一、引言
我与队友共同参加了2021年美赛的F题,经过三天两夜的奋战,我们终于完成一篇长达25页的英文论文。
在此次美赛中,我们队共建立了三个模型。其中,前两个模型和编程主要是我负责,第三个和写作主要是他负责。因此,本文主要讲述我建立的前两个模型。
二、问题背景

上图为从官网下载下来的F题题目。历年的美赛题目和优秀论文,官网都是公开提供的,这是很好的学习资料。(虽然确实很难读懂)
翻译下来后,我们总结题目大概的两个目标:一是开发模型来评价高等教育系统的运行状况,二是确定系统可持续和健康的状态。(并给出状态转移时间)
三、建模实现
(1)DEA投入产出模型(评价模型)
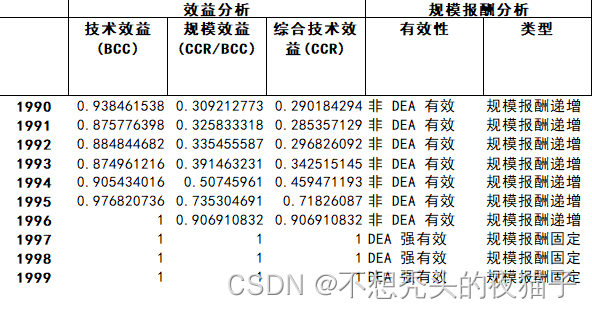
DEA投入产出模型(数据包络法)是评价多指标输入输出、衡量系统有效性的方法。模型下又分为几种模式,我们采用的是CCR模式,它是从资源投入的角度来评价。
根据相关文献和搜集到的样本数据,我们从投入的角度,定义了三个变量;从产出的角度定义了5个变量,来综合评价高等教育系统的有效性。
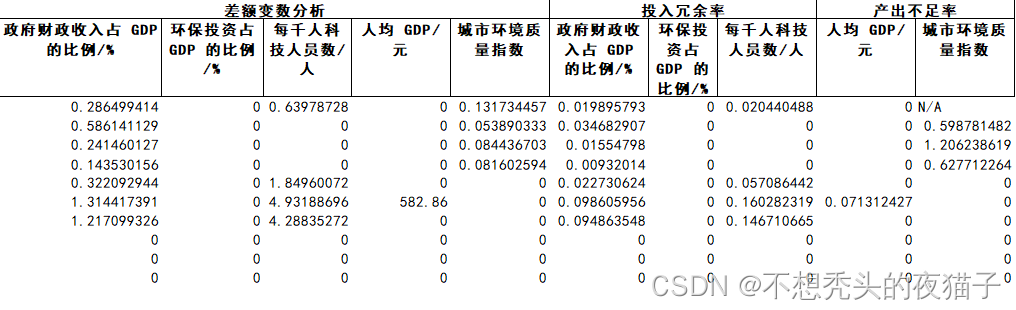
运行结果后,我们队从效益分析、规模报酬分析、投入冗余率和产出不足率四个角度出发,根据分析的结果对相关国家的高等系统提供改进建议。
以下代码易复现:
import gurobipy
import pandas as pd
# 分页显示数据, 设置为 False 不允许分页
pd.set_option('display.expand_frame_repr', False)
# 最多显示的列数, 设置为 None 显示全部列
pd.set_option('display.max_columns', None)
# 最多显示的行数, 设置为 None 显示全部行
pd.set_option('display.max_rows', None)
class DEA(object):
def __init__(self, DMUs_Name, X, Y, AP=False):
self.m1, self.m1_name, self.m2, self.m2_name, self.AP = X.shape[1], X.columns.tolist(), Y.shape[1], Y.columns.tolist(), AP
self.DMUs, self.X, self.Y = gurobipy.multidict({
DMU: [X.loc[DMU].tolist(), Y.loc[DMU].tolist()] for DMU in DMUs_Name})
print(f'DEA(AP={
AP}) MODEL RUNING...')
