手拉手初探机器学习(一)EDA数据探索性分析与学习
前言
- 好久没更新博客,也意味着自己很久没静下心来学习新东西。研二一年基本时间都用来参加比赛,有一些收获,但是后期深感自己的无知和浅薄,略显乏力。在就业之前,希望能够再学一些真正有用的东西:ROS2、Linux嵌入式开发还有此处的机器学习,哪怕只是了解了解呢,关键的学习过程会抽时间更新到github和博客的。
文章思路主要参考:
【1】Kaggle经典项目——房价预测
【2】探索性数据分析EDA(一)——变量识别与分析
【3】学校数学建模培训课程
从之前了解的机器学习的整个流程来看:数据处理、特征选择、模型选择、模型训练、模型测试、模型预测。似乎并没有侧重EDA的过程,这或许是刚开始上手学习的数据几乎都是被处理过的原因,对于实际的大部分数据来说,数据的趋势和情况是很难被我们直接看出来的。所以,EDA(Exploratory Data Analysis)数据探索性分析,实际数据分析问题中应该是我们需要做的第一步。位置在数据处理之前,或者归属于数据处理的第一步?总的来说,个人理解的EDA作用就是开始处理数据之前更清晰的了解数据,主要功能为:
- 数据的整体概括
- 数据的分布情况
- 数据的相关性情况
- 可视化分析
这里我使用kaggle经典项目房价预测数据集进行学习分析,数据集和代码可在本人github:GITHUB处自行下载。
1、库导入
#导入数据库
import numpy as np
import pandas as pd
%matplotlib inline
import matplotlib.pyplot as plt
import missingno as mnso
import seaborn as sns
color = sns.color_palette()
sns.set_style('darkgrid')
2、数据导入
#train = pd.read_csv('dataset\\train.csv')#利用pandas包进行文件数据导入
train = pd.read_csv('./dataset/train.csv')#两种文件路径读取方法
test = pd.read_csv('./dataset/test.csv')
3、数据规模、类型、分布情况
3.1 数据规模查看
print('训练集数据的规模:', train.shape)
print("----------------------------------")
