前言
大家好呀~,今天继续我们的mysql学习!
本篇博客主要记录Mysql创建完数据库后,要在数据库中创建表,那么首先需要定义表的结构约束(SQL-DDL)等,这篇主要介绍基础定义表的结构(创建、删除、修改、查找)以及一些数据类型的学习。
我的上一篇MySQL笔记:【MySQL】库的操作_柒海啦的博客-CSDN博客

目录
一、表的结构操作-DDL
1.创建表
首先sql语句创建表的格式如下:
create table [if not exists] table_name(
filed1 datatype,
filed2 datatype,
......
)engine 存储引擎 charset(character set 字符集)=字符集 collate=校验规则;
注意:
()后面均是必带内容,但是根据mysql的软件层上的设置可以不用带,因为完全可以继承当前环境下创建数据库的属性或者默认设置的属性。
存储引擎:就是在MySQL架构中提到的第三层,对于不同的引擎存在不同的存储方式,下面的实验就可以看到。(比如MyISAM引擎和InnoDB引擎)
filed 为列属性名字。注意,对于所有自己定义的变量名都可以使用` - 反引号括起来。
datatype 数据类型、约束条件等等。(后面会讲,下面知识举例)
下面只是做个示例,我们需要一个存储用户id,账号,密码的表,请创建出其的结构,存储引擎为MyISAM,同时也创建一个相同的表,存储类型为InnoDB。
create table `User1`(
`nm` int(3) zerofill comment '用户num',
