文章目录
- Filtration and Distillation: Enhancing RegionAttention for Fine-Grained Visual Categorization(by localization- classification subnetwork)
- Interpretable and Accurate Fine-grained Recognition via Region Grouping
- Attention Convolutional Binary Neural Tree for Fine- Grained Visual Categorization
- Graph-Propagation Based Correlation Learning for Weakly Supervised Fine-Grained Image Classification
Filtration and Distillation: Enhancing RegionAttention for Fine-Grained Visual Categorization(by localization- classification subnetwork)
Abstract
大部分现存的注意力模型在FGVC任务当中表现不佳,原因有以下几点:
- 区分区域主要基于图像上的滤波器响应来定位,这不能用性能度量直接优化;
- 现有方法将基于区域的特征提取器单独训练为一个独热分类任务,然而这一方法却忽略了整个对象的知识。
为了解决上述问题,本文提出了一种新的“过滤和蒸馏学习”(FDL)模型,以提高FGVC细分部分的区域关注度。
首先,基于提议和预测之间的匹配性,本文针对有区分度的区域提议提出了一种过滤学习的方法。特别地,本文用了提议与预测的匹配性作为RPN的性能度量,从而实现了RPN的直接优化,以过滤得到最具有区分度的区域。
具体来说,基于对象的特征学习和基于区域的特征学习被定义为“教师”和“学生”,这可以为基于区域的学习提供更好的监督。
FDL可以有效地提升区域关注度,并且在不需要对象或部分注释的情况下对整个框架进行端到端的训练。
Introduction
缺失对于局部提取的性能度量的问题此处不再过多赘述。
关于第二个问题,目前一些工作仅训练基于区域的特征提取器而忽略了来自整个对象的知识。尽管一些搜索通过连接从对象和部分提取的特征来进一步考虑对象-区域的关系,但基于区域的特征向量仍然通过一个独热分类任务来训练。因此,基于区域的特征学习忽略了整个对象的监督。