print('测试集数据的规模:', test.shape)
test.head()#展示前五行
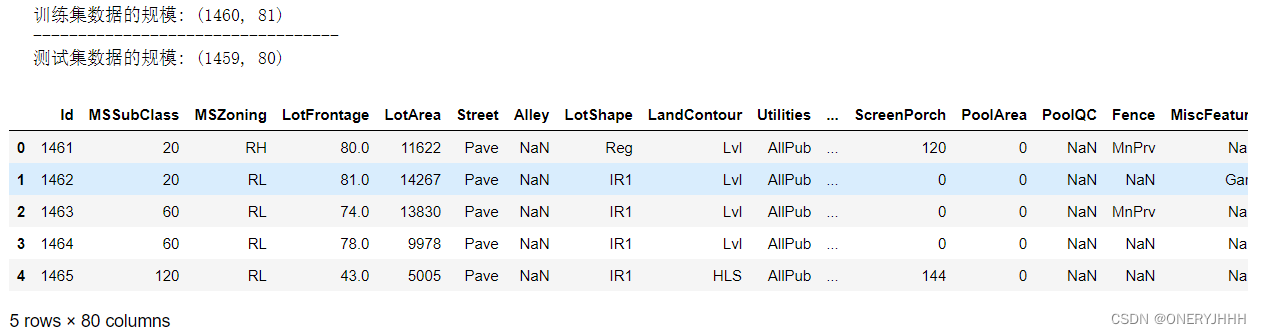
因此,本数据集中,训练集共有1460条记录,特征数为81个;测试集共有1459个,特征数为80个(训练集已包含了标签列)
3.2 数据类型查看
train.info()
#test.info()
<class ‘pandas.core.frame.DataFrame’>
RangeIndex: 1460 entries, 0 to 1459
Data columns (total 81 columns):
Id 1460 non-null int64
MSSubClass 1460 non-null int64
MSZoning 1460 non-null object
LotFrontage 1201 non-null float64
LotArea 1460 non-null int64
Street 1460 non-null object
Alley 91 non-null object
LotShape 1460 non-null object
LandContour 1460 non-null object
Utilities 1460 non-null object
LotConfig 1460 non-null object
LandSlope 1460 non-null object
Neighborhood 1460 non-null object
Condition1 1460 non-null object
Condition2 1460 non-null object
BldgType 1460 non-null object
HouseStyle 1460 non-null object
OverallQual 1460 non-null int64
OverallCond 1460 non-null int64
YearBuilt 1460 non-null int64
YearRemodAdd 1460 non-null int64
RoofStyle 1460 non-null object
RoofMatl 1460 non-null object
Exterior1st 1460 non-null object
