介绍一下关于机器学习梯度下降自己的理解:

上图来自 Neural Networks and Deep Learning(美)Michael Nielsen 著
如上图所示,假设我们需要找到二元函数 C(v1,v2) 的最小值,根据微积分:
 |
(1) |
很明显,要找到 C(v1,v2) 的最小值,我们需要一个操作使得 C 不断减少,则我们可以在 v 做每次 ”移动“ 时, C 都能减小那么一点点,即需要: ∆C < 0
将 (1) 式写成向量形式:
| C 的梯度向量 ∇C: |  |
| ∆v : |

|
| 这里,如果我们用 ∆v = -η∇C , 则代入上式: | < 0  |
| 则梯度下降的更新规则可以为: |  |
注意
好了,咱们理解了上面的东西,接下来,我们来看看怎么将梯度下降运用在机器学习中!
假设我们利用 MSE 即均方误差作为误差函数,即:
 |
(2) |
上式中,n为训练样本的个数,x代表训练数据,y(x)为训练数据 x 输入训练模型之后的实际输出,a为标签,即理想输出。直观上来说,上式表示对于n个训练样本,训练模型实际输出 y(x) 与理想输出 a 的 "差距" 的平均大小。
我们的目标是最小化 C(w, b)。对于 (2),看起来C中含有的自变量有 w, b ,x 。而很显然 , x作为训练数据,我们是不能运用梯度下降算法来改变它使得我们的 C 变小的,我们只能通过改变 w, b 的值来使得误差函数不断减小。这个时候,想想,参考之前讲的知识,我们应该怎么做呢?
我们可以这样做:
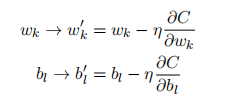
其中的 C 为代价函数(在这里是误差函数)。
通过重复应用这种更新规则我们就能“让球体滚下山”,并且有望能找到代价函数的最小值。换句话说,这是一个能让神经网络学习的规则。
关于随机梯度下降
其实也很容易理解:随机挑选一批训练数据,训练,做一次梯度下降(更新一次权重)
{
关于梯度下降我们会有两种思路:
一种思路是对于输入的单个训练数据 x,我们就做一次梯度下降 。这种方法更新速度很快,但是单个训练样本不足以代表整个训练集,而且训练结果也会波动的比较厉害:
比如我有三个训练数据 x1、x2, 对应的标签为 a1、a2
对于 x1 , 放入训练模型,得出 y(x1) - a1 = b1 ,b1很大,即 y(x1) 和 a1 “差距”比较大。好,我们做梯度下降,模型中参数改变了,现在做完梯度下降之后 如果我们还将 x1 输入训练模型,y1(x1) - a1 = c1 < b1。"差距变小了", 这是毋庸置疑的,毕竟这是在做梯度下降嘛。(因为参数变了,我将改变参数后的模型记为y1)
但是对于x2呢,在未输入训练数据 x1 来改变模型中参数时,y(x2) - a2 = b2。 在输入训练数据x1改变模型中参数后,y1(x2) - a2 = c2。但是很有可能,c2 > b2,也就是说对于x1的那次梯度下降的确降低了 y(x1) 离标签的“差距”,但是却增加了 y(x2) 离标签的“差距”。而我们有对于单个的 x2 做梯度下降时,有可能虽然降低了 y(x2) 离标签的“差距”,却又增加了y(x1)离标签的“差距”。
还有另外一种思路 批量梯度下降:对于每训练数据,我们将训练数据中的每一个 x, 我们都求出
对于参数 w, b 的偏导数,然后对其求和再求平均值作为参数 w, b 的梯度方向。 这种方法更新比较稳定,在结果最终收敛时,基本不会出现波动,但是其更新速度太慢,我们每进行一次参数的更新都需要将所有训练样本都放进训练模型中训练一遍以得到
(j ∈ [0, n])。
其更新规则如下:
其中 η 为学习速率,n 为训练数据的数量。其中的参数
Wk 和 bl,它俩只是 weights 和 bias 众多参数中的一个。

}
折中两种办法:随机梯度下降
我们的最小化目标 C 是整个训练集对于每一个(共n个)训练数据的模型输出 y(x) 离标签 a 的偏差 
现在我们将最小化目标 C 变为一批(m个)训练数据的模型输出 y(x) 离标签 a 的偏差

随机梯度下降就是一次选取一批:m个训练数据进行一次梯度下降(参数更新),更新规则如下:

完!