本文提出了FDL模型,通过提议-预测辨别匹配和对象-区域知识转换来增强区域注意力。
首先,基于提出和预测之间的匹配性,提出了一种过滤学习(FL)方法来区分部分区域的提出。具体而言,本文使用RPN来生成一个矩形区域列表,每个矩形区域都有一个置信度分数,这表明了建议区域之间的区别。
提议-预测匹配性指的是:如果一个区分区域带来了一个清晰的分类结果,那么相应的概率会比较高,从而与RPN产生的高置信度得分相匹配。因此,置信度得分和概率应该保持一致。
于是,本文采用S和P的匹配分数作为性能度量并根据ranking loss直接优化RPN。因此,RPN能够正确且有效地过滤得到最具有区分度的区域。
其次,本文提出了一种蒸馏学习的方法,通过知识提取将来自整个对象的知识融合到基于区域的特征学习中。
Approach
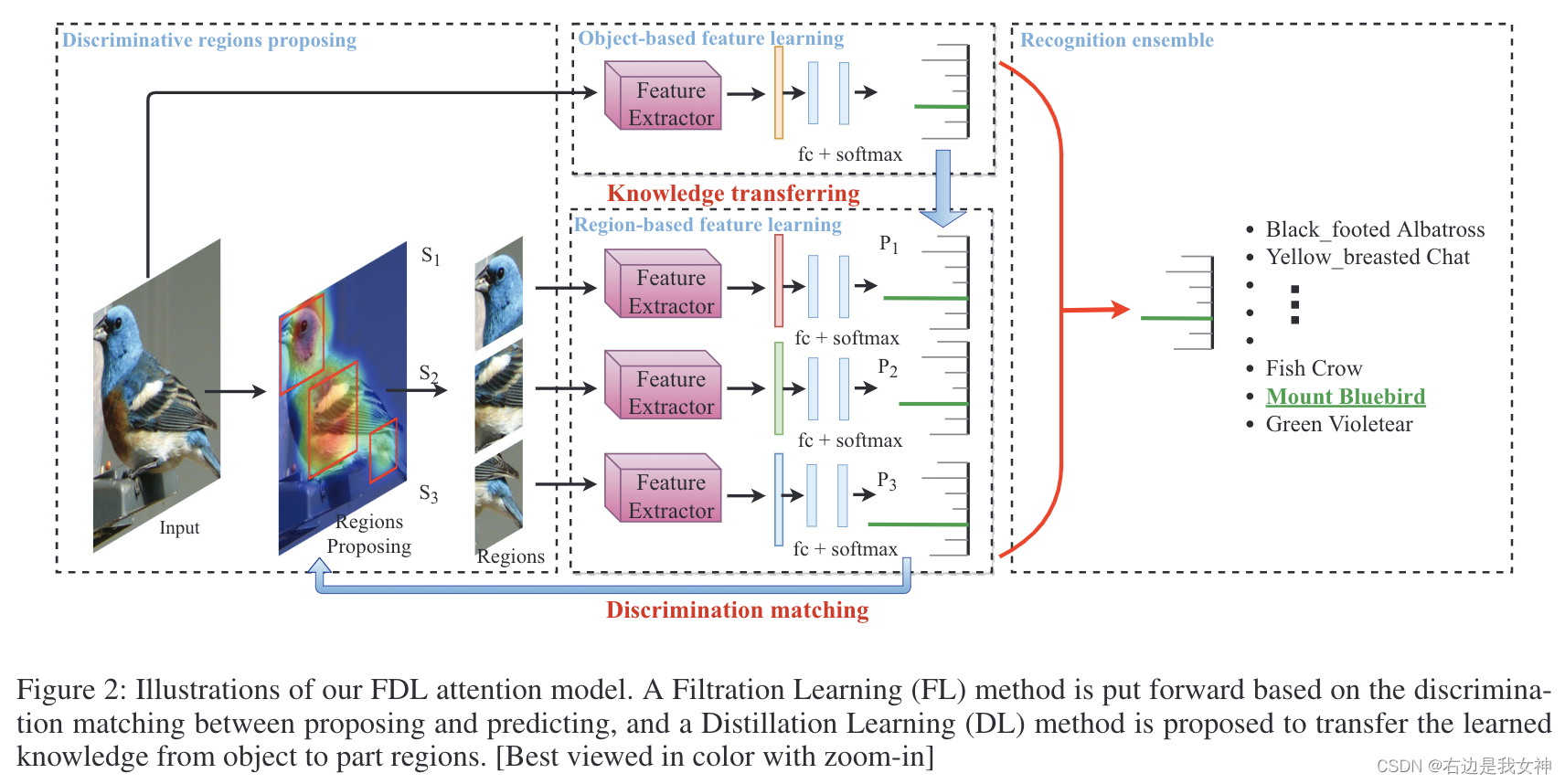
Discriminative Regions Proposing
RPN将图像作为输入,生成一系列矩形区域,每个矩形区域都有对应的置信度得分 S ( R i ′ ) S(R_i') S(Ri′)。选择尺度为{48,96,192},比例为{1:1,3:2,2:3}的锚框。该列表按照分数从高到低进行排序。
为了冗余,我们根据置信度分数采用非极大值抑制的手段。
NMS之后,FDL选择M个最重要的局部区域。然后从输入图像中裁剪区域,并将其调整到预定义的大小以进行进一步的特征学习。
Feature Learning and Recognition Ensemble
在调整到预定义大小之后,头部的M个区域被送入到特征提取器来生成特征向量 v ( R i ) v(R_i) v(Ri),每一个长度都是L。
然后,将特征向量送到具有L个神经元的全连接层和softmax层,以生成概率 { P j ( R i ) } \{P^j(R_i)\} { Pj(Ri)}。表示区域i在第j类上的置信度得分。
对象图像O也被送到了分类器,本文生成其特征向量 v ( O ) v(O) v(O)和预测结果 P j ( O ) P^j(O) Pj(O)。
为了进一步利用局部特征的优势,本文通过连接v(O)和前K个局部特征向量得到object-region concatenated feature vector:
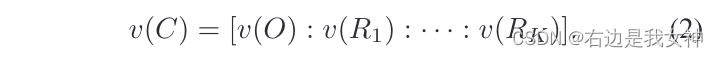
然后同样进行概率预测。最终的结果按照公式3进行平均:
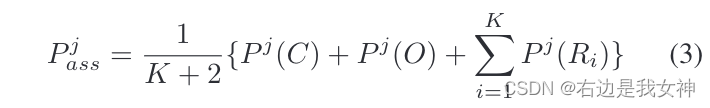