Exterior2nd 1460 non-null object
MasVnrType 1452 non-null object
MasVnrArea 1452 non-null float64
ExterQual 1460 non-null object
ExterCond 1460 non-null object
Foundation 1460 non-null object
BsmtQual 1423 non-null object
BsmtCond 1423 non-null object
BsmtExposure 1422 non-null object
BsmtFinType1 1423 non-null object
BsmtFinSF1 1460 non-null int64
BsmtFinType2 1422 non-null object
BsmtFinSF2 1460 non-null int64
BsmtUnfSF 1460 non-null int64
TotalBsmtSF 1460 non-null int64
Heating 1460 non-null object
HeatingQC 1460 non-null object
CentralAir 1460 non-null object
Electrical 1459 non-null object
1stFlrSF 1460 non-null int64
2ndFlrSF 1460 non-null int64
LowQualFinSF 1460 non-null int64
GrLivArea 1460 non-null int64
BsmtFullBath 1460 non-null int64
BsmtHalfBath 1460 non-null int64
FullBath 1460 non-null int64
HalfBath 1460 non-null int64
BedroomAbvGr 1460 non-null int64
KitchenAbvGr 1460 non-null int64
KitchenQual 1460 non-null object
TotRmsAbvGrd 1460 non-null int64
Functional 1460 non-null object
Fireplaces 1460 non-null int64
FireplaceQu 770 non-null object
