一、简介
Elasticsearch 是用Java语言开发的,是目前全文搜索引擎的首选。它可以快速地储存、搜索和分析海量数据。Elasticsearch 的底层是开源库 Lucene。Elasticsearch 是 Lucene 的封装,提供了 REST API 的操作接口。
Elasticsearch 的实现主要分为以下几个步骤:
- 首先用户将数据提交到Elasticsearch 数据库中
- 再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据
- 当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户
1.1基本概念
- Near Realtime(NRT):近实时,两个意思,从写入数据到数据可以被搜索到有一个小延迟(大概1秒);基于es执行搜索和分析可以达到秒级
- Document&field:文档(就是一行数据),es中的最小数据单元,一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常用JSON数据结构表示,每个index下的type中,都可以去存储多个document。一个document里面有多个field,每个field就是一个数据字段。
- Type:类型(简单理解就是一张表),每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field,比如博客系统,有一个索引,可以定义用户数据type,博客数据type,评论数据type。
- Index:索引(简单理解就是一个数据库),包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。一个index包含很多document,一个index就代表了一类类似的或者相同的document。比如说建立一个product index,商品索引,里面可能就存放了所有的商品数据,所有的商品document。
- shard:单台机器无法存储大量数据,es可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储。有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。每个shard都是一个lucene index。
- replica:任何一个服务器随时可能故障或宕机,此时shard可能就会丢失,因此可以为每个shard创建多个replica副本。replica可以在shard故障时提供备用服务,保证数据不丢失,多个replica还可以提升搜索操作的吞吐量和性能。
primary shard(建立索引时一次设置,不能修改,默认5个),replica shard(随时修改数量,默认1个),默认每个索引10个shard,5个primary shard,5个replica shard,最小的高可用配置,是2台服务器。
每个document肯定只存在于某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard
primary shard不能和自己的replica shard放在同一个节点上,否则节点宕机,primary shard和副本都丢失,起不到容错的作用,但是可以和其他primary shard的replica shard放在同一个节点上
二、集群
2.1节点类型
Elasticsearch节点角色类型:
- Master节点:负责保存和更新集群的一些元数据信息,之后同步到所有节点,所以每个节点都需要保存全量的元数据信息,包括:集群的配置信息、集群的节点信息、模板template设置、索引以及对应的设置、mapping、分词器和别名、索引关联到的分片以及分配到的节点
- Voting节点:投票选举节点
- Data节点:数据节点,负责数据存储和查询
- Ingest节点,默认都是Ingest节点,它是数据前置处理转换的节点,在数据写入阶段,做一些前置处理,比如:如何在数据写入阶段修改字段名?如何在批量写入数据的时候,每条document插入实时时间戳?
- Coordinate节点,协调节点,负责路由索引请求、聚合搜索结果集、分发批量索引请
- Machine Learning节点,集群学习节点,可以进行数据统计和趋势分析
2.2集群模式
Elasticsearch集群要达到基本高可用,一般要至少启动3个节点,3个节点互相连接,单个节点包括所有角色,其中任意节点停机集群依然可用。为什么要至少3个节点?因为集群选举算法奇数法则。
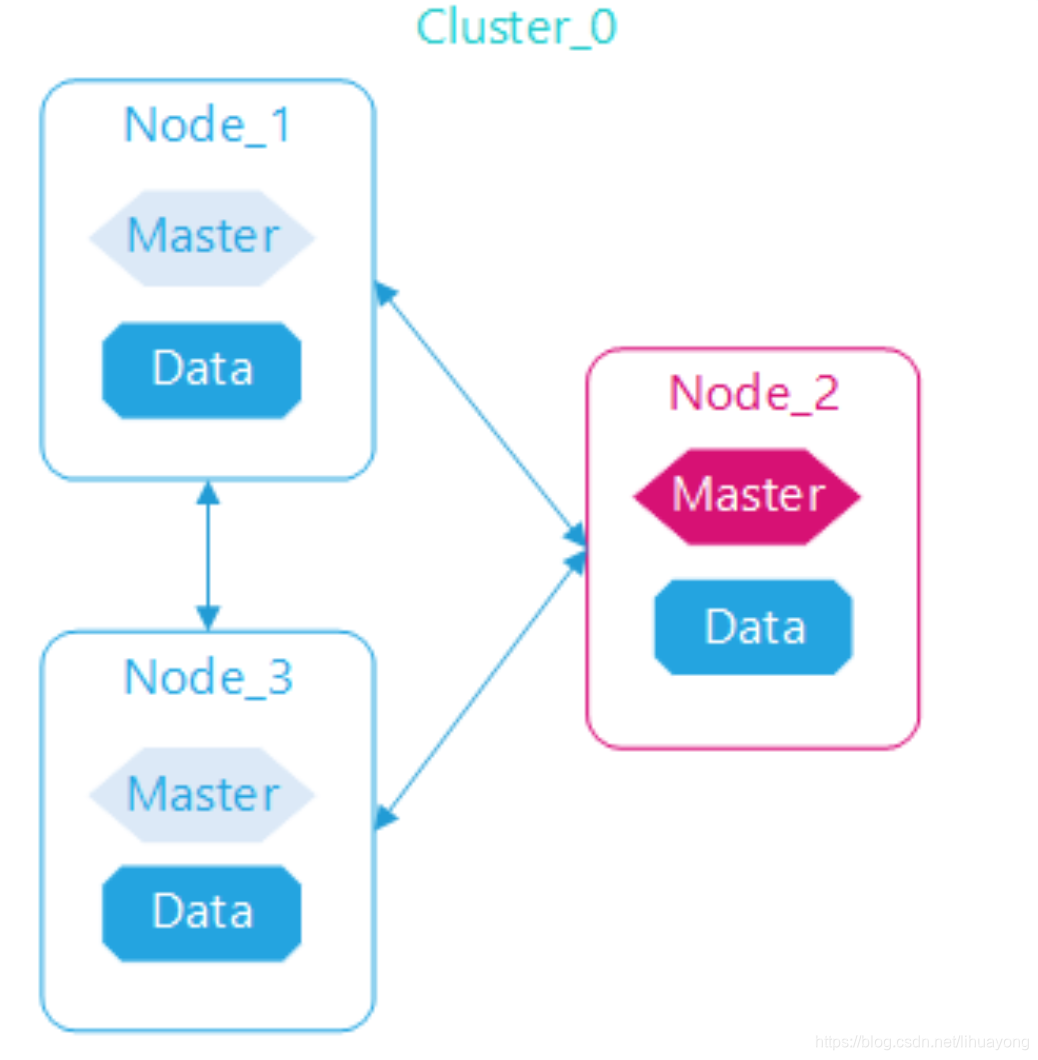
集群数据节点与管理节点分离:
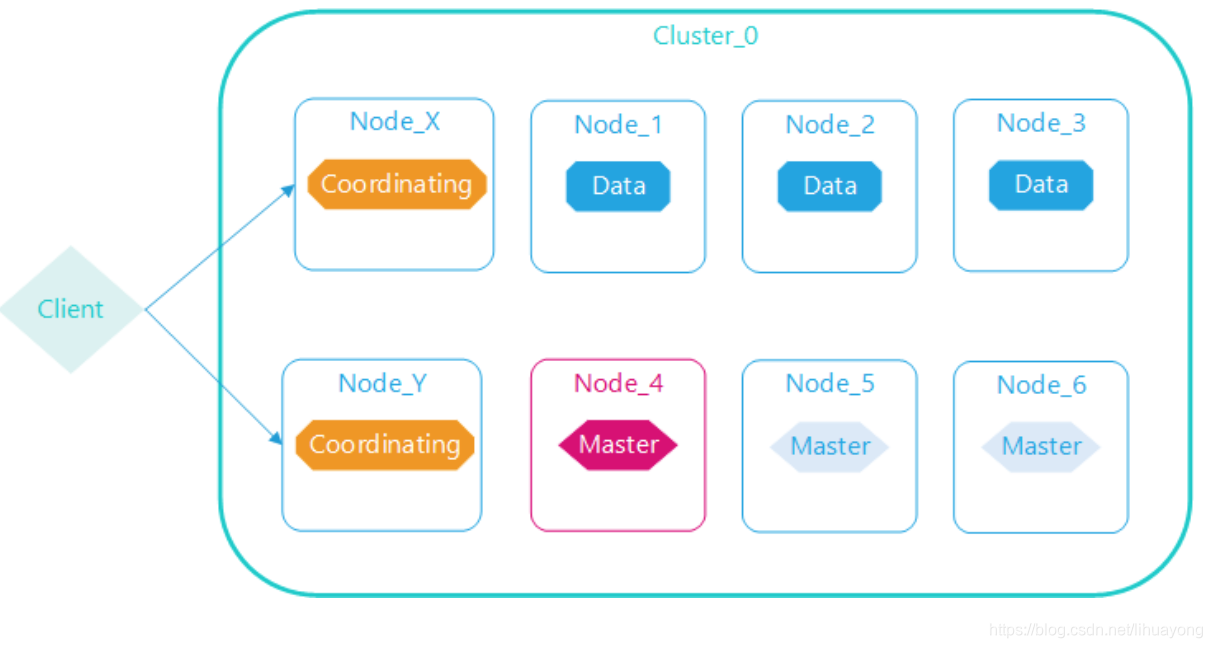
Elasticserach管理节点职责是管理集群元数据、索引信息、节点信息等,自身不设计数据存储与查询,资源消耗低;相反数据节点是集群存储与查询的执行节点。管理节点与数据节点分离,各司其职,任意数据节点故障或者全部数据节点故障,集群仍可用;管理节点一般至少启动3个,任意节点停机,集群仍正常运行。
Elasticsearch内部执行查询或者更新操作时,需要路由,默认所有节点都具备协调节点和数据节点的职能,特别是大的查询时,协调节点需要分发查询命令到各个数据节点,查询后的数据需要在协调节点合并排序,这样原有数据节点代价很大,所以分离职责,形成下面的数据、管理、协调分离的模式。
2.3master选举
2.3.1选举策略
- 如果集群中存在master,认可该master,加入集群
- 如果集群中不存在master,从具有master资格的节点中选id最小的节点作为master
2.3.2选举时机
- 集群启动:后台启动线程去ping集群中的节点,按照上述策略从具有master资格的节点中选举出master
- 现有的master离开集群:后台一直有一个线程定时ping master节点,超过一定次数没有ping成功之后,重新进行master的选举
2.3.3避免脑裂
考虑下面这种情况,原集群由 A、B、C、D、E 组成,主节点是 A。当两个交换机之间连接中断之后,A、B 不能再与C、D、E 进行通信,形成了两个网络分区。A、B 组成的集群中 master 仍然是 A,而C、D、E 会选出一个新的 master,客户端访问 A、B 或者高 C、D、E 时数据不一致。
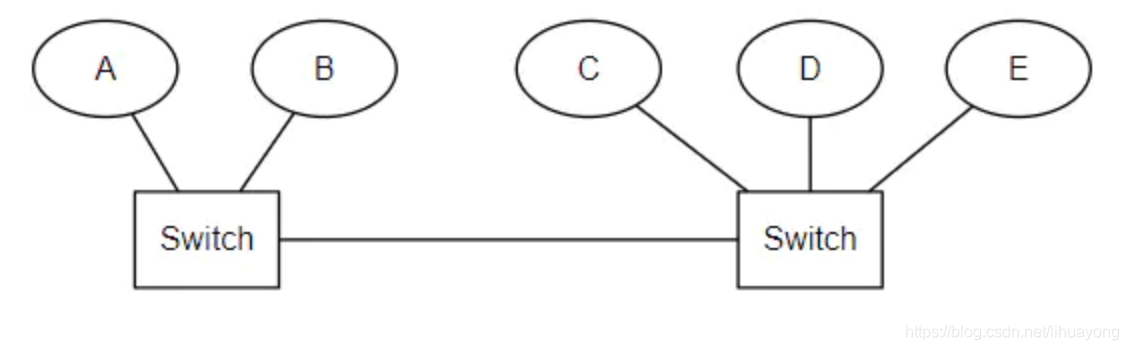
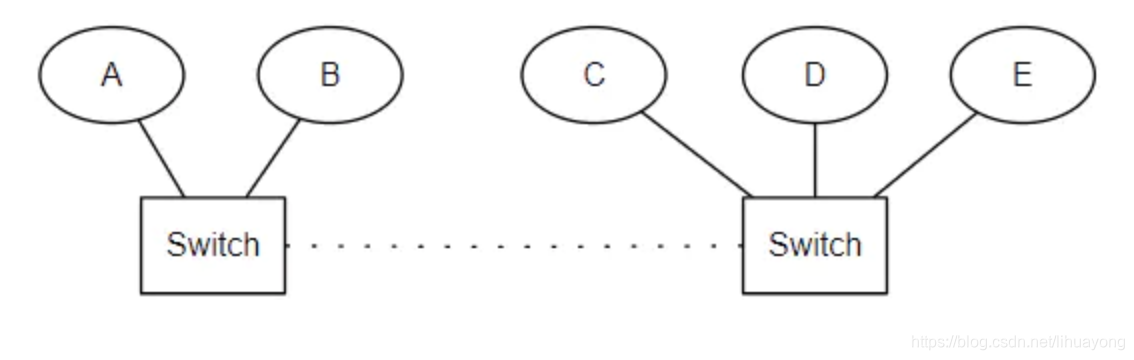
Elasticsearch 采用了设置 “法定得票人数过半” 解决,在选举过程中当节点得票达到 discovery.zen.minimum_master_nodes 的值时才能成为 master,这个值通常设定为:
minimum_master_nodes=(具有master资格节点数 / 2)+1。
将上例中 discovery.zen.minimum_master_nodes 设置为3。当两个交换机之间连接中断之后,A不能再与C,D,E进行通信,C、D、E所组成的网络分区中不存在活跃的master,因此发起选举。A的集群中只剩下A和B,不足minimum_master_nodes,因此放弃 master 身份。C、D、E进行投票,直到达成一致选出一个 master,形成一个新的集群,其中节点数量为 3,刚好满足 minimum_master_nodes,而A、B不再处理来自客户端的请求。
