章目录
一,提交语法格式

- Spark提供了一个客户端应用程序提交工具spark-submit,使用该工具可以将编写好的Spark应用程序提交到Spark集群。
- spark-submit的使用格式如下:$ bin/spark-submit [options] [app options]
- options表示传递给spark-submit的控制参数;
- app jar表示提交的程序JAR包(或Python脚本文件)所在位置;
- app options表示jar程序需要传递的参数,例如main()方法中需要传递的参数。
二,spark-submit常用参数
除了–master参数外,spark-submit还提供了一些控制资源使用和运行时环境的参数。
| 参数 | 描述 |
|---|---|
| –master | Master节点的连接地址,取值为spark://host:port、mesos://host:port、yarn、k8s://https://host:port 或 local(默认为local[*]) |
| –deploy-mode | 提交方式,取值为client或cluster。client表示在本地客户端启动Driver程序,cluster表示在集群内部的工作节点上启动Driver程序,默认为client |
| –class | 应用程序的主类(Java或Scala程序) |
| –name | 应用程序名称,会在Spark Web UI中显示 |
| –jars | 应用依赖的第三方JAR包列表,以逗号分隔 |
| –files | 需要放到应用工作目录中的文件列表,以逗号分隔。此参数一般用来放需要分发到各节点的数据文件 |
| –conf | 设置任意的SparkConf配置属性,格式为“属性名=属性值” |
| –properties-file | 加载外部包含键值对的属性文件。如果不指定,就默认读取Spark安装目录下的conf/spark-defaults.conf 文件中的配置 |
| –driver-memory | Driver进程使用的内存量,例如512MB或1GB,单位不区分大小写,默认为1GB |
| –executor-memory | 每个Executor进程所使用的内存量。例如512MB或1GB,单位不区分大小写,默认为1GB |
| –driver-cores | Driver进程使用的CPU核心数,仅在集群模式中使用,默认为1 |
| -executor-cores | 每个Executor进程所使用的CPU核心数,默认为1 |
| num-executors | Executor进程数量,默认为2。如果开启动态分配,那么初始Executor的数量至少是此参数配置的数量。需要注意的是,此参数仅在Spark On YARN模式中使用 |
三,案例演示 - 提交Spark自带的圆周率计算程序
进入Spark安装目录
(一)Standalone模式,采用client提交方式