GarageType 1379 non-null object
GarageYrBlt 1379 non-null float64
GarageFinish 1379 non-null object
GarageCars 1460 non-null int64
GarageArea 1460 non-null int64
GarageQual 1379 non-null object
GarageCond 1379 non-null object
PavedDrive 1460 non-null object
WoodDeckSF 1460 non-null int64
OpenPorchSF 1460 non-null int64
EnclosedPorch 1460 non-null int64
3SsnPorch 1460 non-null int64
ScreenPorch 1460 non-null int64
PoolArea 1460 non-null int64
PoolQC 7 non-null object
Fence 281 non-null object
MiscFeature 54 non-null object
MiscVal 1460 non-null int64
MoSold 1460 non-null int64
YrSold 1460 non-null int64
SaleType 1460 non-null object
SaleCondition 1460 non-null object
SalePrice 1460 non-null int64
dtypes: float64(3), int64(35), object(43)
memory usage: 924.0+ KB
以数据集中训练集为例,训练集中数据类型包括int64、object、float64三种类型。
同时,值得注意的是数量不到1460的特征列说明的该列存在空值
3.3 缺失空值情况查看
3.3.1 缺失空值数值统计
isnull_array=train.isnull() #isnull_array是一个布尔型二维数组
train.isnull().sum(axis=0)
Id 0
MSSubClass 0
MSZoning 0
LotFrontage 259
LotArea 0
Street 0
Alley 1369
LotShape 0