相关配置:
##一个节点多久ping一次,默认1s
discovery.zen.fd.ping_interval: 1s
##等待ping返回时间,默认30s
discovery.zen.fd.ping_timeout: 10s
##ping超时重试次数,默认3次
discovery.zen.fd.ping_retries: 3
##选举时需要的节点连接数,N为具有master资格的节点数量
discovery.zen.minimum_master_nodes=N/2+1
2.4负载均衡
ES集群是分布式的,数据分布到集群的不同机器上,对于ES中的一个索引来说,ES通过分片的方式实现数据的分布式和负载均衡。创建索引的时候,需要指定分片的数量,分片会均匀的分布到集群的机器中。分片的数量是需要创建索引的时候就需要设置的,而且设置之后不能更改,虽然ES提供了相应的api来缩减和扩增分片,但是代价是很高的,需要重建整个索引。
考虑到并发响应以及后续扩展节点的能力,分片的数量不能太少,假如你只有一个分片,随着索引数据量的增大,后续进行了节点的扩充,但是由于一个分片只能分布在一台机器上,所以集群扩容对于该索引来说没有意义了。
但是分片数量也不能太多,每个分片都相当于一个独立的lucene引擎,太多的分片意味着集群中需要管理的元数据信息增多,master节点有可能成为瓶颈;同时集群中的小文件会增多,内存以及文件句柄的占用量会增大,查询速度也会变慢。
2.5数据副本
ES通过副本分片的方式,保证集群数据的高可用,同时增加集群并发处理查询请求的能力,相应的,在数据写入阶段会增大集群的写入压力。
数据写入的过程中,首先被路由到主分片,写入成功之后,将数据发送到副本分片,为了保证数据不丢失,最好保证至少一个副本分片写入成功以后才返回客户端成功。
三、数据写入

3.1大致流程
- 客户端选择一个node发送请求到集群某个node,这个node就作为协调节点
- 协调节点对document进行路由,将请求转发给主分片所在的node
- 实际上的node上的主分片处理请求,然后将数据同步到副本分片
- 协调节点如果发现主分片和所有的副本分片都搞定之后,就会返回请求给客户端
3.2关键流程
- 数据先写入到buffer里面,在buffer里面的数据是搜索不到的,同时将数据写入到translog日志文件之中
- 如果buffer快满了,或是一段时间之后(定时),就会将buffer数据refresh到OS cache之中,在OS cache中,数据是以一个segment文件形式存在,就代表这个数据可以被搜索到。还可以通过restful api 和Java api,手动的执行一次refresh操作,手动的将buffer中的数据刷入到OS cache之中,让数据立马搜索到,执行refresh之后,buffer的内容就会被清空。
- 重复以上的操作,每次数据写入buffer,同时会写入一条日志到translog日志文件之中去,默认的是每隔30分钟进行一次commit,但是这个translog文件会不断的变大,当达到一定的程度之后,也会触发commit操作。
- 执行commit操作,将一个commit point写入到磁盘文件,里面标识着这个commit point 对应的所有segment file,commit操作会强行将OS cache 之中的数据都fsync到磁盘文件中去。