`id` char(5) comment '用户id固定为5个长度',
`pw` char(7) comment '用户密码固定7个长度'
)engine MyISAM default charset=utf8;
create table `User2`(
`nm` int(3) zerofill comment '用户num',
`id` char(5) comment '用户id固定为5个长度',
`pw` char(7) comment '用户密码固定7个长度'
)engine InnoDB character set utf8 collate utf8_bin;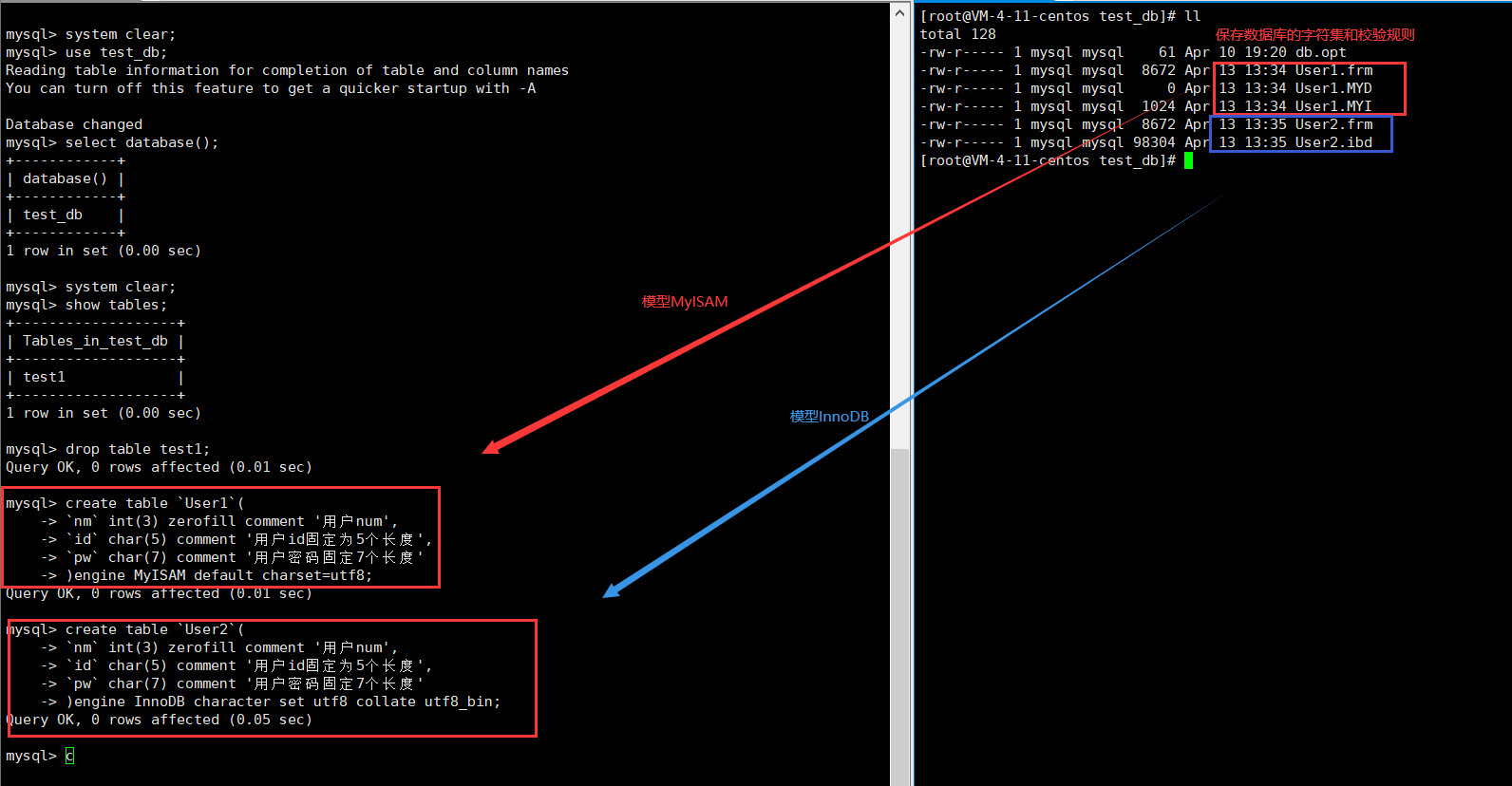
可以发现,因为存在存储引擎的区别,所以数据文件的保存方式也都不同。(mysql默认保存数据文件的路径为/var/lib/mysql)
那么既然创建出表结构了,我们如何查找我们的表结构或者表呢?
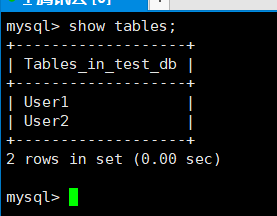
2.查找表
-查找当前数据库所有的表
show tables;
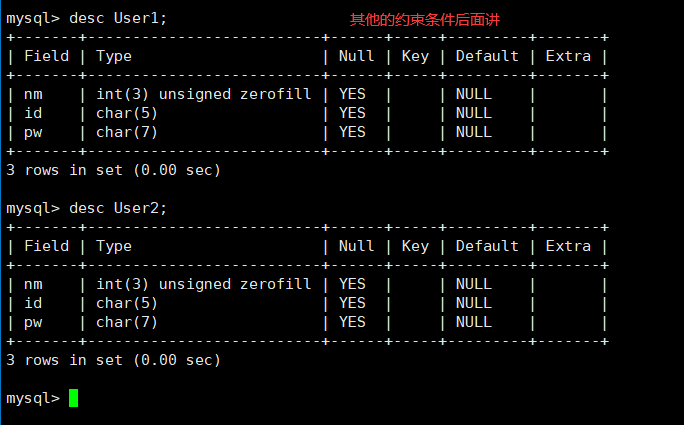
-查看表结构
desc 表名;
-查看表的创建语句
show create table 表名[\G]
\G为了整理格式便于观看
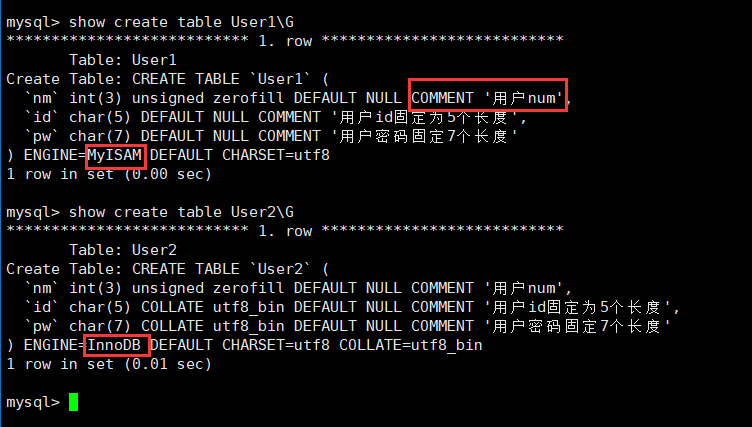
可以发现,我们之前设置的comment约束可以看到了,此约束设置就是为了给程序员看的。
此时表的结构就定下来了。但是如果中途我们需要改某些属性该怎么办呢?使用关键字alter即可。
