背景
许多大型互联网系统,如:电商、社交、新闻等 App 或网站,动辄日活千万甚至上亿,每分钟的峰值流量也在数十万以上,架构上如何应对如此高的流量峰值?可以通过使用“缓存”技术来给系统减压。
内容
缓存用法
流量峰值对系统带来的主要危害在于,它会瞬间造成大量对磁盘数据的读取和搜索,通常的数据源是数据库或文件系统,当数据访问量次数增大的时候,过多的磁盘读取可能会最终成为整个系统的性能瓶颈,甚至是压垮整个数据库,导致系统卡死、服务不可用等严重后果。
常规的应用系统中,我们通常会在需要的时候对数据库进行查找,因此系统的大致结构如下所示:
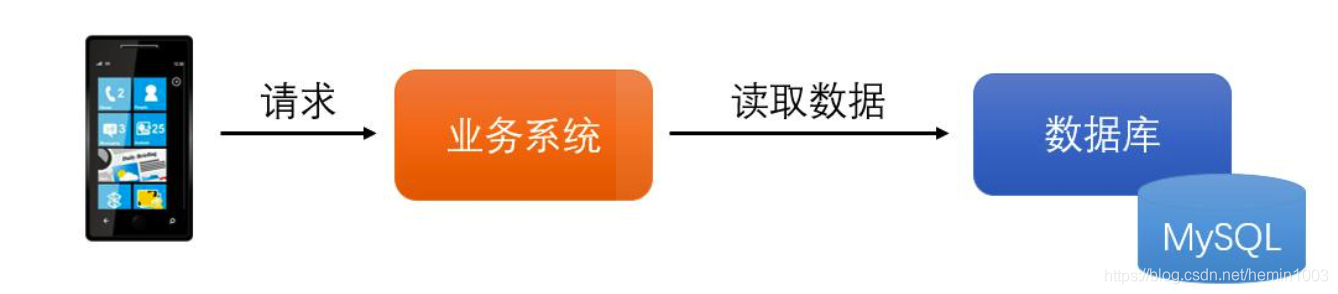
当数据量较高的时候,需要减少对于数据库里面的磁盘读写操作,因此通常都会选择在业务系统和数据库之间加入一层缓存从而减少对数据库方面的访问压力,如下图所示:

当数据量较高的时候,需要减少对于数据库里面的磁盘读写操作,因此通常都会选择在业务系统和 MySQL 数据库之间加入一个缓存层,从而减少对数据库方面的访问压力。
缓存在实际场景的应用当中并非这么简单,下边我们来通过几个比较经典的缓存应用场景来列举一些问题。
缓存常见问题
1. 缓存和数据库之间数据一致性问题
常用于缓存处理的机制有以下几种:
- Cache Aside 模式。
这种模式处理缓存通常都是先从数据库缓存查询,如果缓存没有命中则从数据库中进行查找。
这里面会发生的三种情况如下:
- 缓存命中:当查询的时候发现缓存存在,那么直接从缓存中提取。
- 缓存失效:当缓存没有数据的时候,则从 database 里面读取源数据,再同步到 cache 里面去。
- 缓存更新:当有新的写操作去修改 database 里面的数据时,需要在写操作完成之后,让cache 里面对应的数据失效,作缓存同步。
这种 Cache aside 模式,通常是我们在实际应用开发中最为常用到的模式。但是并非说这种模式的缓存处理就一定能做到完美。

这种模式下依然会存在缺陷。比如,一个是读操作,但是没有命中缓存,然后就到数据库中取数据,此时来了一个写操作,写完数据库后,让缓存失效,然后之前的那个读操作再把老的数据放进去,所以会造成脏数据。
分布式环境中要想完全的保证数据一致性,是一件极为困难的事情,我们只能够尽可能的降低这种数据不一致性问题产生的情况。
- Read Through 模式。
是指应用程序始终从缓存中请求数据。如果缓存没有数据,则它负责使用底层提供程序插件从数据库中检索数据。检索数据后,缓存会自行更新并将数据返回给调用应用程序。
使用 Read Through 有一个好处,我们总是使用 key 从缓存中检索数据,调用的应用程序不知道数据库,由存储方来负责自己的缓存处理,这使代码更具可读性,代码更清晰。
但是这也有相应的缺陷:开发人员需要编写相关的程序插件,增加了开发的难度性。
- Write Through 模式。
和 Read Through 模式类似,当数据发生更新的时候,先去 Cache 里面进行更新,如果命中了,则先更新缓存再由 Cache 方来更新 database。如果没有命中的话,就直接更新 Cache 里面的数据。
- Write Behind Caching 模式。
这种模式通常是先将数据写入到缓存里面,然后再异步的写入到 database 中进行数据同步。
这样的设计既可以直接的减少我们对于数据的 database 里面的直接访问,降低压力,同时对于 database 的多次修改可以进行合并操作,极大的提升了系统的承载能力。
但是这种模式处理缓存数据具有一定的风险性,例如说当 cache 机器出现宕机的时候,数据会有丢失的可能。
缓存的高并发场景中存在哪些问题?