LandContour 0
Utilities 0
LotConfig 0
LandSlope 0
Neighborhood 0
Condition1 0
Condition2 0
BldgType 0
HouseStyle 0
OverallQual 0
OverallCond 0
YearBuilt 0
YearRemodAdd 0
RoofStyle 0
RoofMatl 0
Exterior1st 0
Exterior2nd 0
MasVnrType 8
MasVnrArea 8
ExterQual 0
ExterCond 0
Foundation 0
…
BedroomAbvGr 0
KitchenAbvGr 0
KitchenQual 0
TotRmsAbvGrd 0
Functional 0
Fireplaces 0
FireplaceQu 690
GarageType 81
GarageYrBlt 81
GarageFinish 81
GarageCars 0
GarageArea 0
GarageQual 81
GarageCond 81
PavedDrive 0
WoodDeckSF 0
OpenPorchSF 0
EnclosedPorch 0
3SsnPorch 0
ScreenPorch 0
PoolArea 0
PoolQC 1453
Fence 1179
MiscFeature 1406
MiscVal 0
MoSold 0
YrSold 0
SaleType 0
SaleCondition 0
SalePrice 0
Length: 81, dtype: int64
3.3.2 缺失空值情况可视化
针对缺失空值可视化可以更加直观的展现数据缺失情况。可以通过缺失值矩阵图与缺失值条形图进行可视化操作。
# 缺失值矩阵图,白色代表缺失空值
#需要命令行安装 pip install missingno
mnso.matrix(train)
plt.show()

#缺失值条形图-各属性记录数
mnso.bar(titanic)
plt.show()

3.4 数值型数据规模查看
train.describe().T#查看数据集中数值型数据规模:数量、均值、标准差、最大、小值、四分位、中位数情况
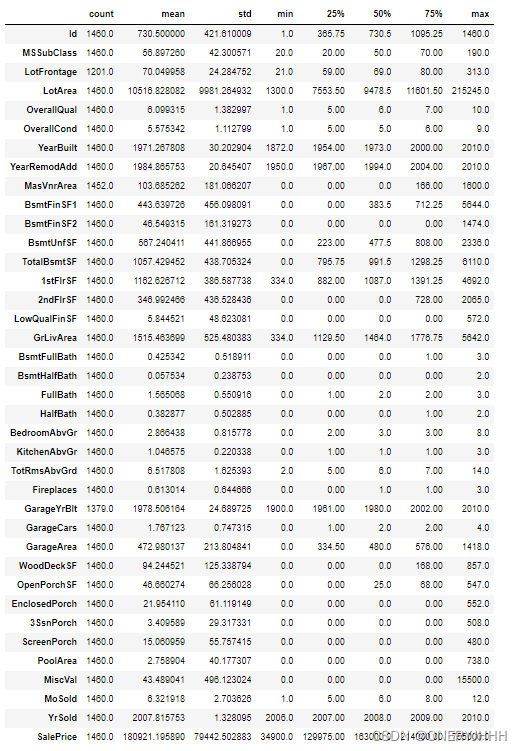
4、研究目标情况分析
研究目标总体来讲就是我们的标签数据,针对标签数据一般分为数据型数据以及类别型数据