Filtration Learning with Discrimination Matching
为了实现RPN的端到端优化,本文创造性地提出了一种过滤学习方法,该方法利用提议-预测的辨别匹配能力作为RPN的性能度量。
提议-预测匹配性指的是,如果具有较高的置信度S(Ri)的判别区域应该匹配较高概率的分类结果P(Ri),因此,置信度得分呃和概率应在成对顺序和点值中保持一致的排名。
相应的,成对顺序损失函数被定义为:
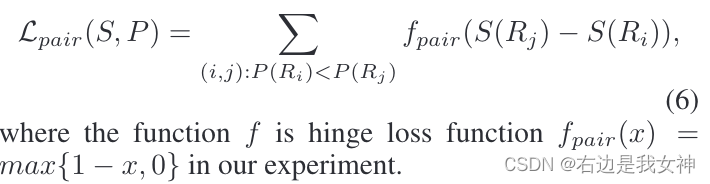
逐点值要求置信度得分和概率得分应该比较相似,这一要求定义为:

于是过滤学习的损失函数可以表示为:
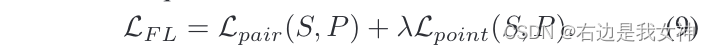
Distillation Learning with Knowledge Transferring
为了获得标签分布和类内的相关知识,本文提出了一种知识蒸馏的方法。
本文将基于对象的特征学习和基于区域的特征学习定义为“教师”和“学生”,并将所学知识从对象转换为基于区域的特性学习。
本文使用式子10,将每个局部区域的logit输出转化为一个软的概率分布:
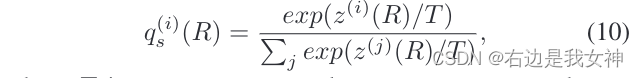
于是我们可以获得蒸馏学习的软目标交叉熵损失:
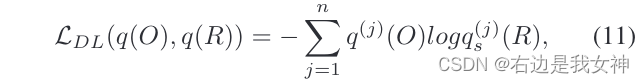
Filtration and Distillation Learnig

Interpretable and Accurate Fine-grained Recognition via Region Grouping
Abstract
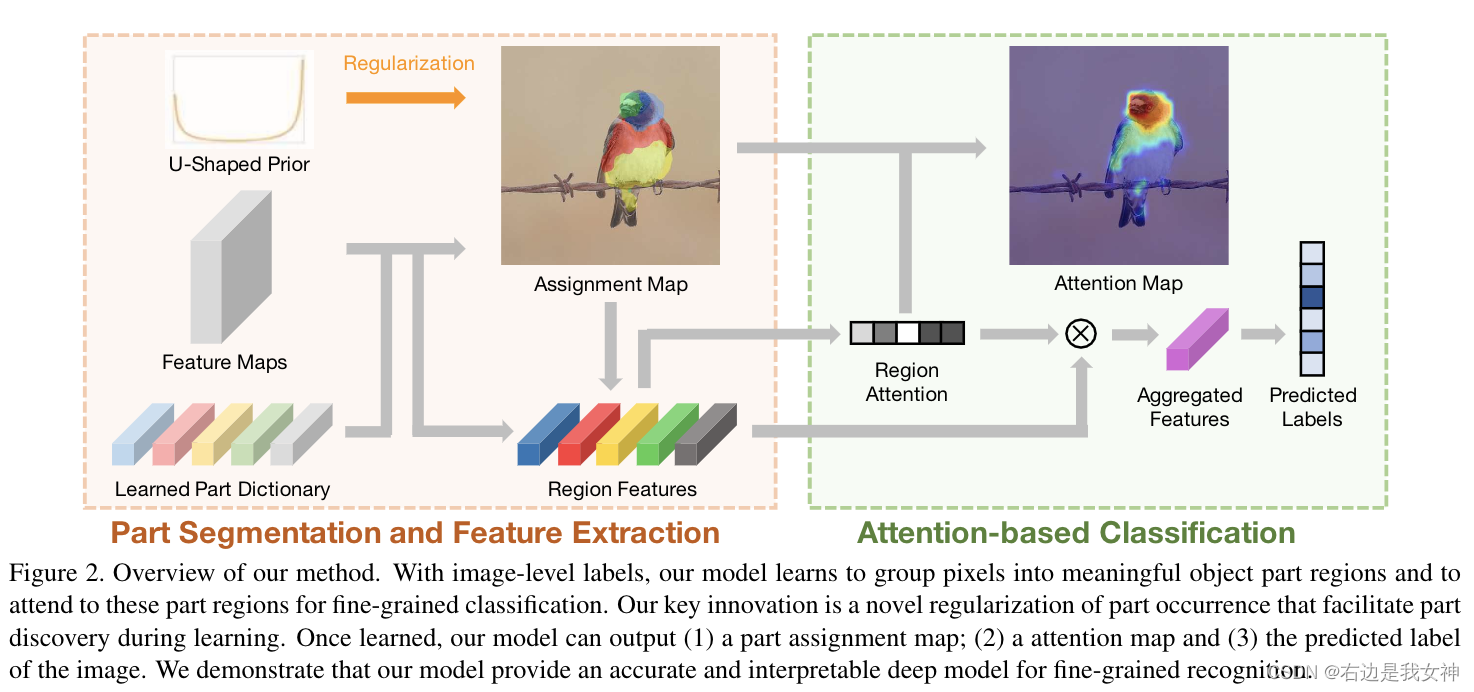
我们提出了一种用于细粒度视觉识别的可解释深度模型。
我们方法的核心是在深度神经网络中整合基于区域的零件发现和归因。我们的模型使用图像级对象标签进行训练,并通过对象部分的分割和识别它们对分类的贡献来解释其结果。
为了便于在没有直接监督的情况下学习对象部分,我们探索了对象部分出现的简单先验。我们证明,当将这一先验知识与基于区域的零件发现和归因相结合时,会产生一个可解释的模型,该模型保持高度准确。
Introduction
虽然模型的解释可能发生在多个方面,但我们认为,至少有一种解释模型的方法是分割对象部分的有意义的面部区域(例如,眼睛、嘴巴、脸颊、前脸和脖子),并进一步确定它们对决策的贡献(例如,嘴巴区域对微笑更有辨别力)。
