【唐宇迪】CV不存在?Meta最新的计算机视觉Segment Anything Meta终极模型,强到离谱!-人工智能/计算机视觉/深度学习/机器学习_哔哩哔哩_bilibili4月5日最新发布,Meta正式推出模型SAM(Segment Anything Model)称这一模型可用于识别图像和视频中的物体,甚至是从未被训练学习过的物品。技术论文也一并推出,标题甚至只有两个单词——Segment Anything(分割一切),喜欢记得多多支持。, 视频播放量 15478、弹幕量 142、点赞数 447、投硬币枚数 239、收藏人数 1044、转发人数 139, 视频作者 跟着唐宇迪学AI, 作者简介 全网同名!大家好,我是唐宇迪,一名计算机博士,专注于机器学习与计算机视觉领域。感谢关注~~~,相关视频:CV界不存在了?体验下Meta最新的Segment Anything Meta计算机新模型实现“终极抠图”,segment-anything是趋势,但是牛逼吹的太大了,【AI绘画】破解Diffusion扩散模型,[小白向-深度学习装机指南] 01 双4090 涡轮版开箱启动 vlog(gpu burn,cpu burn),Segment Anything上线一天8.2k star,Segment Anything 图像分割 VS 清明上河图,计算机视觉(CV)方向就业情况分析,听说很卷?,我大抵是难毕业了,效果巨烂。Yolov5+deepsort+1DCNN,任正非谈ChatGPT,ChatGPT结合Python和MATLAB科研绘图,王炸。 https://www.bilibili.com/video/BV18T411W7ph/?spm_id_from=333.337.search-card.all.click&vd_source=4aed82e35f26bb600bc5b46e65e25c22Segment Anything | Meta AI
https://www.bilibili.com/video/BV18T411W7ph/?spm_id_from=333.337.search-card.all.click&vd_source=4aed82e35f26bb600bc5b46e65e25c22Segment Anything | Meta AIhttps://segment-anything.com/demo
clicks:点,box:框,everything:全图画点。
abstract:数据闭环,1100万张图,10亿mask。可以在一些新的数据分布和任务中直接zero-shot。
1.introduction
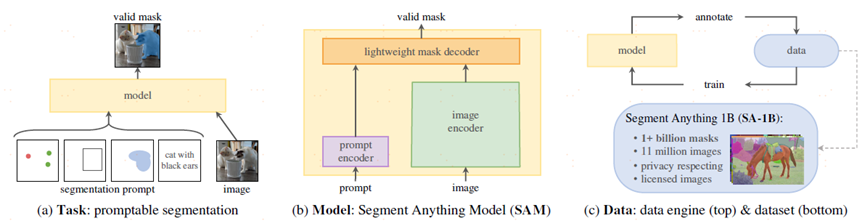
foundation models没在数据分布上训练也可以泛化,借助于prompt。本文的核心是构建了一个数据引擎,task,model,dataset。
task:给定prompt输出,prompt可以是文本或者空间上点,只要可以编码成向量就可以,点和框的坐标编码成向量。存在歧义涉及多个对象,输出也是这些对象中至少一个合理的mask。
model:image encoder(VIT),prompt encoder(任意的prompt,point,box,mask prompt一堆点,text prompt),mask decoder,从一个prompt中进行解码只需要50ms进行交互。
data engine:assisted-manual,semi-automatic,fully automatic。
dataset:1100万张图,10亿mask。
标注数据示例:

2.segment anything task
pre-training:vit->mae,text->clip.
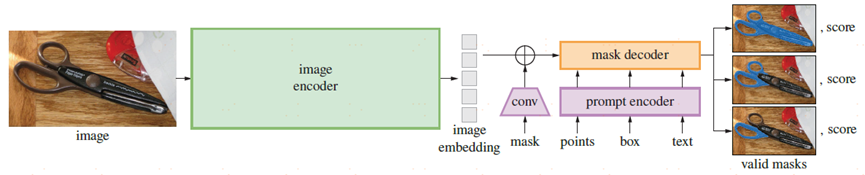
3.segment anything model
Image encoder:MAE,ViT-H/16 with 14x14 windowed,16倍下采样,1024x1024降采样成64x64。
Prompt encoder:sparse points,boxes,text and dense masks。点和框通过positional encodings,text通过clip,masks使用卷积嵌入并与图像embeddings相加。变成256维向量。
mask decoder:mask decoder通过image embeddings,prompt embeddings,将oputput token映射到mask,修改了transformer decoder block,我们修改的decoder使用了prompt self-attention和cross-attention,其实就是在vit编码后的image embeddings中,使用通过编码后的embeddings去检索,最终得到mask。
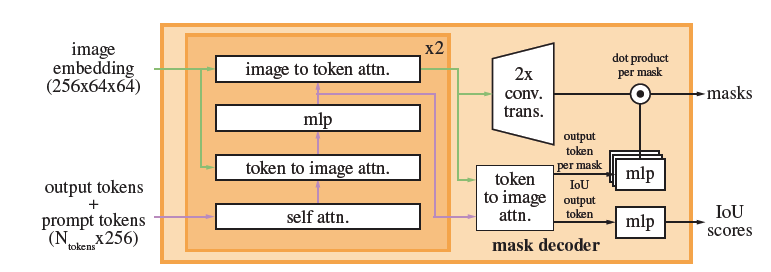
self-attention是prompt之间的attention,明确各自要找的目标,cross-attention是每个token去image embeddings中去检索自己对应的区域。image embedding是256x64x64,token和image存在相互更新。2个decoder,第一个decoder是在64x64上,第二个decoder做了上采样4,是在256x256上做,prompt在第二个decoder时也加了position encoding。
efficiency:cpu上50ms。