- 数据型单数据可利用直方图、箱线图、小提琴图等方式进行直观的可视化
- 数据型多数据可利用 sn.pairplot(data) 以及 相关系数法表征 变量两两之间的关系
- 类别型数据可利用数据统计value_counts以及sn.countplot(data[‘row’]) 等方式计算和可视化
该数据集中研究目标-房价为:数据型单数据采用频率直方图可视化分析:
4.1 研究目标分布情况
#绘制目标值分布
sns.distplot(train['SalePrice'])
train['SalePrice'].describe()
count 1460.000000
mean 180921.195890
std 79442.502883
min 34900.000000
25% 129975.000000
50% 163000.000000
75% 214000.000000
max 755000.000000
Name: SalePrice, dtype: float64
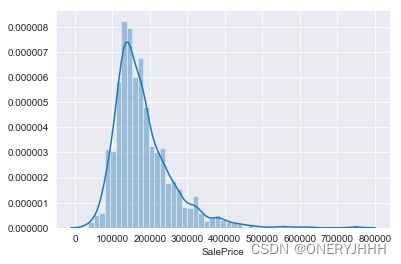
4.2 研究目标与特征的关系
之后我们需要分析特征数据与研究目标的两两关系
同时,这里需要考虑到特征数据数值型数据和类别型数据针对数值型数据与研究目标进行分析:
4.2.1 删除ID列
#删掉ID列
train.drop('Id', axis=1, inplace=True)
test.drop('Id', axis=1, inplace=True)
print('The shape of training data:', train.shape)
print('The shape of testing data:', test.shape)
4.2.2 分离特征数据中数值型和类别型数据
#分离数字特征和类别特征
num_features = []
cate_features = []
for col in test.columns:#使用测试集不需要去除训练集的标签列
if test[col].dtype == 'object':
cate_features.append(col)
else:
num_features.append(col)
print('number of numeric features:', len(num_features))