3.修改表
修改表的结构同样存在三种:
alter table 表名 怎么改 (属性名 [datatype,......]) [after 属性名]
解释:
怎么改分为三类:
add 新增,后面跟属性名以及对于的类型以及约束条件,after表示新增属性在指定属性的后面。
drop 删除,后面只需要跟属性名即可。
modify 修改,后面跟属性以及对应类型以及约束条件。
注意:
-当前表中如果存在数据就有可能出现问题,所以表的结构一定前期要想好,别动不动就要上来修改表的结构。
-修改操作的时候均为覆盖式操作,所以必须讲约束条件写完整。
-删除属性的时候,当前列的所有数据也会被删除,一定三思而行。
-删除当只剩一列的时候,不可执行删属性操作,而是删表操作。(一个表结构至少存在一个属性)
下面对三种修改操作进行演示,并且结合注意事项进行说明。
首先,我们对表User1结构进行新增修改操作,将name属性增加到id的后面。
alter table User1 add name varchar(10) after id;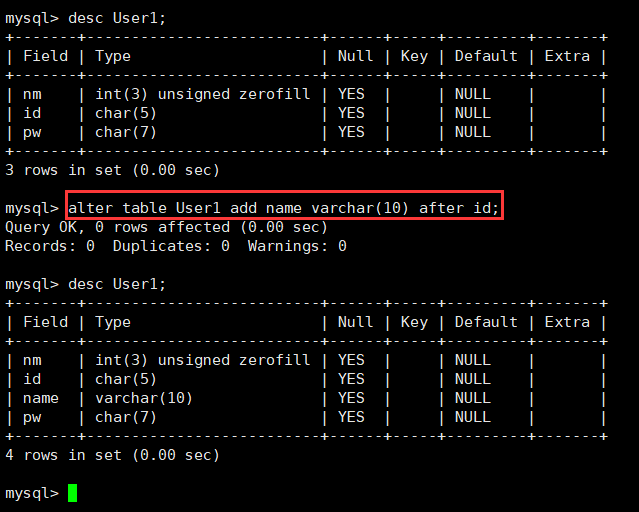
其次,我们对id属性修改为int(5)数据类型。
alter table User1 modify id int(5);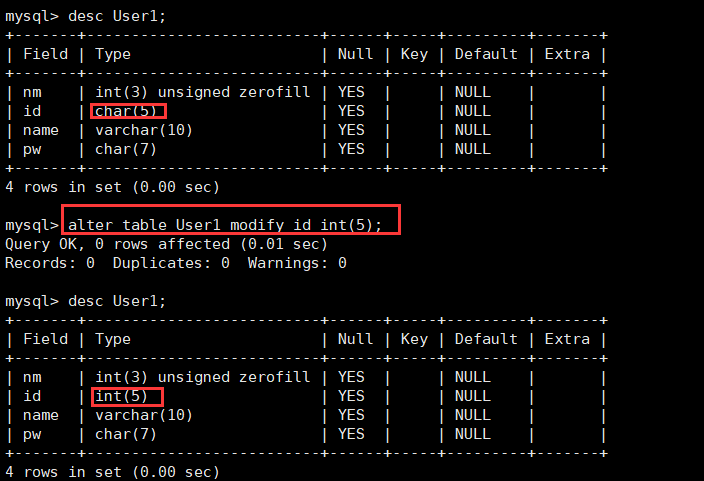
然后删除行nm。
alter table User1 drop nm;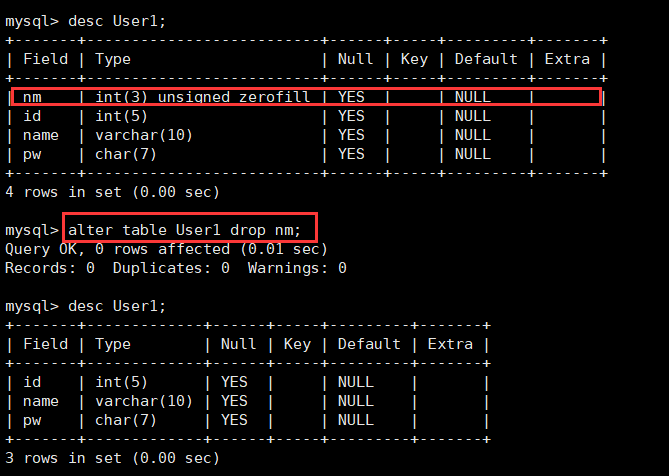
现在测试将User2表的全部列删完(删的完么?)