- 将现有的translog文件进行清空,然后在重新启动一个translog,此时commit就算是成功了,整个commit过程就叫做一个flush操作,我们也可以通过ES API,手动执行flush操作,手动将OS cache 的数据fsync到磁盘上面去,记录一个commit point,清空translog文件
- 如果是删除操作,commit的时候会产生一个.del文件,里面讲某个doc标记为delete状态,那么搜索的时候,会根据.del文件的状态,就知道那个文件被删除了。
- 如果是更新操作,就是讲原来的doc标识为delete状态,然后重新写入一条数据即可。
- 每次refresh的时候,都会在文件系统缓冲区中生成一个segment,所以,随着数据的写入,尤其是refresh的时间设置的很短的时候,磁盘中会生成越来越多的segment,定期执行merge操作,每次merge的时候,就会将多个segment file 文件进行合并为一个,同时将标记为delete的文件进行删除,然后将新的segment file 文件写入到磁盘,这里会写一个commit point,标识所有的新的segment file,然后打开新的segment file供搜索使用。
3.3translog的作用
在执行commit之前,所有的而数据都是停留在buffer或OS cache之中,无论buffer或OS cache都是内存,一旦这台机器死了,内存的数据就会丢失,所以需要将数据对应的操作写入一个专门的日志问价之中,一旦机器出现宕机,再次重启的时候,es会主动的读取translog之中的日志文件的数据,恢复到内存buffer和OS cache之中。
translog的数据也是先写入到OS cache之中的,默认每隔5秒之中将数据刷新到硬盘中去,也就是说,可能有5秒的数据仅仅停留在buffer或者translog文件的OS cache中,如果此时机器挂了,会丢失5秒的数据,但是这样的性能比较好,我们也可以将每次的操作都必须是直接fsync到磁盘,但是性能会比较差。
3.4segment段文件优缺点
os cache 和磁盘中的segment file段文件,具有不可变性的特点,一旦生成,就不能变更
优点如下
- 不需要锁:因为数据不会更新,所以不用考虑多线程下的读写不一致情况。
- 可以常驻内存:段在被加载到内存后,由于具有不变性,所以只要内存的空间足够大,就可以长时间驻存,大部分查询请求会直接访问内存,而不需要访问磁盘,使得查询的性能有很大的提升。
- 缓存友好:在段的声明周期内始终有效,不需要在每次数据更新时被重建。
- 增量创建:分段可以做到增量创建索引,可以轻量级地对数据进行更新,由于每次创建的成本很低,所以可以频繁地更新数据,使系统接近实时更新。
缺点如下
- 删除:当对数据进行删除时,旧数据不会被马上删除,而是在 .del文件中被标记为删除。而旧数据只能等到段更新时才能真正地被移除,这样会有大量的空间浪费。
- 更新:更新数据由删除和新增这两个动作组成。若有一条数据频繁更新,则会有大量的空间浪费。
- 新增:由于索引具有不变性,所以每次新增数据时,都需要新增一个段来存储数据。当段段数量太多时,对服务器的资源(如文件句柄)的消耗会非常大,查询的性能也会受到影响。
- 过滤:在查询后需要对已经删除的旧数据进行过滤,这增加了查询的负担。
3.5segment段合并
如果每次合并全部的段,则会造成很大的资源浪费,特别是“大段”的合并。所以 Lucene 现在的段合并思路是:根据段的大小将段进行分组,再将属于同一组的段进行合并。
但是由于对于超级大的段的合并需要消耗更多的资源,所以 Lucene 会在段的大小达到一定规模,或者段里面的数据量达到一定条数时,不会再进行合并。