part discovery:在不监督的情况下,学习目标零件。
我们的主要观察结果是,卷积网络的特征可用于将像素分组为一组视觉相干区域,从中可选择一组区分片段进行识别。只有对象标签作为指导的情况下,我们希望分组将有助于找到视觉上不同的部分,并且选择过程将确定它们对分类的贡献。
基于区域的part discovery的一个困难是没有明确的监督信号来定义这一区域。因此,必须结合有关先验知识来学习。
本文工作的一个核心创新是探索关于零件简单先验:给定一张图像,零件的出现遵循Beta分布(鸟的头部会出现在大多鸟类图像中)。本文阐释了这一先验在与part discovery结合时,会导致有意义的对象零件的识别。并且,可解释性的深度模型仍然是高度准确的。
具体来说,我们的模型学习对象零件的字典,基于该字典,2D特征图可以被分组为“零件”段。这是通过将像素特征与学习到的词典中的部分表示进行比较来实现的。
此外,基于区域的特征表示是从结果片段中池化得到的。之后通过注意力机制从片段中提取子集。
重要的是,在训练过程中,本文对每个部分的出现强制执行Beta分布,保证每个mini-batch中的样本都是二分类的。这样一种约束通过最小化先验分布和经验分布之间的Earth Mover’s Distance来实现的。
在训练期间,我们的模型仅由具有我们建议的正则化项的对象标签来监督。在测试期间,我们的模型联合输出目标部分的分段、分段部分的重要性和预测标签。对我们模型的解释是由部分分割和每个部分对分类的贡献所赋予的。
关于Beta分布,参考百度百科。
通过这一部分,首先本文通过字典的方式优化了特征表示;其次,在训练中对局部的出现近似了Beta分布,将局部的出现加入了先验知识。
Method

Regularization of Part Occurrence:
在描述上文提出了三个函数之前,我们首先关注主要的学习挑战。
因为唯一的监督信号是y,所以说确保字典D能够捕捉局部是很有挑战的。
我们的主要猜想是我们能够通过强迫一个先验的分布(局部的出现及其特征)来正则化这个学习。
Part Segmentation and Regularization
Part Assignment

这边的大概方法就是对每个像素与字典中的特征比对,以此确定每个像素属于哪一部分。
Part Occurrence
得到assignment矩阵之后,我们下一步骤时检测每一部分的出现。
一个简单的局部检测能够通过对k个分配图 Q k Q^k Qk执行一个max pooling操作来实现。
然而,我们发现在池化之前平滑这个分配图是有益的。本文使用一个高斯核来实现。