alter table User2 drop nm;
alter table User2 drop id;
alter table User2 drop pw;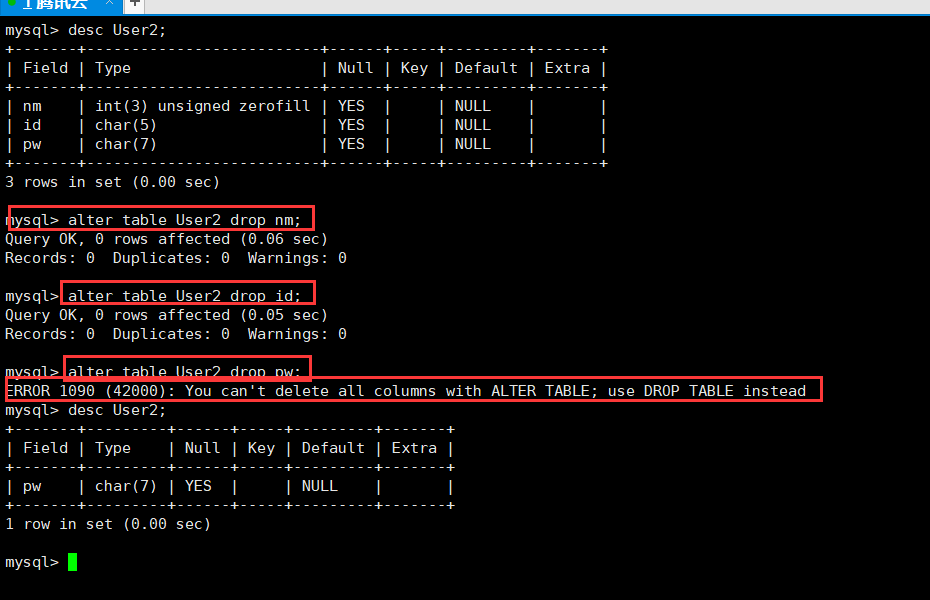
可以发现,当表剩下一列的时候,是无法直接删除属性的,需要连表一起删除的,否则无属性的表是不存在意义的。
-修改列名
修改列名很简单:
alter table 表名 change oldname newname (datatype.....) // 约束条件等。
注意修改列名也是覆盖式的操作。
比如我们修改表User1的id为ID:
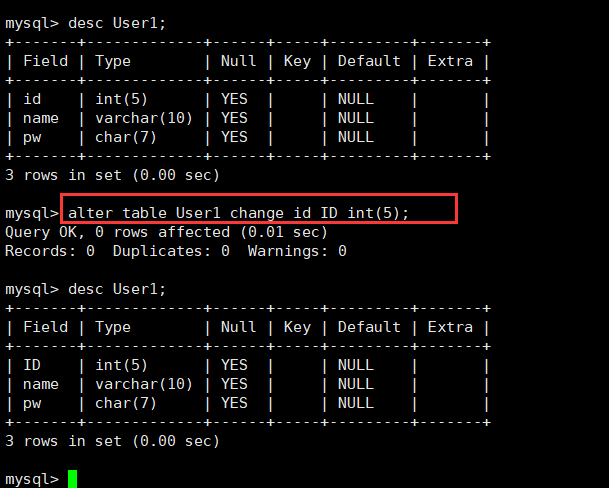
需要注意因为是覆盖式的修改,所以原本创建的数据类型以及约束类型也都要保持和之前的完整哦。
-修改表名
数据库省略了修改数据库名的操作,但是表的名字是可以修改的。
alter table old表名字 rename new表名(to new表名);
比如我们将User2表修改为Temp表。
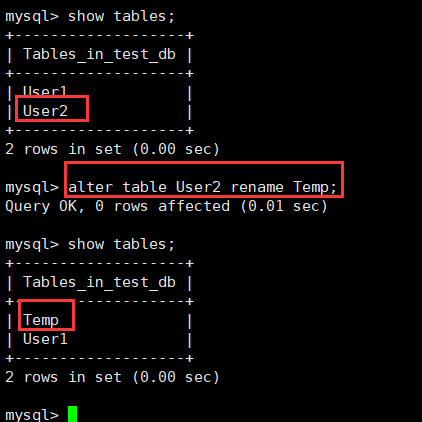
4.删除表
删除表使用关键字drop即可。
drop table 表名1[, 表名2......];
注意:删表操作也需要三思而行哦。
比如我们删除表Temp:
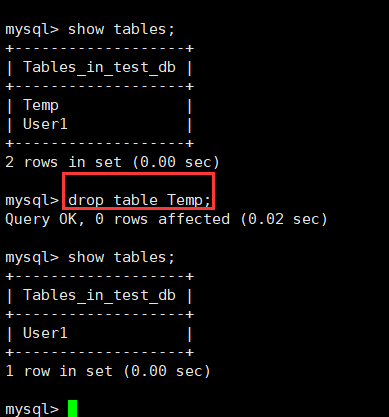
对应之前创建的所有数据文件也都会清理掉。
二、数据类型
数据类型就是在创建表属性的时候一种约束。在MySQL中数据类型大致分为四类,并且根据不同的应用场景而设计出来的。
数据类型之所以称为约束,就是因为能够将数据限制在一个范围或者不同类型中,从而约束用户只能输入对应类型的,否则就报错。

下面针对不同的类型抽出几个典型来讲。
1.数值类型
-整数类型
tinyint [[unsigned](n)] [zerofill];
int [[unsigned](n)] [zerofill];
......