Lucene 的段合并主要集中在对中小段的合并上,这样既可以避免对大段进行合并时消耗过多的服务器资源,也可以很好地控制索引中段的数量。
merge的过程大致描述如下:
- 磁盘上两个小segment:A和B,内存中又生成了一个小segment:C
- A,B被读取到内存中,与内存中的C进行merge,生成了新的更大的segment:D
- 触发commit操作,D被fsync到磁盘
- 创建新的提交点,删除A和B,新增D
- 删除磁盘中的A和B
segment段合并的具体算法参考:懂Elasticsearch文章的段合并策略章节
四、倒排索引
4.1倒排索引例子
以下面的原始数据为例:
| docId | 姓名 | 年龄 | 性别 |
|---|---|---|---|
| 1 | Kate | 24 | 女 |
| 2 | John | 24 | 男 |
| 3 | Bill | 29 | 男 |
几个概念:
- document:每一行是一个 document,每个 document 都有一个 docId,即文档 ID
- term:每一个field字段里面的取值,就是一个term,比如年龄24,29,姓名John、Bill这些叫做一个term,term是搜索的关键字
以姓名这个字段为例,给姓名创建一个倒排索引,结构如下:

几个概念:
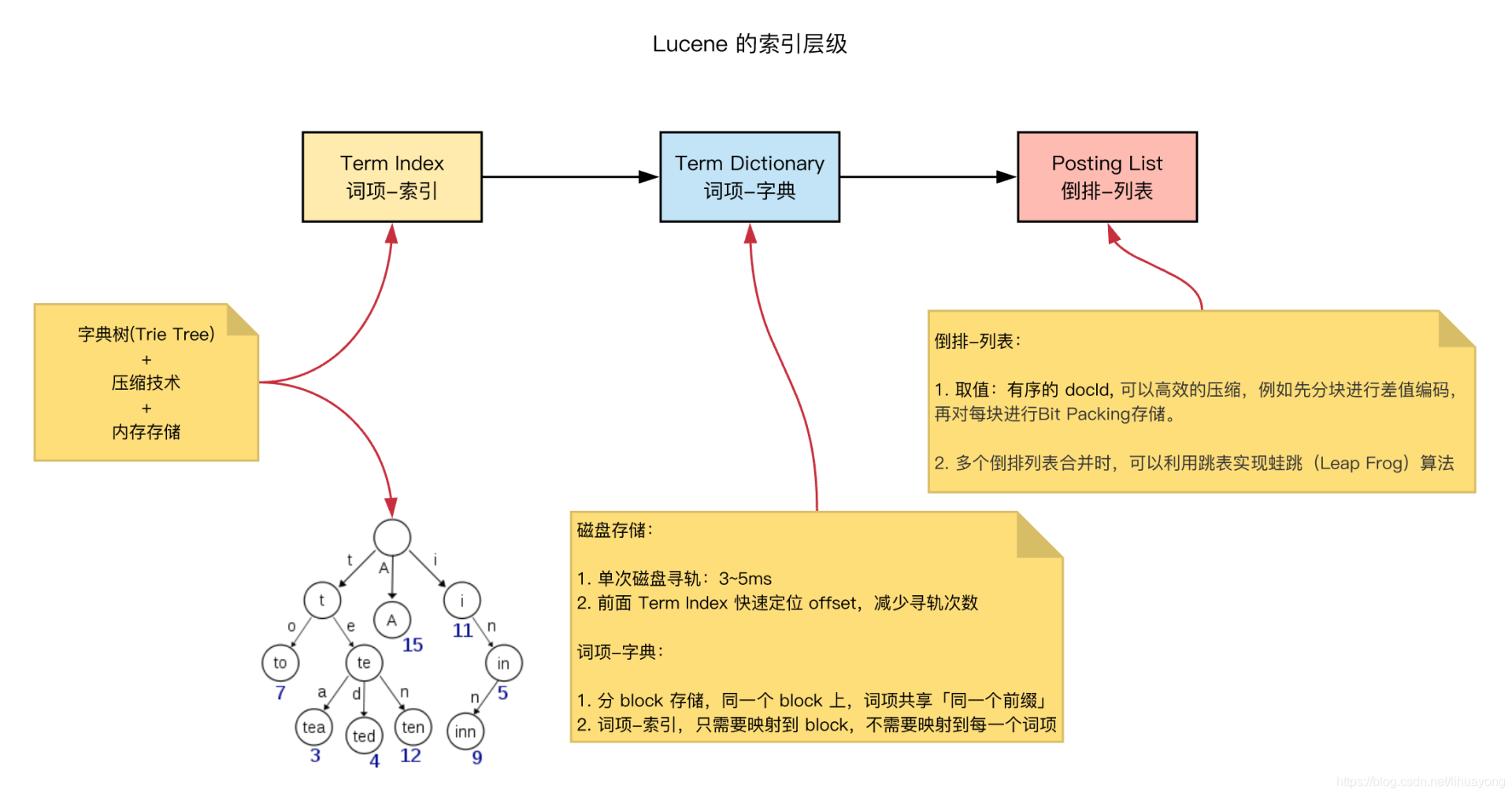
- 词项索引term index:一种树形结构
1. 使用技术:字典树(Trie Tree)、压缩技术、内存存储 2. 目标: 时间复杂度O(m),定位term dictionary对应 block 的 offset 3. 注意:词项索引,只需要映射到 block,不需要映射到每一个词项 - 词项字段term dictionary:有序的term集合
1. 使用技术:分 block 存储,同一个 block 上,term共享同一个前缀 2. 目标:定位到最终的 term - 倒排表posting list:就是一个数据集合,存储了所有符合某个 term 的doc id
1. 使用技术:分块差值编码,再对每块进行 bit 压缩存储。 2. 目标:有序 docId,高效压缩,放入内存
4.2term dictionary
假设我们有很多个 term,比如:
Carla,Sara,Elin,Ada,Patty,Kate,Selena
如果按照这样的顺序排列,找出某个特定的 term 一定很慢,因为 term 没有排序,需要全部过滤一遍才能找出特定的 term。排序之后就变成了:
Ada,Carla,Elin,Kate,Patty,Sara,Selena
这样我们可以用二分查找的方式,比全遍历更快地找出目标的 term。这个就是 term dictionary。term dictionary:词项字典,其为有序的字典,正常情况,二分查找,查询效率 O(logN)。
有了 term dictionary 之后,可以用 logN 次磁盘查找得到目标。但是磁盘的随机读操作仍然是非常昂贵的,一次 random access 大概需要 10ms 的时间。所以尽量少的读磁盘,有必要把一些数据缓存到内存里。但是整个 term dictionary 本身又太大了,无法完整地放到内存里。
所以需要进一步的处理,建立词典索引(term index)。通过词典索引可以直接找到搜索词在词典中的大致位置,然后从磁盘中取出词典数据再进行查找。所以大致的结构图就变成了这样:

4.3term index
term index 有点像一本字典的大的章节表。比如:
A 开头的 term …………… xxx 页
C 开头的 term …………… xxx 页
