目录
一、文本处理工具
1.1 grep
grep是文本搜索命令,会从一个或多个文件中搜索与指定匹配模式的文本行,并打印匹配结果,一般格式为: grep 【选项】【模式】【文件名】
模式是匹配规则,模式后的文件名用于指定搜索目标,文件名可以有多个,之间用空格隔开,模式前选项用于对模式进行补充说明
常用选项

grep与正则表达式配合使用,来达到搜索功能
1.1.1 匹配行首
正则表达式的元字符 “ ^ "表示匹配行首,使用 grep 搜索文本时使用 匹配行首字符进行行首的匹配
例如:grep -c ^$ /etc/yum.conf (查找yum.conf文件中有多少空白行)

1.1.2 设置大小写
使用 i 选项可以使用gerp命令不区分大小写,使用符号 [ ] 命令也可实现这一功能
例如:grep '[Tt] [Hh][Ii][Ss]'yum.conf (不区分大小写查找“this”字符串)

1.1.3 转义字符
若匹配的目标字符串中含有元字符,则需要使用转义字符 " \ " 屏蔽它们,常见的元字符有 " . " , " - " , 需要使用 " \ " 去进行转义
编写文件 test1
abcdef
---
123456
grep ' \ - \{ 3 \ } ' test(查找文件 test1中‘---’)

1.2 sed
sed 是 一个非交互式的文本处理信息,可以对文本文件和标准输入进行编辑,标准输入有 键盘 、文件重定向、 字符串、 变量等
使用环境:编辑命令复杂,文件过大、文本处理需要执行多个函数时使用该命令
优点:一次性处理所有编辑任务,提高效率,节约时间
格式:sed [选项] ' sed编辑命令 ’ 输入文件 (sed编辑命令要用单括号括起来)
常用选项:

编辑命令:

例如:sed ' = ' test1(显示行号输出文件test1)

1.2.1 追加文件
sed的编辑命令a\ 用于追加文本,它可以指定一行或多行文本追加到指定位置以 匹配模式 " /pattern/ "或行号形式给出,如果不指定,则默认放到每一行后面
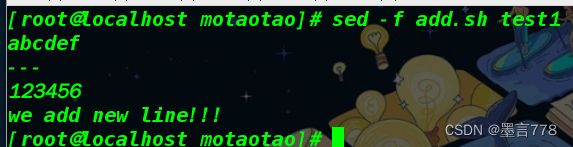
例如:sed ' /123456/a\add a new line!!! ' test1 (在文件内容后追加新文本 add a new line!!!)

追加文本脚本实现:
vi add.sh
/For rain/a\ we add a new line!!!
以上只是在标准输中对输出结果进行了追加,并没有讲这些新文本添加到原始文件中,如果要修改文件,需要使用 -i 选项
sed -f add.sh -i poem

1.2.2 删除文本
删除某一行,使用编辑命令d
sed '/we add new line!!!/d' test1

#! bin/sed -f
/For rain/a\
we add a new line!!!
add.sh中没有指定命令解释器,需要调用相应的命令来执行脚本
sed -f add.sh test1
在 add.sh 脚本文件中(第一行) 指定命令解释器
#! /bin/sed -f
1.3 awk
awk在读取分析数据时,从头到尾 逐行扫描文件内容 ,寻找指定模式匹配的行,并对匹配的文本进行处理,awk的工作流程分为 模式匹配 和 处理过程 两步, 两种特殊模式分为 BEGIN 和 END
awk中的匹配模式主要包括 关系表达式、正则表达式、混合模式、BEGIN、END
模式匹配:
1.如果没有指定匹配模式,则默认匹配所有数据
处理数据:
1.匹配则处理数据
2.不匹配则不做任何处理
3.未指定处理方式,则输出
两种特殊模式:
BEGIN:放置在读取数据之前执行,标志数据读取即将开始
END:放置在读取数据之后执行,标志数据读取已经完毕
命令基本格式:awk [选项] pattern {actions} 文件
pattern是匹配模式,actions 是要执行的操作,文本符合规则时,pattern 和 actions都是可选的,必须选择一个:
pattern 是 匹配模式(可选) 省略pattern则对所有文本执行actions操作
actions 是 执行的操作(可选) 省略actions则将匹配结果打印到终端
常用命令

1.3.1 关系表达式
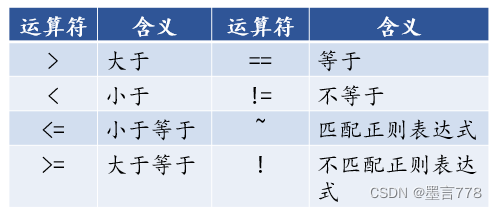
awk允许用户使用关系表达式作为匹配模式,当文件行满足关系表达式时,会执行相应操作
#! bin/bash
result = ` awk ' $2 > 80 {print} ' scores `
echo "$result"
变量$2 表示引用第二列的值, {print} 表示打印匹配成功的文本行
(变量$0:引用所有列的值 变量$NF:引用最后一列的值)