unsigned:用于区分此数值类型是有符号还是无符号。
tinyint分配的空间是1byte(2^8),所以在有符号的取值范围为-128 ~ 127,无符号的情况下取值范围为0~255.
int分配的空间是4byte(2^32),所以在有符号的取值范围为-2^31 ~ 2^31 - 1,无符号就是0~2^32 - 1;
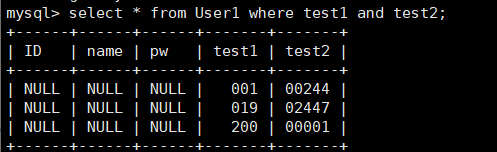
n表示在n个宽度的展示下,补充零的个数(注意只有后面加上约束zerofill才会生效),比如n = 3,表示1的时候就是001.需要注意的是,加上zerofill约束条件后只能是unsigned才能生效,所以会默认填充unsigned。(之后专门讲表的约束的适合会专门讲)
下面重点重点演示一下zerofill的约束。我们在User1表中,插入两个属性:test1和test2,使用alter进行修改插入:
alter table User1 add test1 tinyint(3) zerofill after pw;
alter table User1 add test2 int(5) zerofill after test1;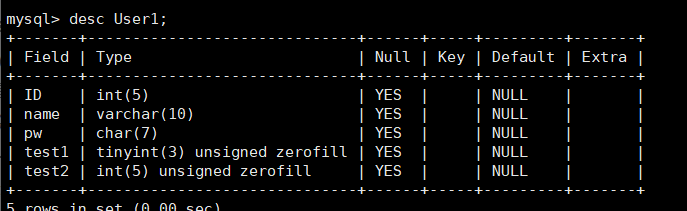
简单插入几个数据就可以得到如下的结果:
-比特类型
bit[(M)];
M表示其bit的位数,默认为1.最多64位。
需要注意的是,bit对应就是bit类型,根据对应的编码规则提取出来的时候,不是像整数类型那样直接提取出来了,而是被用作ASCII值提取出来的。
比如用下面的例子举例说明bit类型和其他数值类型的区别:
给表User1插入一个属性test3,定义位bit(7) (2^7),然后和id同时插入97,select查询数据的时候看看效果:
alter table User1 add test3 bit(7) after ID;
insert into User1(ID, test3) values(97, 97);
select * from User1;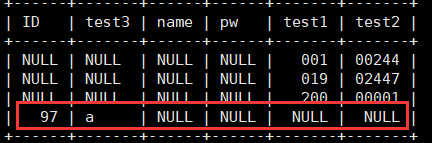
可以发现,虽然同时插入的是97,但是根据校验规则,bit类型的数据是按照ASCII码的标识取得,97对应得就是字母a,int就直接按照数值得方式取出了。
-小数类型
float[(M, D)] [unsigned];
decimal[(M, D)] [unsigned];
参数解释:
M:表示显示宽度。M >= 小数个数 + 整数个数