E 开头的 term …………… xxx 页
实际的 term index 是一棵 trie 树(字典树):

例子是一个包含 “A”, “to”, “tea”, “ted”, “ten”, “i”, “in”, 和 “inn” 的 trie 树。这棵树不会包含所有的 term,它包含的是 term 的一些前缀。再结合FST的压缩技术,可以使整个term index缓存到内存中。从term index查到对应的term dictionary的block的offset之后,从这个位置再往后顺序查找,大大减少了磁盘随机读的次数。
4.4FST压缩
假设我们现在要将mop, moth, pop, star, stop and top(term index里的term前缀)映射到序号:0,1,2,3,4,5(term dictionary的block的offset)。最简单的做法就是定义个Map<string, integer="">,大家找到自己的位置对应入座就好了,但从内存占用少的角度想想,有没有更优的办法呢?答案就是:FST

圆圈〇表示一种状态,→表示状态的变化过程,上面的字母/数字表示状态变化和权重。
将单词分成单个字母通过〇和→表示出来,0权重不显示。如果〇后面出现分支,就标记权重,最后整条路径上的权重加起来就是这个单词对应的序号。
根据FST构建算法,最终我们得到如上一个有向无环图。利用该结构可以很方便的进行查询,如给定一个term “pop”,我们可以通过上述结构很方便的查询存不存在,甚至我们在构建过程中可以将单词与某一数字、单词进行关联,从而实现key-value的映射。
这种压缩方式可以有效的缩减存储空间,使得term index足以放进内存,但这种方式也会导致查找时需要更多的CPU资源。
具体构建和查询算法参考:关于Lucene的词典FST深入剖析
4.5倒排表压缩
倒排表压缩采用了一种【增量编码压缩,大数变小数】的压缩存储算法,先看看增量编码压缩,将大数变小数,按字节存储的一个例子:
比如现在有id列表[73, 300, 302, 332, 343, 372],转化成每一个id相对于前一个id的增量值(第一个id的前一个id默认是0,增量就是它自己)列表是[73, 227, 2, 30, 11, 29]。在这个新的列表里面,所有的id都是小于255的,所以每个id只需要一个字节存储。
实际上ES会做的更加精细,它会把所有的文档分成很多个block,每个block正好包含256个文档,然后单独对每个文档进行增量编码,计算出存储这个block里面所有文档最多需要多少位来保存每个id,并且把这个位数作为头信息(header)放在每个block 的前面。
比如对上面的数据进行压缩(假设每个block只有3个文档而不是256),压缩过程如下:
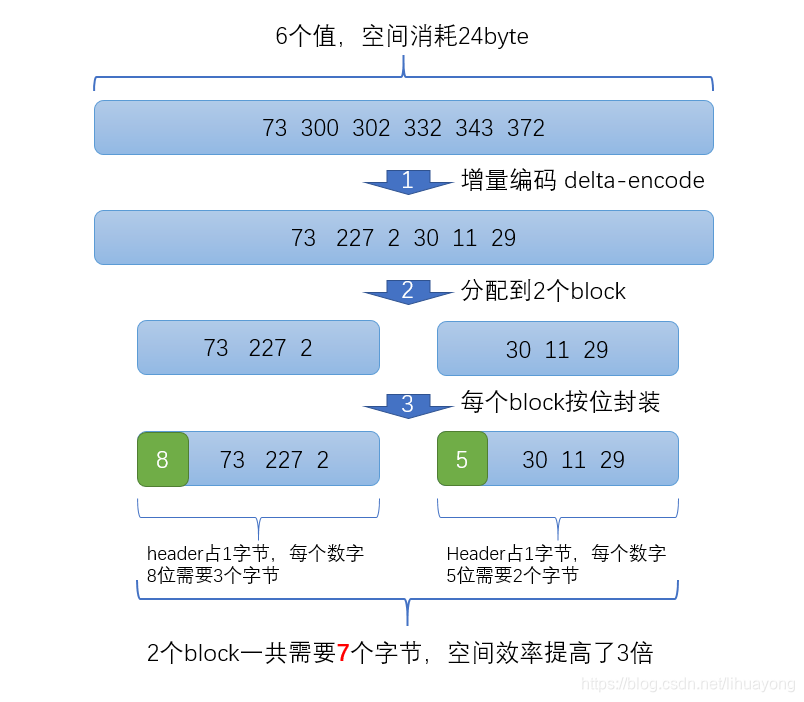
上面这个例子的最后一层,将开始的数据集合分成了两个block,每一个block里面的数据都是按照bitmap位来存储,
bitmap就是用比特位表示数据,看下面的例子:
倒排表Posting List:[1, 2, 4, 7, 10] 对应的bitmap [1, 1, 0, 1, 0, 0, 1,0, 0, 1],取最大的值10,那么就用10个比特表示这组Posting List,第1, 2, 4, 7, 10位存在,就将相对应的“位”置为1,其他的为0。但这种bitmap数据结构有缺陷,看这组Posting List: [1, 3, 100000000] 对应的bitmap [1, 0, 1, 0, 0, 0, …, 0, 0, 1 ],最大数是1亿,就要1亿的比特表示,这么算下来,反而消耗了更多的内存。Bitmap的缺点是存储空间随着文档个数线性增长。