这样一种操作消除了特征图的离群点。我们的部分检测因此定义为: t k = max i , j g ∗ Q k t_k=\max_{i,j} g*Q^k tk=i,jmaxg∗Qk,其中g是二位的高斯核。进一步来说,k个局部检测器的输出被连接为一个出现向量 τ = [ τ 1 , τ 2 , . . . , τ N ] \tau=[\tau_1,\tau_2,...,\tau_N] τ=[τ1,τ2,...,τN]。
简而言之就是根据卷积图每个位置和字典中的特征进行比较,给出一个匹配度。
之后通过最大池化后,得到一张图的K个局部检测情况,以此判断这个图出现了几个局部。
这样一种出现是soft的,准确来说是一种概率的形式。
Regularization of Part Occurrence

文中给出了一种简化的计算方式,此处不过多赘述。
度量两个分布之间的距离的方法有很多,但是这个这边用的比较靠谱。
Region Feature Extraction and Attribution
给定局部的分配后,下一步是汇集每个区域的特征,此处通过非线性编码实现:

Attention based Classification
最终的预测结果如下所示:
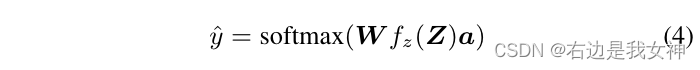
W表示一个线性分类器。
总结与思考
为什么是服从Beta分布?
Assignment Map应该是通过出现概率q的计算实现的,这不难理解。
每张图都会得到一个出现向量(max pooling),表示每个特征出现的一个情况。
关于为什么会服从Beta分布,文中也没细说。
Beta分布控制了每个特征出现的程度(以概率的形式),进一步控制特征的呈现情况。
字典怎么得到?
代码中有一个变量grouping_centers扮演着字典的作用,其实际上是nn.Parameters。
特征Z的计算为什么要这么操作?
引用非线性编码方案,文中有论文引用。
更像是距离的期望,体现了一种相似程度的度量。
不妨大胆假设一下,与特征差距过大的像素点的出现概率都近似为0,也就是这里只保留了局部附近的情况。
Implementation
Loss Function
损失函数包含了交叉熵分类损失和1D Wasserstein距离。
Attention Convolutional Binary Neural Tree for Fine- Grained Visual Categorization
Abstract
本文提出了一种注意力卷积二元神经树的弱监督方法来完成FGVC任务。