D:小数点的位数
float和decimal的区别:decimal精度表示比float高
占用空间4byte。
注意:
如果插入的元素小数位数超过了D,存在不同的舍去策略,当前我的环境下是四舍五入(不包括5)。
对于unsigned 的float(4, 2)来说,取值范围就是 0 ~ 99.99
我们验证一下四舍五入的事实,为表User1增加属性f1,表示一个浮点数宽度为4,小数占2位,并且插入9.985和9.986。
alter table User1 add f1 float(4, 2);
insert into User1 values(9.985);
insert into User1 values(9.986); 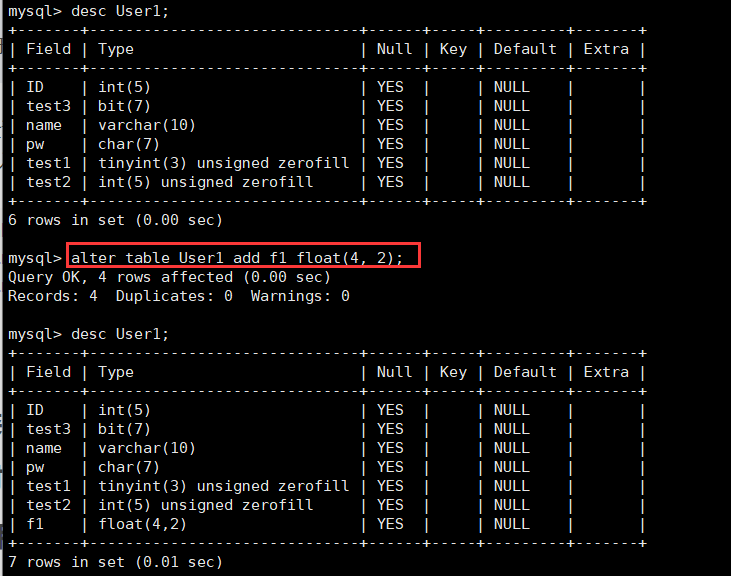
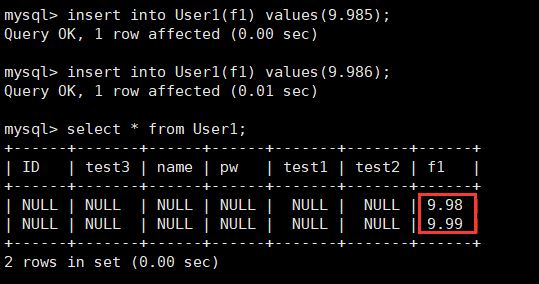
可以发现,虽然小数部分超过了D,但是对于四舍五入(不包括5),就可以进行正常插入数据。(注意,每个版本的mysql的策略不同,我当前的版本是支持这样的)
如果整数部分位数大于n - 小数位数就会直接报错的哦。

对于float和decimal类型来说,我们设置(10, 8)使用23.12345612进行分别插入,select进行查询后就可以知道结果了。
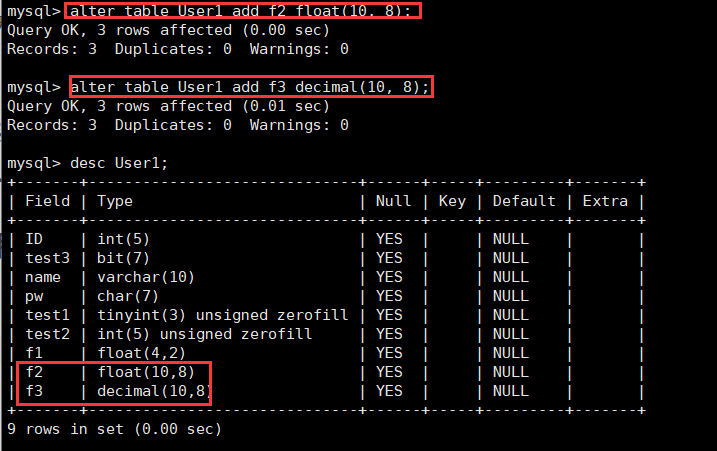
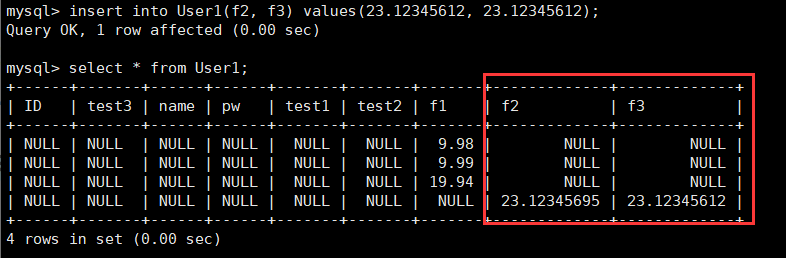
可以发现,float存储精度果然存在缺失,但是decimal精度很好。所以两者的本质区别在于存储精度的问题。需要高精度的话就选择decimal即可。
2.文本类型
char(size);
varchar(size);
参数解释:
char为固定长度字符串,varchar为可变长字符串。
其中size表示可以表示的字符个数。char最多255个,varchar最多65535个byte(长度根据编码字符大小而变,并且需要存在3byte记录每个字符的byte,所以有效字符个数为65532byte)。
注意:
对于char类型,因为是固定的长度字符串,那么开辟空间就严格按照size给出的大小进行开辟,如果是编码格式为utf8来说,一个字符用3byte,那么此时char开辟的空间大小为size * 3;