那如何解决这个问题,采用Roaring bitmaps,Roaring Bitmap是由short数组和bitmap这两个数据结构改良过的成果,对于每一个block里面的数据,根据doc id数量分成两类:
1、如果docid数量小于4096个,就是用short数组保存
2、如果docid数量大于等于4096个,就使用bitmap保存
接着我们看看ES是怎么利用【增量编码压缩,大数变小数】的压缩方法,先看一张图
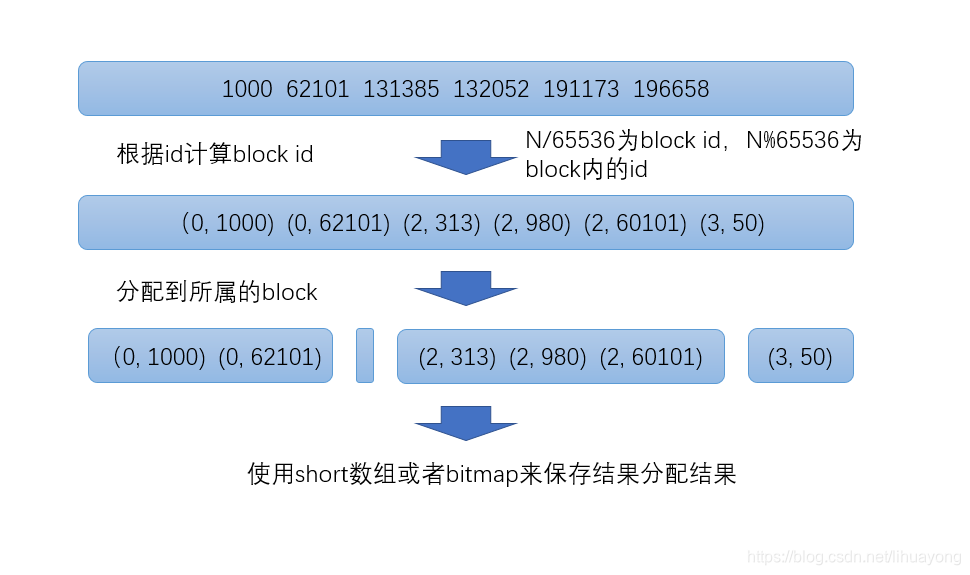
- 第一步:将每个数除以65536,得到(商,余数)
- 第二步:按照商,分成不同的block,也就是相同的商,放在同一个block里面,余数就是这个值在这个block里面的位置,余数永远不会超过65536
- 第三步:判断底层block用什么数据结构存储数据,如果block里面的余数的个数小于4096个,就用short[]存储,反之个数大于等于4096个,则用bitmap存储。
至于为什么是4096这个分界线?首先每一个block中的数据个数,都不会超过65536个,假设正好是65536个,如果采用bitmap来存储,需要65536个bit位,也就是2^16=65536个 bit ,也相当于是65536/8bit=8kb的存储空间,那么这8kb的存储空间需要多少个short类型呢?每一个short类型是2byte,2byte*4096=8kb,也正好是8kb的存储空间,所以为了节省存储空间,block中数量小于 4096个,就用 Short 类型的有序数组来存储值,因为占用的空间小于8kb。若大于4096个,就用 Bitmap来存储值。
总结下来,Posting List倒排表采用了,两种压缩算法,一种是【增量编码压缩,大数变小数】,第二种就是按照short[]和bitmap存储。
五、DocValues
5.1正向索引&倒排索引
在ElasticSearch中每个文件都对应一个文件ID,文件内容被表示为一系列关键词的集合。例如“文档1”经过分词,提取了20个关键词,每个关键词都会记录它在文档中的出现次数和出现位置
得到正向索引的结构如下:
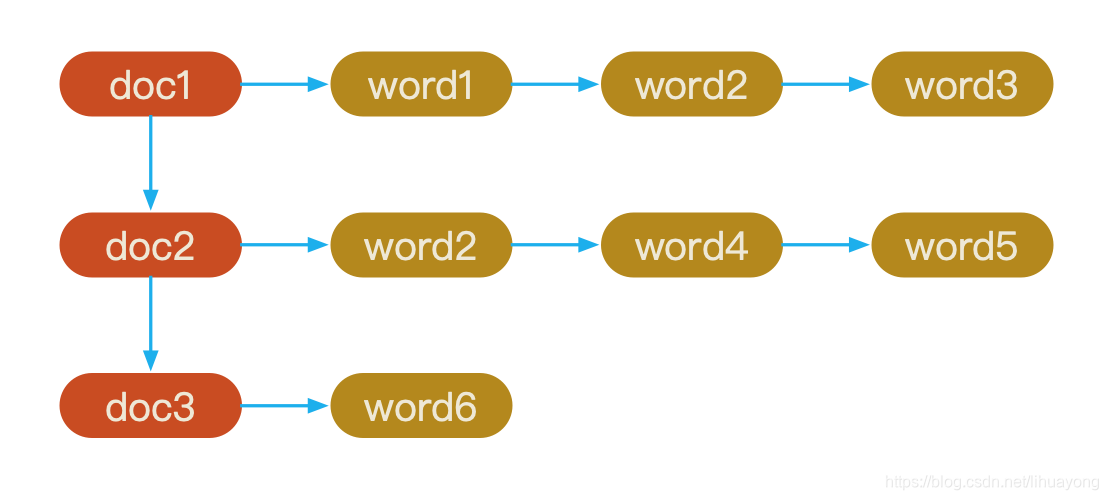
当用户搜索关键词“word4”时,在正向索引下,就需要扫描所有文档,找出所有包含关键词“word4”的文档,由于一般在搜索引擎中的文档的数目是个天文数字,这样的索引结构根本无法满足实时返回结果的要求。
所以,搜索引擎会将正向索引重新构建为倒排索引,即把文件ID对应到关键词的映射转换为关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词。
得到倒排索引的结构如下:
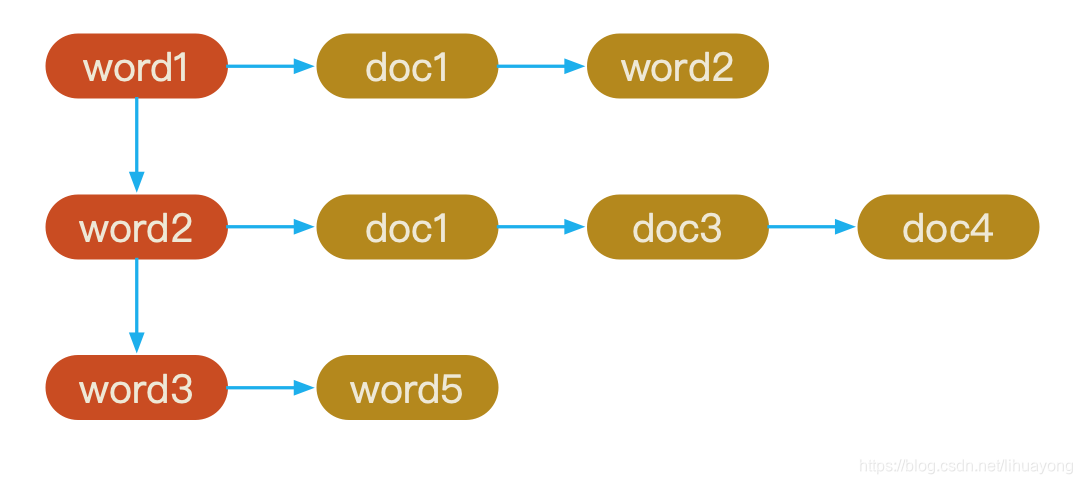
从词的关键字,去找文档,这种情况下,搜索关键字的效率会很高,满足搜索引擎的业务场景。
虽然每个字或词对应的文档数量在动态变化,所以倒排表的建立和维护都较为复杂,但是在查询的时候由于可以一次得到查询关键字所对应的所有文档,所以效率高于正排表。
5.2DocValues
上面的倒排索引满足了关键字搜索的效率,但是对于从另外一个方向的相反操作并不高效,比如聚合(aggregations)、排序(Sorting)和字段的全值查询等时候需要其它的访问模式。
我们首先想到的是遍历正向索引来进行统计。但是这很慢而且难以扩展:
随着词项和文档的数量增加,执行时间也会增加。
为了能够解决上述问题,我们使用了Doc values通过转置两者间的关系来解决这个问题。