具体来说,本文沿着树结构的边缘合并卷积运算,并使用每个节点中的路由函数来确定根到叶的计算路径。
最终的判决被计算为来自叶节点的预测的综合。
深度卷积运算学习捕获对象的表示,树结构表征了由粗到细的层次特征学习过程。此外,本文还使用了注意力转化模块来加强网络以捕捉有区分度的特征。
Introduction
本文认为一些仅通过CNN来捕获微小差别的方法难以获得准确的结果(BCNN系列),反而捕获局部的思路比较靠谱,这边特别拿出了OPAM来举例。
受到Adaptive neural trees的启发,本文提出了attention convolutional binary tree结构。它沿树结构的边缘合并卷积运算,并使用每个节点中的路由功能来确定树内根到叶的计算路径,作为深度神经网络。这种设计的体系结构使得我们的方法继承了深度卷积模型的表示学习能力,以及由粗到细的分层特征学习过程。
以这种方式,树结构中的不同分支聚焦于不同的局部对象区域用于分类。最终决策是根据所有叶节点的预测总和计算得出的。同时,我们使用注意力转移器来加强树网络,以捕捉有区别的特征,从而获得准确的结果。采用负对数似然损失,通过具有反向传播的随机梯度下降,以端到端的方式训练整个网络。
本文给出的方法使用具有预先定义深度的完整二叉树结构和软判定方案来学习每条根到叶的路径中的区分度特征。
这样做的好处是避免了剪枝误差并减少了训练时间。
Attention Convolutional Binary Neural Tree
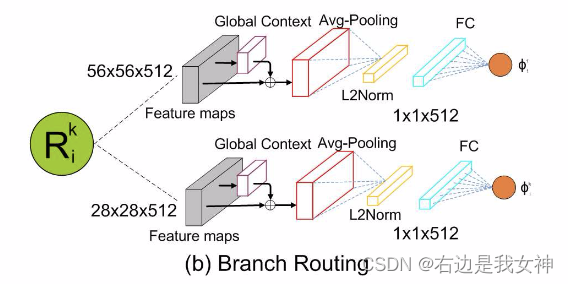
包含了四个模块,分别是backbone network、branch routing、attention transformer和label prediction modules。

本文在完全二叉树中使用非对称结构,即左边使用两个注意力转换器,在右边使用一个注意力转换器。
Architect
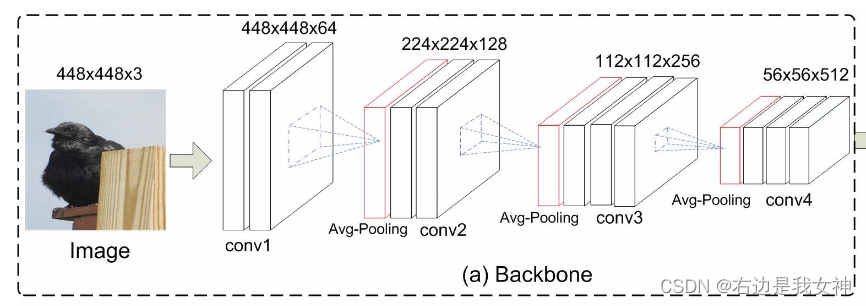
Backbone network module
由于细粒度类别中区分区域是高度局部化的,所以需要通过限制卷积滤波器和池化层的核的大小和步幅来使用相对小的感受野。
本文使用了VGG-16(保留了conv1_1到conv4_3)和ResNet-50(保留了res_1到res_4)来作为backbone。
Branch routing module

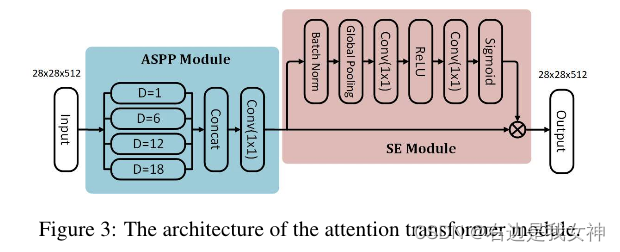
Attention transformer