对于varchar类型,是可变的字符串,意思是动态进行申请长度的,size只是限制最大的长度。在mysql中,字符的byte为(1 ~ 3)中进行变化的,和编码相关,utf8就是3。另外,如果存储的数据不超过 255 字节,那么实际占用的存储空间就是数据的实际长度再加上一个字节用于存储长度信息,如果存储的数据长度超过 255 字节,则需要占用两个字节存储长度信息。此时varchar开辟的大小为:(n为实际字符个数,n<= size)
if <= 255:n*3 + 1;
else n*3 + 2;
所以,如果对于一个数据确定了长度的话,使用char固定字符串能够更加节省空间,如果不确定就使用varchar更节省空间。
比如插入电话和名字的时候,电话可以使用固定的长度,名字是可变的长度。
alter table User1 add c1 char(11) commit '电话11固定长度';
alter table User2 add c2 varchar(10) commit '名字不超过10个字符';![]()


3.日期时间类型
date;
datetime;
timestamp;
参数解释:
date表示格式:'yyy-mm-dd',表示年月日,占用空间3byte.
datetime表示格式:'yyy-mm-dd HH:ii:ss' 表示年月日小时分钟秒,占用空间8byte。
timestamp是时间戳,占用4byte。显示查询的时候会显示datetime的格式,并且用户不需要显示插入(设置了default),会自动获取插入的时候的时间戳,显示日期和时间。并且设置非空。全都是默认形成。(后续在进行插入或者修改的时候,都会进行自动更新)
三种都存在不同的应用场景,对于空间占用大小就忽略不计了。
给User1表增加属性d1,d2,d3,检测三种属性的特点。
alter table User1 add d1 date;
alter table User1 add d2 datetime;
alter table User1 add d2 timestamp; 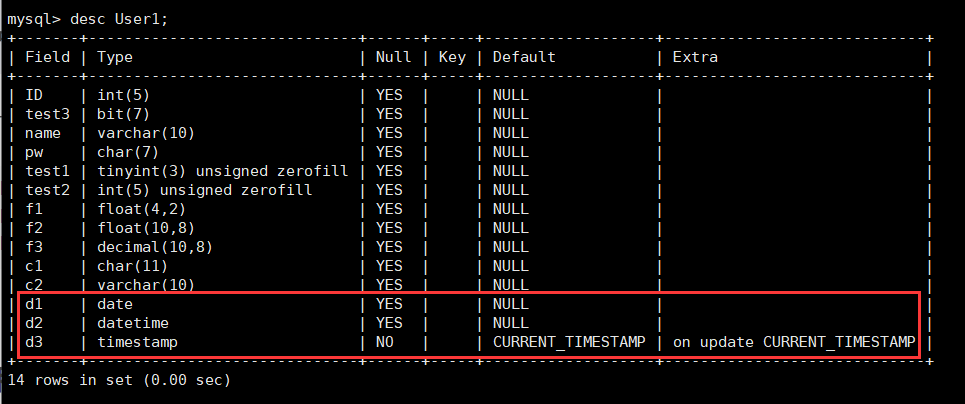
首先插入数据:insert into User1(d1, d2) values('1949-10-01', '2008-10-01 16:41:32');

可以发现d3已经自动更新插入的时候时间戳了。当我们进行修改的时候,同样会发生变化(不对d3做任何处理)。
update User1 set ID=3 where ID is NULL;
 可以发现,只要对当前元组进行修改数据(涉及到DML数据操纵语言的学习),d3即timestamp时间戳都会进行更新的。