执行下述命令,将Spark自带的求圆周率的程序提交到集群
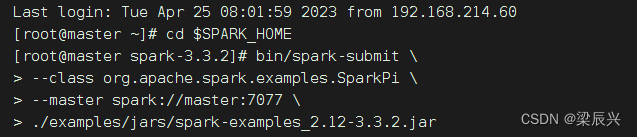
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://master:7077 \
./examples/jars/spark-examples_2.12-3.3.2.jar
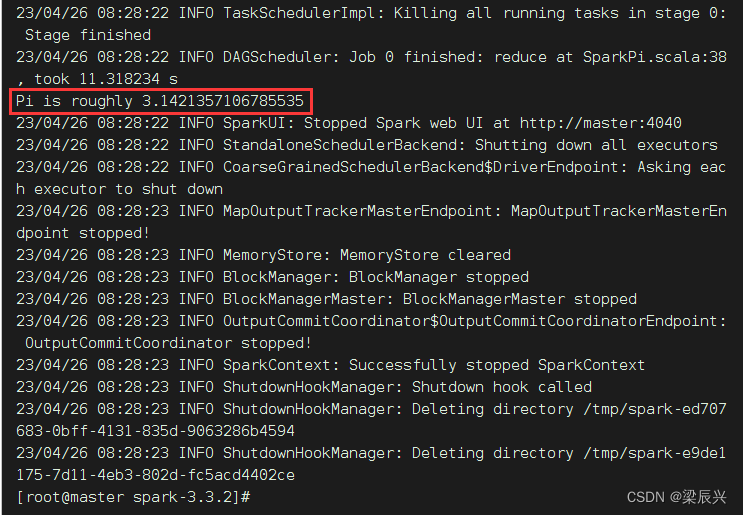
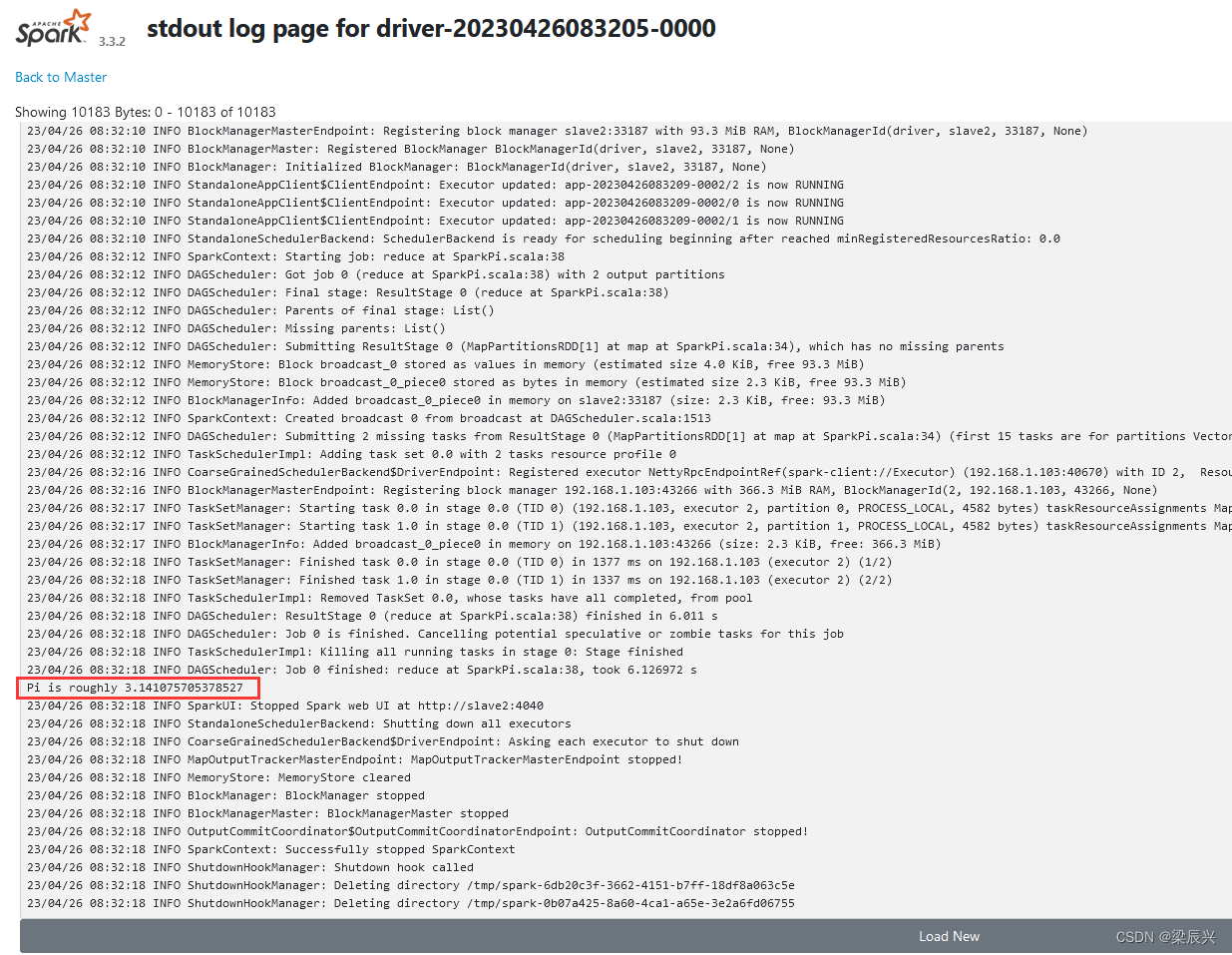
提交Spark作业后,观察Spark集群管理界面,其中“Running Applications”列表表示当前Spark集群正在计算的作业,执行几秒后,刷新界面,在Completed Applications表单下,可以看到当前应用执行完毕,返回控制台查看输出信息,出现了“Pi is roughly 3.1424157120785603”,说明Pi值已经被计算完毕。
上述命令中的–master参数指定了Master节点的连接地址。该参数根据不同的Spark集群模式,其取值也有所不同,常用取值如下表所示。
| 取值 | 描述 |
|---|---|
| spark://host:port | Standalone模式下的Master节点的连接地址,默认端口为7077 |