缓存过期后将尝试从后端数据库获取数据,这是一个看似合理的流程。
但是,在高并发场景下,有可能多个请求并发的去从数据库获取数据,对后端数据库造成极大的冲击,甚至导致“雪崩”现象。
此外,当某个缓存 key 在被更新时,同时也可能被大量请求在获取,这也会导致一致性的问题。
那如何避免类似问题呢?我们会想到类似“锁”的机制,在缓存更新或者过期的情况下,先尝试获取到锁,当更新或者从数据库获取完成后再释放锁,其他的请求只需要牺牲一定的等待时间,即可直接从缓存中继续获取数据。
- 缓存穿透问题。
缓存穿透也称为“击穿”。很多朋友对缓存穿透的理解是:由于缓存故障或者缓存过期导致大量请求穿透到后端数据库服务器,从而对数据库造成巨大冲击。
这其实是一种误解。真正的缓存穿透应该是这样的:
在高并发场景下,如果某一个 key 被高并发访问,没有被命中,出于对容错性考虑,会尝试去从后端数据库中获取,从而导致了大量请求达到数据库,而当该 key 对应的数据本身就是空的情况下,这就导致数据库中并发的去执行了很多不必要的查询操作,从而导致巨大冲击和压力。
可以通过下面的几种常用方式来避免缓存穿透问题:
1. 缓存空对象
对查询结果为空的对象也进行缓存,如果是集合,可以缓存一个空的集合(非 null),如果是缓存单个对象,可以通过字段标识来区分。这样避免请求穿透到后端数据库。同时,也需要保证缓存数据的时效性。
这种方式实现起来成本较低,比较适合命中不高,但可能被频繁更新的数据。
2. 单独过滤处理
对所有可能对应数据为空的 key 进行统一的存放,并在请求前做拦截,这样避免请求穿透到后端数据库。
这种方式实现起来相对复杂,比较适合命中不高,但是更新不频繁的数据。
- 缓存颠簸问题。
也被成为“缓存抖动”,可以看做是一种比“雪崩”更轻微的故障,但是也会在一段时间内对系统造成冲击和性能影响。一般是由于缓存节点故障导致。
业内推荐的做法是通过一致性 Hash 算法来解决。
- 缓存的雪崩。
是指由于缓存的原因,导致大量请求到达后端数据库,从而导致数据库崩溃, 整个系统崩溃,发生灾难。
导致这种现象的原因有很多种,上面提到的“缓存并发”,“缓存穿透”,“缓存颠簸”等问题,其实都可能会导致缓存雪崩现象发生。
这些问题也可能会被恶意攻击者所利用。还有一种情况,例如某个时间点内,系统预加载的缓存周期性集中失效了,也可能会导致雪崩。为了避免这种周期性失效,可以通过设置不同的过期时间,来错开缓存过期,从而避免缓存集中失效。
从应用架构角度,我们可以通过限流、降级、熔断等手段来降低影响,也可以通过多级缓存来避免这种灾难。
此外,从整个研发体系流程的角度,应该加强压力测试,尽量模拟真实场景,尽早的暴露问题从而防范。
最后:
缓存技术,是大型互联网系统架构中常用的一种技术。
在设计缓存架构的过程中,要根据业务场景进行针对性的设计,同步避免缓存延迟、脏数据、缓存雪崩等问题,提升系统的高可用性、健壮性。
上一章教程
架构思维成长系列教程(二)- CAP理论在大型互联网系统中的应用
该系列教程
我的专栏
至此,全部介绍就结束了
-------------------------------
-------------------------------
关于我(个人域名,更多我的信息)
期望和大家一起学习,一起成长,共勉,O(∩_∩)O谢谢
欢迎交流问题,可加个人QQ 469580884,
或者,加我的群号 751925591,一起探讨交流问题
不讲虚的,只做实干家
Talk is cheap,show me the code