举例:
Doc1含有关键字:China,India
Doc2含有关键字:Love,You
Doc3含有关键字:Hello
doc_values表如下:

倒排索引保存的是词项到文档的映射,也就是词项存在于哪些文档中,DocValues保存的是文档到词项的映射,也就是文档中有哪些词项。
DocValues是在索引时与倒排索引同时生成的,并且是不可变的。与倒排一样,保存在lucene文件中(序列化到磁盘),此值默认是启动状态,如果没有必要使用可以设置 doc_values: false来禁用。
Doc values 是不支持 analyzed 字符串字段的,想象一下,如果一个字段是analyzed,如the first,则在分析阶段则会docvalues则会存储为两条docvalue(the和first),计算时候则会得到

而非

对于DocValues的查找,关键在于DocIDSet中ID的查找,如果按照简单的链表的查找逻辑,那么DocID的查找速度将会很慢。lucene7借用了RoaringBitmap的分片的思想来加快DocIDSet的查找速度:

- 分片容量为2的16次方,最多可以存储65536个docid
- 分片包含的信息:分片ID;存储的docid的个数(值不为空的DocIDSet);DocIDSet明细,或者标记分片类型(ALL或者NONE)
- 根据分片的容量,将分片分为四种不同的类型,不同类型的查找逻辑不通:ALL:该分片内没有不存在值的DocID;NONE:该分片内所有的DocID都不存在值;SPARSE:该分片内存在值的DocID的个数不超过4096,DocIDSet以short数组的形式存储,查找的时候,遍历数组,找到对应的ID的位置;DENSE:该分片内存在值的DocID的个数超过4096,DocIDSet以bitset的形式存储,ID的偏移量也就是在该分片中的位置
最终DocIDSet的查找逻辑为:
- 计算DocID/65536,得到所在的分片N
- 计算前面N-1个分片的DocID的总数
- 找到DocID在分片N内部的位置,从而找到所在位置之前的DocID个数M
- 找到N+M位置的value即为该DocID对应的value
六、数据查询
查询过程
- 协调节点将请求发送给对应分片
- 分片查询,返回from+size数量的文档对应的id以及每个id的得分
- 汇总所有节点的结果,按照得分获取指定区间的文档id
- 根据查询需求,向对应分片发送多个get请求,获取文档的信息
- 返回给客户端
主分片与副本分片
采用了基于负载的请求路由,基于队列的耗费时间自动调节队列长度,负载高的节点的队列长度将减少,让其他节点分摊更多的压力,搜索和索引都将基于这种机制。
get查询的实时性
ES数据写入之后,要经过一个refresh操作之后,才能够创建索引,进行查询。但是get查询很特殊,数据实时可查。
get查询的实时性,通过每次get查询的时候,如果发现该id还在内存中没有创建索引,那么首先会触发refresh操作,来让id可查。
参考:
- 进阶篇集群+原理:对ES的基本概念和原理做了简单介绍
- 基础介绍及索引原理分析:分析倒排索引,分析term index的压缩算法和posting list的压缩算法
- Lucene的词典FST深入剖析:FST算法作为分析term index的压缩算法,单纯对算法讲解
- 掌握它才说明你真正懂Elasticsearch:对ES的读写过程和概念进行介绍
- 从原理到应用,Elasticsearch详解:介绍ES架构、存储、查询、索引
- Elasticsearch集群模式知多少
- Elasticsearch 选主流程