| yarn | 连接到YARN集群。若YARN中没有指定ResourceManager的启动地址,则需要在ResourceManager所在的节点上进行应用程序的提交,否则将因找不到ResourceManager而提交失败 |
| local | 运行本地模式,使用1个CPU核心 |
| local [N] | 运行本地模式,使用N个CPU核心。例如,local[2]表示使用两个CPU核心运行程序 |
| local[*] | 运行本地模式,尽可能使用最多的CPU核心 |
若不添加–master参数,则默认使用本地模式local[*]运行。
(二)Standalone模式,采用cluster提交方式
在Standalone模式下,将Spark自带的圆周率计算程序提交到集群,并且设置Driver进程使用内存为512MB,每个Executor进程使用内存为1GB,每个Executor进程所使用的CPU核心数为2,提交方式为cluster(Driver进程运行在集群的工作节点中),执行命令如下:

bin/spark-submit \
--master spark://master:7077 \
--deploy-mode cluster \
--class org.apache.spark.examples.SparkPi \
--driver-memory 512m \
--executor-memory 1g \
--executor-cores 2 \
./examples/jars/spark-examples_2.12-3.3.2.jar
可以写成一行
bin/spark-submit --master spark://master:7077 --deploy-mode cluster --class org.apache.spark.SparkPi --driver-memory 512m --executor-memory 1g --executor-cores 2 ./examples/jars/spark-examples_2.12-3.3.2.jar
执行命令后,看到State of driver-20230406114733-0000 is RUNNING,就表明运行成功~,否则会显示State of driver-20230406114733-0000 is FAILED

在Spark WebUI界面上查看运行结果,访问http://master:8080
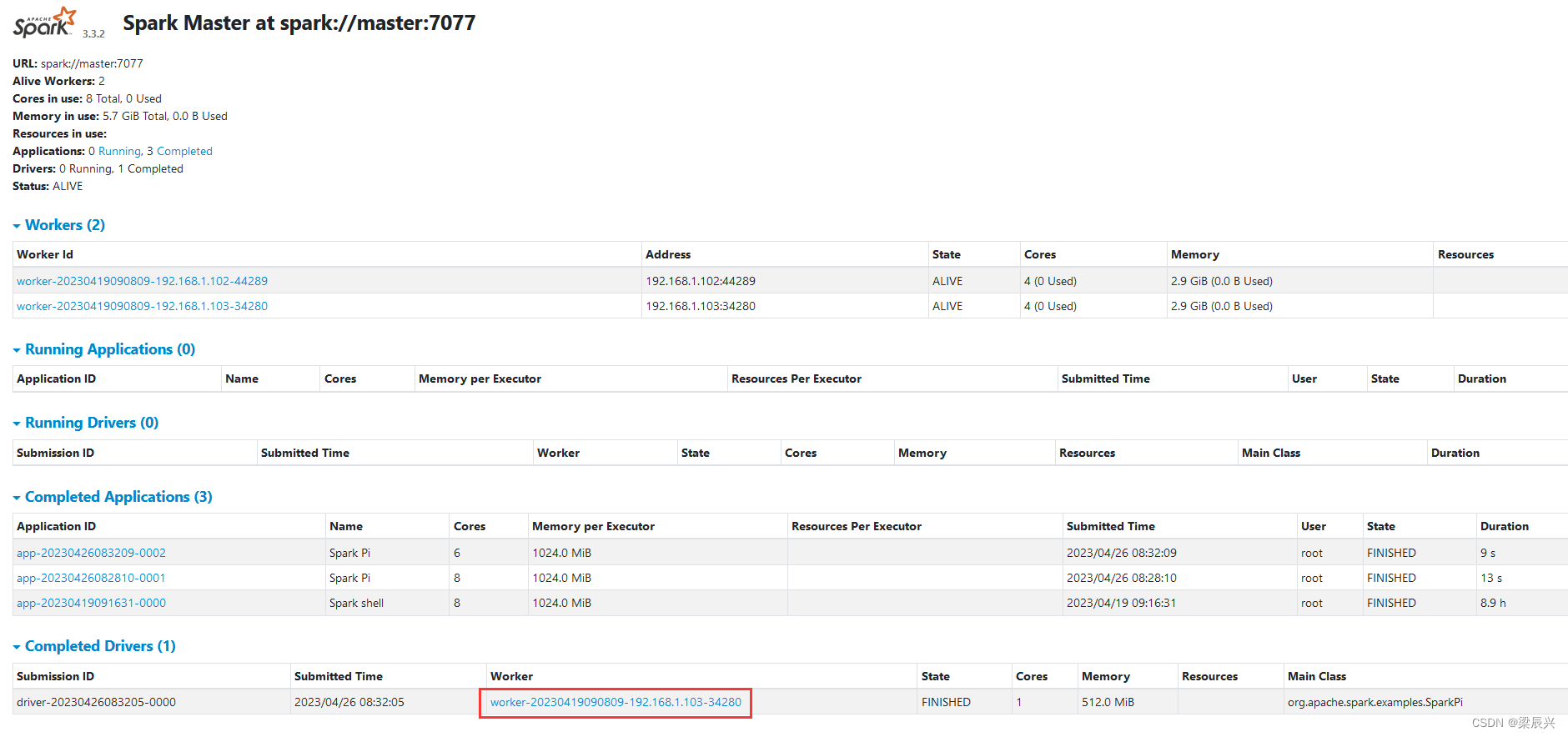
单击圈红的Worker超链接 - worker-20230406114652-192.168.1.103-34280
注意:必须把私有IP地址改成主机名slave1或者对应的浮动IP地址。
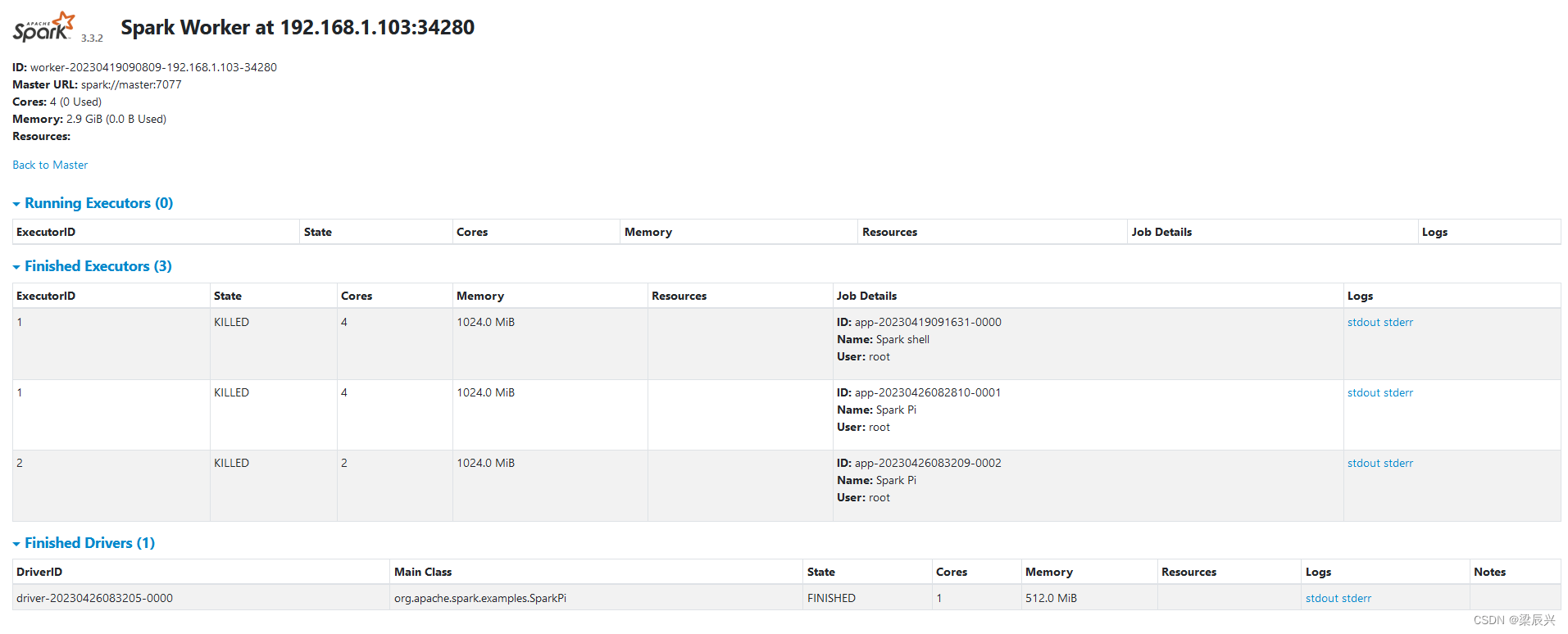
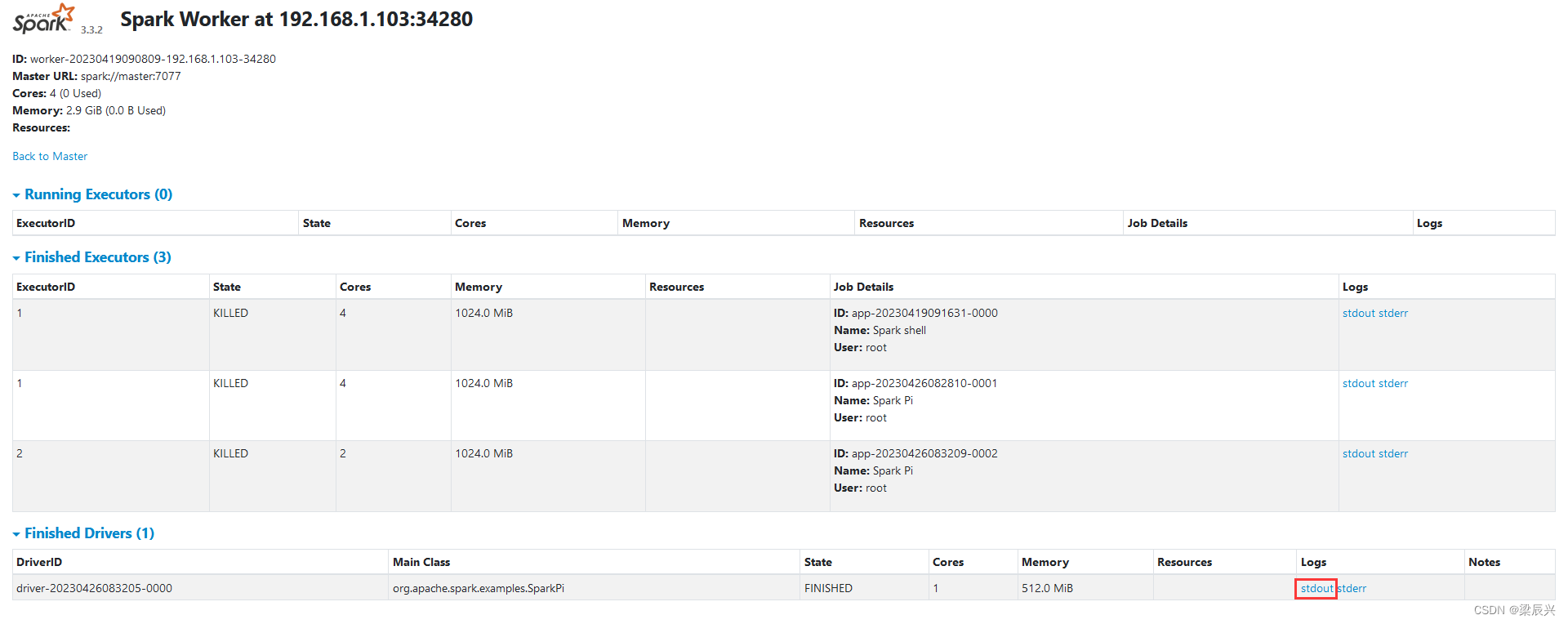
单击stdout超链接,可以查看到Pi的计算结果
(三)停止Spark集群服务
在master节点执行命令:stop-all.sh