最近在自己的红外数据集上训练YOLOX网络(以COCO数据集的形式),把过程记录下来。
YOLOX代码:https://github.com/Megvii-BaseDetection/YOLOX
目录
数据集准备
生成数据标签的json文件
我手上的数据集的格式是jpg图像和对应的txt标签文件,要训练YOLOX的话需要先对标签文件进行处理,生成COCO数据集格式的标签文件,由于官方代码中没有这部分的内容,我在QueryDet的data_prepare.py文件找到类似的代码,对其稍作修改,就可以生成我们所需要的json标签文件。
代码修改
修改数据集的目录信息
创建自己的exp文件。
我想先训练yolox_l,所以我在exps\default目录下创建了一个新文件yolox_l_mydata.py,然后将yolox_l.py中的内容复制过来,增加数据集的目录信息:
self.data_dir = "dataset"
self.train_ann = "dataset/annotations/instances_train2017.json"
self.val_ann = "dataset/annotations/instances_val2017.json"
修改类别数量
同样在yolox_l_mydata.py文件中增加类别数量,这里我只有一类目标:
self.num_classes = 1
最终yolox_l_mydata.py文件如下:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# Copyright (c) Megvii, Inc. and its affiliates.
import os
from yolox.exp import Exp as MyExp
class Exp(MyExp):
def __init__(self):
super(Exp, self).__init__()
self.depth = 1.0
self.width = 1.0
self.exp_name = os.path.split(os.path.realpath(__file__))[1].split(".")[0]
self.data_dir = "dataset"
self.train_ann = "dataset/annotations/instances_train2017.json"
self.val_ann = "dataset/annotations/instances_val2017.json"
self.num_classes = 1
修改标签
我需要检测的目标名为target,因此在yolox\data\datasets\coco_classes.py文件中将原本的所有类别注释掉,改为:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# Copyright (c) Megvii, Inc. and its affiliates.
COCO_CLASSES = (
"target",
)
训练
然后应该就可以训练了(希望我没有漏写啥):
python tools/train.py -f exps/default/yolox_l_mydata.py -d 2 -b 16 --fp16 -o -c pretrained/yolox_l.pth --cache
其中,
-d:GPU数量
-b:batch size(建议设置为GPU数量的8倍)
--fp16: 混合精度训练
--cache: 利用RAM缓存加速训练(we now support RAM caching to speed up training! Make sure you have enough system RAM when adopting it.)
我遇到的坑
生成json标签文件时出现图片和标签不对应的问题
这部分内容记录在【python】由os.listdir导致的惨案中。
改动数据集后需手动删除缓存数据文件
就是这个坑!坑了我好多天!也是我想写这篇博客的唯一原因!
从上面可以看到,我一开始生成的标签和图片不对应,所以我后来重新又生成了一遍json文件,然后重新训练网络,但是!损失变化和原来一样,都是完全降不下去,我百思不得其解,以为我数据处理部分还是有问题,就一直在找生成json的代码哪里写错了,找啊找啊找啊,愣是没发现问题在哪。
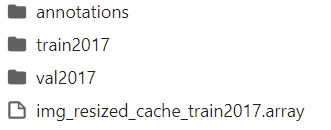
今天,我都准备换个数据集格式训练了(当时看到了以训练yolo的格式来训练YOLOX:https://github.com/xialuxi/yolox-yolov5,准备尝试),然后再次打开了数据集文件夹,突然发现里面有一个原本没有的文件img_resized_cache_train2017.array,这个文件是在第一次训练网络时自动生成的,有几十个G,我猜大概是把所有数据集的内容都放在了这个缓存文件中,以后再训练网络的时候直接读取这个缓存文件而不需要重新去annotations、train2017、val2017三个文件夹中读取,加快训练的速度。也就是说!上面我虽然改正了标签文件,但我之后训练网络时它读取的一直是我之前错误的标签文件所生成的缓存文件!所以我训练网络时的损失始终无法下降,因为图片标签都不对应啊!
哭了,说多了都是泪,亏我找了这么久的问题T T
关于YOLOX训练的部分就先记录到这,等网络训练完了看看效果咋样。