可以发现,只要对当前元组进行修改数据(涉及到DML数据操纵语言的学习),d3即timestamp时间戳都会进行更新的。
4.enum和set类型
enum('选项1', '选项2', ......);
set('选项1', '选项2', ......);
参数解释:
enum类似于C中的枚举,mysql中表示单选类型。即限制给此数据属性插入数据的话必须是enum选项中的其中一个。实际上,每个选项底层存的是数字,'选项1'可以用1进行代替,从1开始,最多65535个选项。
set是多选类型,限制对此数据属性输入时只能是这些的不定项个。为了效率,同样这些底层也都是数字存储,只不过利用的是位图结构。比如如果当前为3个选项的话,表示第一个选项为001 = 1,第二个010 = 2,第一个和第二个 011 = 3....类似这样的去表示的。最多表示的选项个数为64个(2^64)
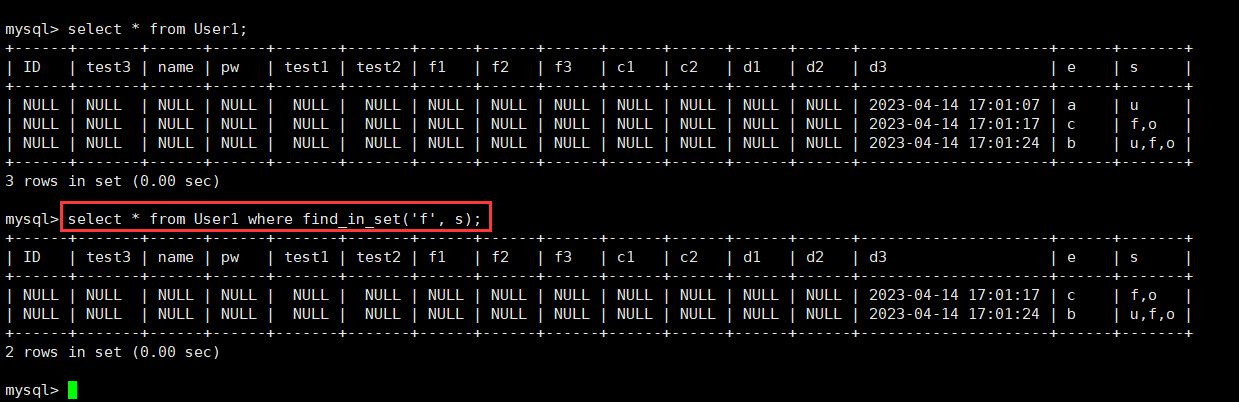
比如,我为我们的User1表增加属性e和s,其中e为enum包括a,b,c;s为set包括u,f,o。
alter table User1 add e enum('a', 'b', 'c');
alter table User1 add s set('u', 'f', 'o');
我们随便插入几个数据:
insert into User1(e, s) values('a', 'u');
insert into User1(e, s) values('c', 'f,o');
insert into User1(e, s) values(2, 7); -- 'b' 'u,f,o'
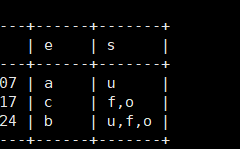
那么这里对于set的查询就存在一定问题了。因为一个属性严格区分不同的属性,我们想要查找数据中只存在f这种元组,直接select * from User1 where s='f';可以吗?自然不行,我们需要一个函数,帮我们解决这个问题。
find_in_set()
select find_in_set('a', 'a,b,c');
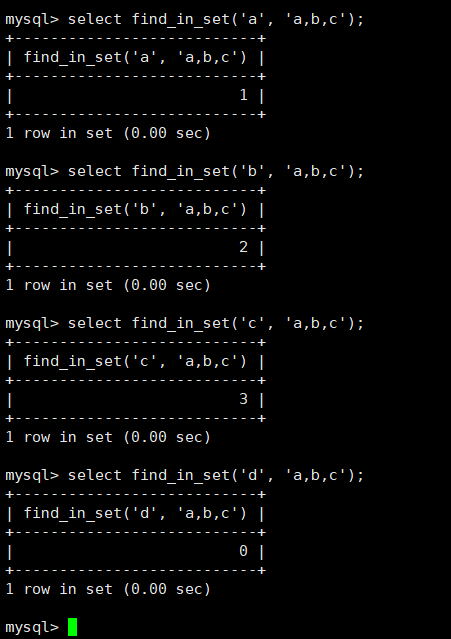
对于函数find_in_set(a, b),能够将单元素a,从b组合中提取出对应的位置,从1开始,没有为0。所以对应select查询语句中的where,只要查找到返回>1即可。我们就可以找到只存在‘f’的元素。
select * from User1 where find_in_set('f', s);