print('number of categorical features:', len(cate_features))

4.2.3 查看数值型数据与研究目标的关系
#查看数字特征与目标值的关系
plt.figure(figsize=(16, 20))
plt.subplots_adjust(hspace=0.3, wspace=0.3)
for i, feature in enumerate(num_features):
plt.subplot(9, 4, i+1)
sns.scatterplot(x=feature, y='SalePrice', data=train, alpha=0.5)
plt.xlabel(feature)
plt.ylabel('SalePrice')
plt.show()
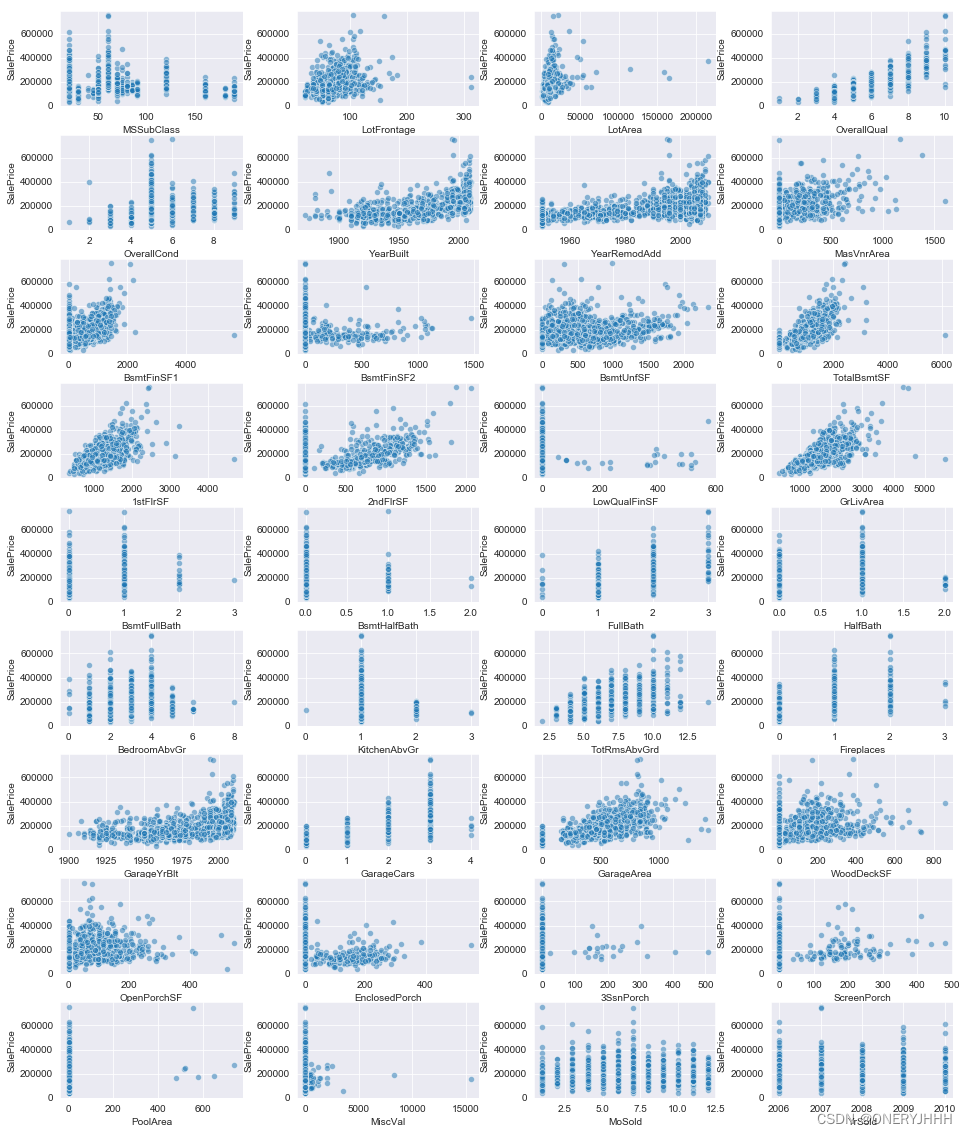
由此大致可以看出数值型特征与研究目标是否存在明显的线性关系
同时,观察到特征:YrSold、Fullbath等与研究目标并无明显关系可进行箱线图绘制进一步观察
以YrSold为例:
plt.figure(figsize=(16, 10))
sns.boxplot(x='YrSold', y='SalePrice', data=train)
plt.xlabel('YrSold', fontsize=14)
plt.ylabel('SalePrice', fontsize=14)
plt.xticks(rotation=90, fontsize=12)
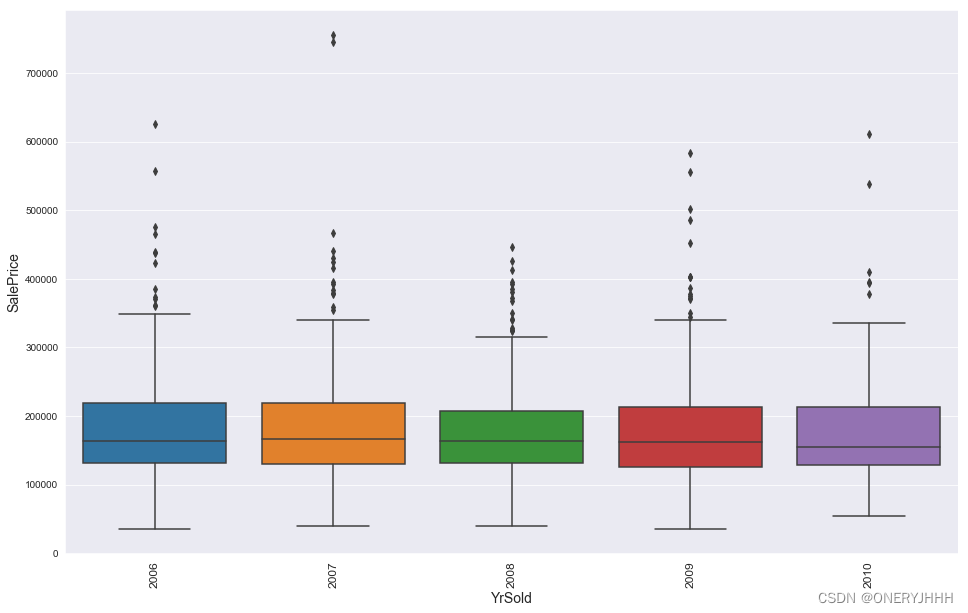
ok,确实没啥大的影响,那就不要这个特征的了
4.2.3 查看类别型数据与研究目标的关系
#查看类别特征对目标值的影响情况
plt.figure(figsize=(30, 40))
plt.subplots_adjust(hspace=0.3, wspace=0.3)
for i, feature in enumerate(cate_features):
plt.subplot(11, 4, i+1)
sns.boxplot(x=feature, y='SalePrice', data=train)
plt.xlabel(feature)
plt.ylabel('SalePrice')
plt.show()
 这里可以向我们提供类别型特征数据对研究目标的大体影响程度,如果出现像YrSold类似无明显影响的特征数据,可以考虑进行数据筛除。
