1、什么时候用?
针对同一类中不同子类进行分类
关注:扩大类内差距
- 语义分割(semantic segmentation)进行稠密预测(dense prediction)推断每个像素点的类标签,通过这种方式,区域或物体内的像素点被标记为相应的类别。
- 物体分割(instance segmentation):分别标记同一类的不同物体,甚至是基于部分的分割(part based segmentation),将已经分割出的类进一步分割为底层的组成部分。
2、本质:如何有效地对前景对象进行检测,并从中发现重要的局部区域信息
3、分类
基于强监督信息的细粒度图像分类模型 :
为了获得更好的分类精度,除了图像的类别标签外,还使用了物体标注框(object bounding box)和部位标注点(part annotation)等额外的人工标注信息

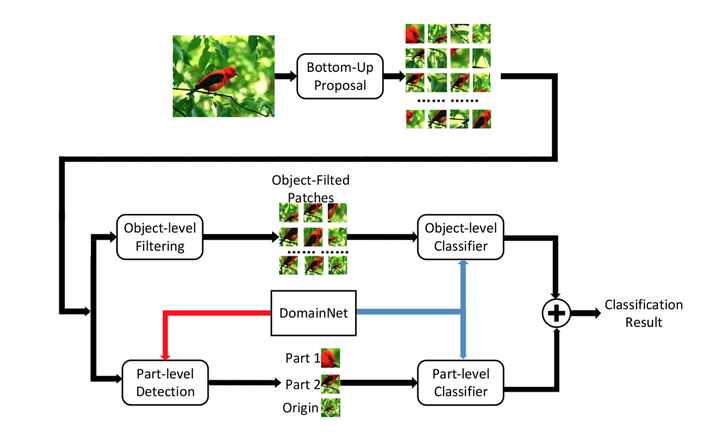
Part-based R-CNN [1]:
目标:对细粒度图像进行物体级别(如,鸟)与其局部区域(头、身体等部位)的检测

结果:1)借助细粒度图像中的object bounding box和part annotation可以训练出三个检测模型(detection model),一个对应细粒度物体级别检测,一个对应物体头部检测,另一个则对应躯干部位检测
2)对三个检测模型得到的检测框加上位置几何约束,例如,头部和躯干的大体方位、以及位置偏移不能太离谱等。这样便可得到较理想的物体/部位检测结果(如图右上)
3)将得到的图像块(image patch)作为输入,分别训练一个CNN,则该CNN可以学习到针对该物体/部位的特征。最终将三者的全连接层特征级联(concatenate)作为整张细粒度图像的特征表示
Pose Normalized CNN [3]:

结果:1)借助细粒度图像中的object bounding box和part annotation可以训练出三个检测模型(detection model),一个对应细粒度物体级别检测,一个对应物体头部检测,另一个则对应躯干部位检测
2)对三个检测模型得到的检测框加上位置几何约束,例如,头部和躯干的大体方位、以及位置偏移不能太离谱等。这样便可得到较理想的物体/部位检测结果(如图右上)
3)Pose Normalized CNN对部位级别图像块做了姿态对齐操作,并且针对细粒度图像不同级别的图像块(不同部位),提取不同层的卷积特征(例如,很对全局特征,提取了fc8的特征)
Mask-CNN [4]:
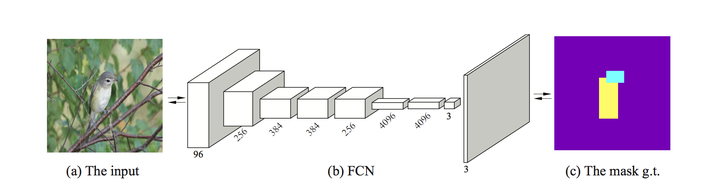
结果: 1、第一个实现端到端的训练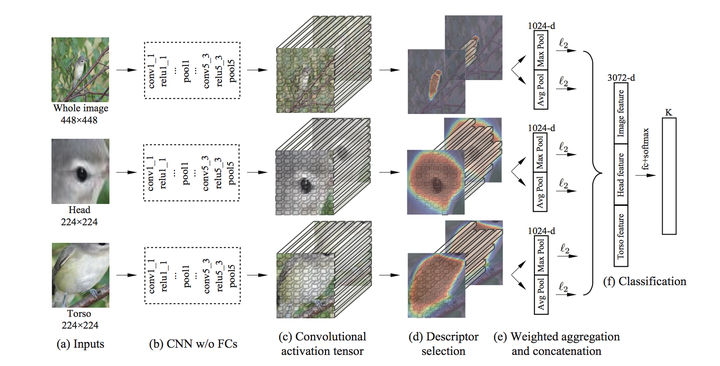
2、仅依靠训练时提供的part annotation(不需要bounding box,同时测试时不需额外监督信息)取得了目前细粒度图像分类最高的分类精度

2 、基于弱监督信息的细粒度图像分类模型 :
目标:希望在模型训练时仅使用图像级别标注信息,而不再使用额外的part annotation信息
- Two Level Attention Model [5]
说明:1、预处理模型:从输入图像中产生大量的候选区域,对这些区域进行过滤,保留包含前景物体的候选区域
2、候选区域大小不一,有些可能包含了头部,有些可能只有脚。此时对这些特征进行谱聚类,得到k个不同的聚类簇
Bilinear CNN [7]:
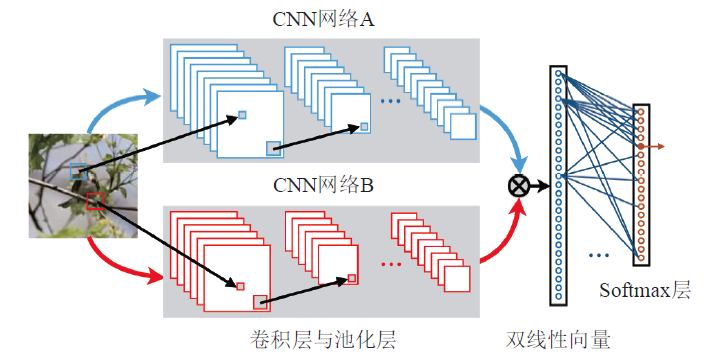
网络A:对物体进行定位, 即完成传统算法的对象与局部区域检测工作
网络B:对网络A检测到的物体位置进行特征提取
B=(fA,fB,P,C)B=(fA,fB,P,C),其中fA,fBfA,fB为来个不同的特征,P为Pooling操作,C表示分类器;对特征的每一个位置ll,进行如下计算。