attention transformer用于加强网络以捕捉有区别的特征。
根据深度网络中的经验感受野比理论感受野小的多的事实,有区分度的表征应该由本文提出的树结构中新增加层中的更大的感受野形成。
为此,本文将Atrous Spatial Pyramid Pooling中模块加入到注意力变换器中。
具体来说,ASPP模块提供了不同的特征图,每个特征图由不同尺度/感受野来表征。
然后,用四个不同扩张率的平行的扩张卷积生成多尺度特征图。在并行的扩张卷积层之后,级联的特征图通过一个1x1卷积进行融合。
最后,本文插入一个注意力模块,该模块生成一个大小为 R C × 1 × 1 R^{C\times 1\times1} RC×1×1的通道注意图。
Label prediction
对ACNet的每一个叶节点,本文使用都使用预测模型 P i P_i Pi来预测对象的子类别。

其中P的模型如图所示:
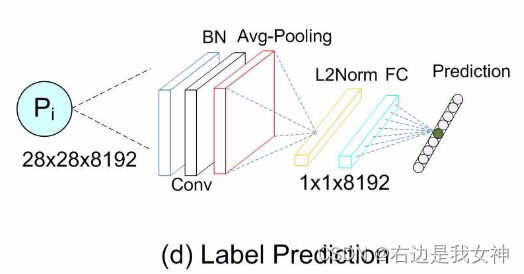
整体结构示意
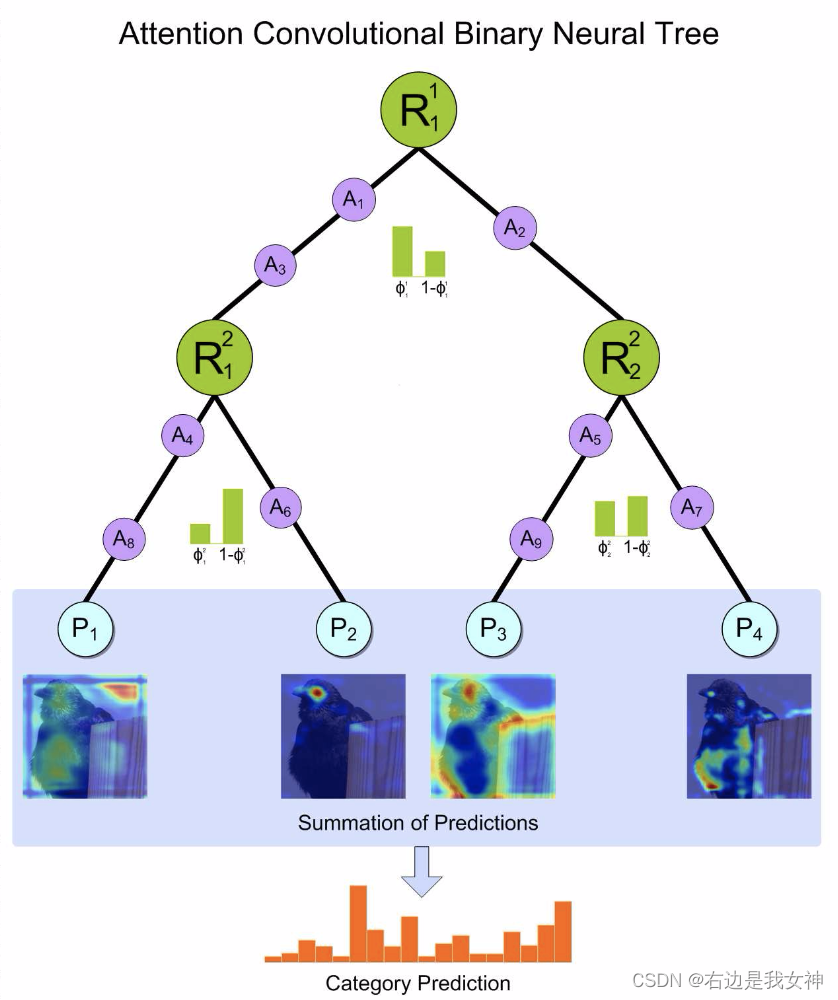
可以看到,模型依然会往两侧传递。概率较小的一方在随后的概率计算中也偏向于一个中庸的结果。
Training
数据增广
使用裁剪和翻转操作来扩充数据。
Loss function
损失函数与由两部分组成,分别是叶节点的预测损失和最终预测损失。
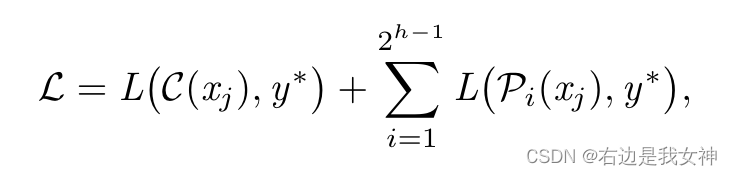
Graph-Propagation Based Correlation Learning for Weakly Supervised Fine-Grained Image Classification
Abstract
弱监督细粒度图像分类的关键是如何从中提取具有区分度的区域并学习区分特征。然而,最新的WFGIC方法独立地选择区分区域并直接利用它们的特征而忽略了区域的特征是相互语义相关的并且区域组可以获得更具区分性的事实。
为了解决这些问题,本文提出了一种基于端到端图传播的相关性学习(GCL)模型,以充分挖掘和开发WFGIC区域相关性和辨别能力。
具体来说,在定位阶段,本文提出了一个交叉图传播子网络来学习区域相关性,然后通过以交叉方式加权聚集其他区域来增强每个区域。
通过这种方式,每个区域的表示同时编码全局图像级上下文和局部空间级上下文,从而引导网络为WFGIC实现更强大的区分区域组。
在区分特征表示阶段,提出了相关特征增强(CFS)子网络,以探索区分快特征向量之间的内部语义相关性。