这里可以向我们提供类别型特征数据对研究目标的大体影响程度,如果出现像YrSold类似无明显影响的特征数据,可以考虑进行数据筛除。
4.3 研究各个变量(数值型)之间的关系
利用相关系数热力图表征数据中各个变量之间的相关性情况
corrs = train.corr()
plt.figure(figsize=(16, 16))
sns.heatmap(corrs)
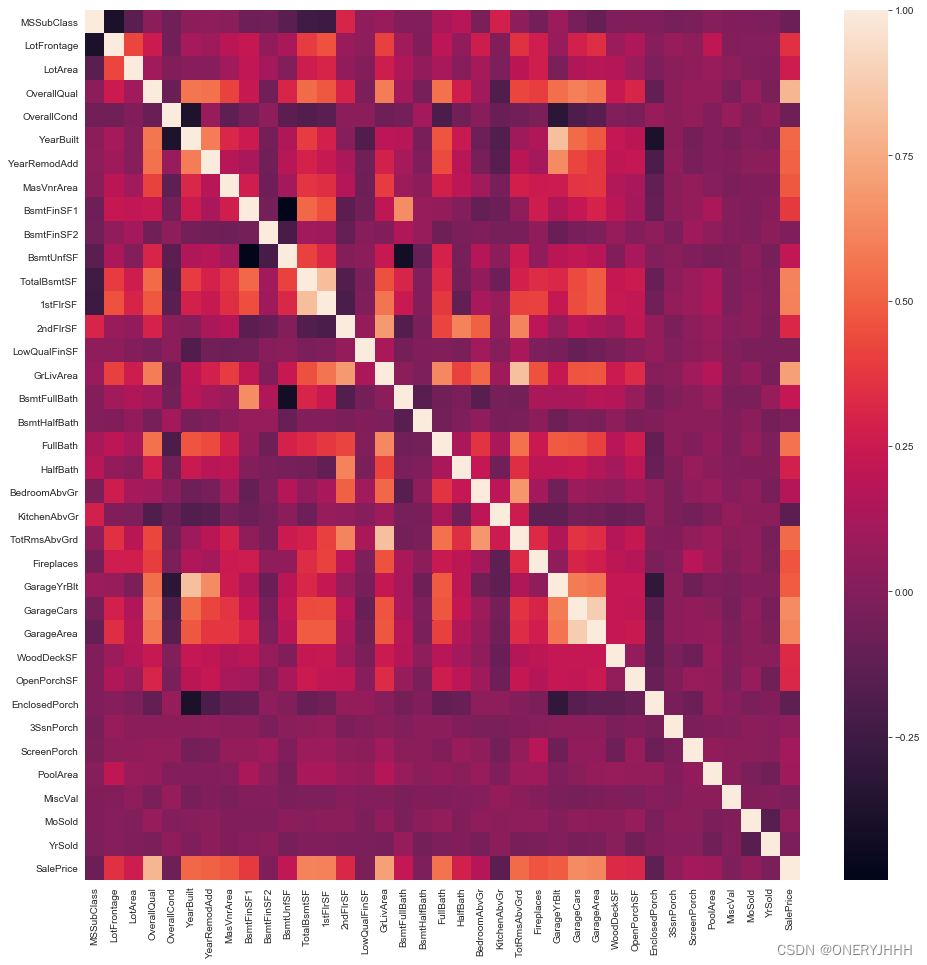
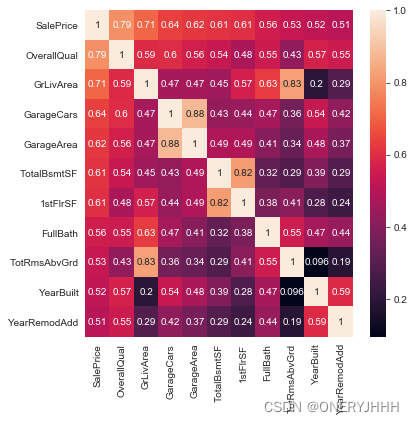
进一步,可以分析与目标值相关度最高的十个数值型变量
#分析与目标值相关度最高的十个变量
cols_10 = corrs.nlargest(11, 'SalePrice')['SalePrice'].index
corrs_10 = train[cols_10].corr()
plt.figure(figsize=(6, 6))
sns.heatmap(corrs_10, annot=True)
Seaborn其实是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易。其中,pairplot主要展现的是变量两两之间的关系(线性或非线性,有无较为明显的相关关系)
sns.pairplot(train[cols_10])#对角线上是各个属性的直方图(分布图),而非对角线上是两个不同属性之间的相关图
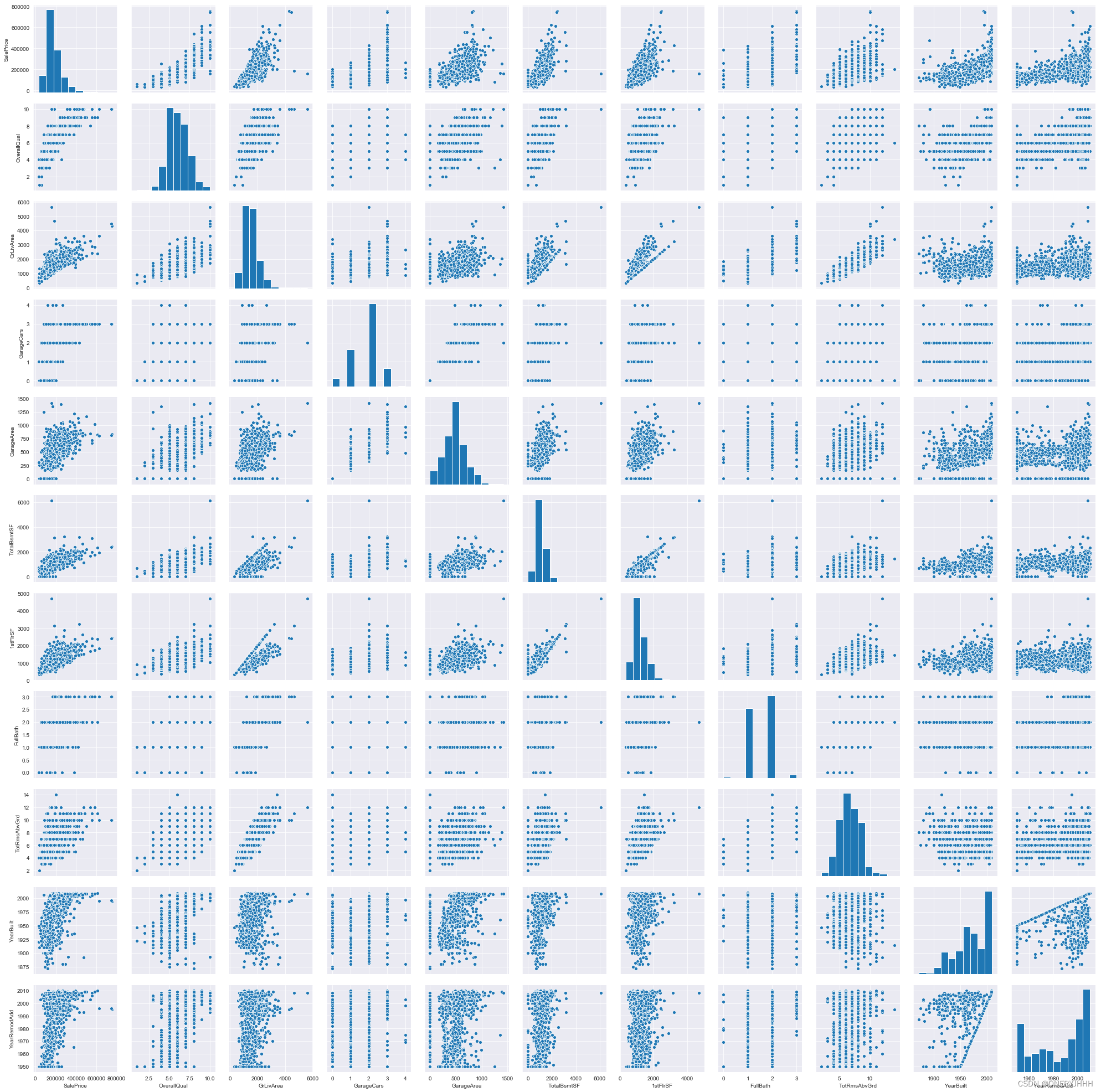
整体相关情况可视化后,可以进行异常点的初步排除,例如:
【1】Kaggle经典项目——房价预测中,作者通过观察整体图像,发现了’TotalBsmtSF’、'GrLivArea’中存在异常点,并进行了手动排除
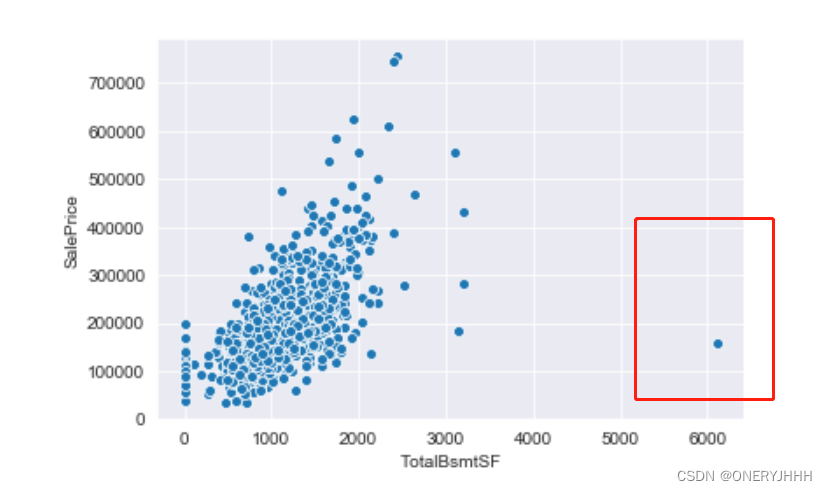
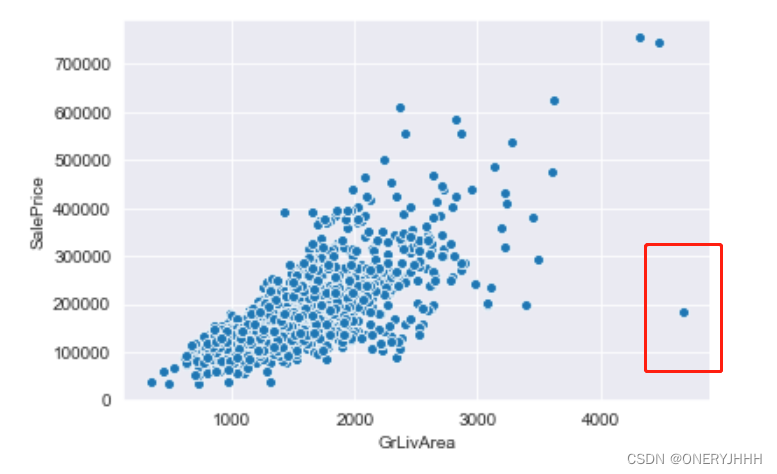
5、总结
EDA数据探索性分析帮助我们进一步了解数据的规模、趋势、数据间的大致相关情况,便于下一步对数据的清理以及特征选择的进行。
对于本文房价评估问题,通过EDA过程分析明确了:
- 数据规模、分布情况
- 数据缺失情况
- 数据相关性情况
- 数据异常情况
接下来需要针对分析情况重点进行:
- 数据异常点判定与剔除
- 数据缺失值处理