def __CCR(self):
for k in self.DMUs:
MODEL = gurobipy.Model()
OE, lambdas, s_negitive, s_positive = MODEL.addVar(), MODEL.addVars(self.DMUs), MODEL.addVars(self.m1), MODEL.addVars(self.m2)
MODEL.update()
MODEL.setObjectiveN(OE, index=0, priority=1)
MODEL.setObjectiveN(-(sum(s_negitive) + sum(s_positive)), index=1, priority=0)
MODEL.addConstrs(gurobipy.quicksum(lambdas[i] * self.X[i][j] for i in self.DMUs if i != k or not self.AP) + s_negitive[j] == OE * self.X[k][j] for j in range(self.m1))
MODEL.addConstrs(gurobipy.quicksum(lambdas[i] * self.Y[i][j] for i in self.DMUs if i != k or not self.AP) - s_positive[j] == self.Y[k][j] for j in range(self.m2))
MODEL.setParam('OutputFlag', 0)
MODEL.optimize()
self.Result.at[k, ('效益分析', '综合技术效益(CCR)')] = MODEL.objVal
self.Result.at[k, ('规模报酬分析', '有效性')] = '非 DEA 有效' if MODEL.objVal < 1 else 'DEA 弱有效' if s_negitive.sum().getValue() + s_positive.sum().getValue() else 'DEA 强有效'
self.Result.at[k, ('规模报酬分析', '类型')] = '规模报酬固定' if lambdas.sum().getValue() == 1 else '规模报酬递增' if lambdas.sum().getValue() < 1 else '规模报酬递减'
for m in range(self.m1):
self.Result.at[k, ('差额变数分析', f'{
self.m1_name[m]}')] = s_negitive[m].X
self.Result.at[k, ('投入冗余率', f'{
self.m1_name[m]}')] = 'N/A' if self.X[k][m] == 0 else s_negitive[m].X / self.X[k][m]
for m in range(self.m2):
self.Result.at[k, ('差额变数分析', f'{
self.m2_name[m]}')] = s_positive[m].X
self.Result.at[k, ('产出不足率', f'{
self.m2_name[m]}')] = 'N/A' if self.Y[k][m] == 0 else s_positive[m].X / self.Y[k][m]
return self.Result
def __BCC(self):
for k in self.DMUs:
MODEL = gurobipy.Model()
TE, lambdas = MODEL.addVar(), MODEL.addVars(self.DMUs)
MODEL.update()
MODEL.setObjective(TE, sense=gurobipy.GRB.MINIMIZE)
MODEL.addConstrs(gurobipy.quicksum(lambdas[i] * self.X[i][j] for i in self.DMUs if i != k or not self.AP) <= TE * self.X[k][j] for j in range(self.m1))
MODEL.addConstrs(gurobipy.quicksum(lambdas[i] * self.Y[i][j] for i in self.DMUs if i != k or not self.AP) >= self.Y[k][j] for j in range(self.m2))
MODEL.addConstr(gurobipy.quicksum(lambdas[i] for i in self.DMUs if i != k or not self.AP) == 1)
MODEL.setParam('OutputFlag', 0)
MODEL.optimize()
self.Result.at[k, ('效益分析', '技术效益(BCC)')] = MODEL.objVal if MODEL.status == gurobipy.GRB.Status.OPTIMAL else 'N/A'
return self.Result
def dea(self):
columns_Page = ['效益分析'] * 3 + ['规模报酬分析'] * 2 + ['差额变数分析'] * (self.m1 + self.m2) + ['投入冗余率'] * self.m1 + ['产出不足率'] * self.m2
columns_Group = ['技术效益(BCC)', '规模效益(CCR/BCC)', '综合技术效益(CCR)','有效性', '类型'] + (self.m1_name + self.m2_name) * 2
self.Result = pd.DataFrame(index=self.DMUs, columns=[columns_Page, columns_Group])
self.__CCR()
self.__BCC()
self.Result.loc[:, ('效益分析', '规模效益(CCR/BCC)')] = self.Result.loc[:, ('效益分析', '综合技术效益(CCR)')] / self.Result.loc[:,('效益分析', '技术效益(BCC)')]
return self.Result
def analysis(self, file_name=None):
Result = self.dea()
file_name = 'DEA 数据包络分析报告.xlsx' if file_name is None else f'\\{
file_name}.xlsx'
Result.to_excel(file_name, 'DEA 数据包络分析报告')
data = pd.DataFrame({
1990: [14.40, 0.65, 31.30, 3621.00, 0.00], 1991: [16.90, 0.72, 32.20, 3943.00, 0.09],1992: [15.53, 0.72, 31.87, 4086.67, 0.07], 1993: [15.40, 0.76, 32.23, 4904.67, 0.13],
1994: [14.17, 0.76, 32.40, 6311.67, 0.37], 1995: [13.33, 0.69, 30.77, 8173.33, 0.59],
1996: [12.83, 0.61, 29.23, 10236.00, 0.51], 1997: [13.00, 0.63, 28.20, 12094.33, 0.44],
1998: [13.40, 0.75, 28.80, 13603.33, 0.58], 1999: [14.00, 0.84, 29.10, 14841.00, 1.00]},
index=['政府财政收入占 GDP 的比例/%', '环保投资占 GDP 的比例/%', '每千人科技人员数/人', '人均 GDP/元', '城市环境质量指数']).T
X = data[['政府财政收入占 GDP 的比例/%', '环保投资占 GDP 的比例/%', '每千人科技人员数/人']]
Y = data[['人均 GDP/元', '城市环境质量指数']]
dea = DEA(DMUs_Name=data.index, X=X, Y=Y)
dea.analysis() # dea 分析并输出表格
print(dea.dea()) # dea 分析,不输出结果
以下是代码运行出的结果,保存至Excel表格中:
(2)逻辑回归模型
我们认为一个健康的高等教育系统能够保证人人平等的享有受教育的权利。因此,我们建立逻辑回归模型。将是否接受过高等教育作为因变量,1代表接受,0代表未接受。
由于过长,截取部分代码如下:
import pandas as pd
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
import statsmodels.formula.api as smf
data = pd.read_excel(r'F:\Desktop\logistic_model\Stratum_processed_data.xls')
data = data.ix[:,1:]
col = list(data.columns)
data[col] = data[col].apply(pd.to_numeric, errors='coerce').fillna(0.0)
data = pd.DataFrame(data, dtype='float')
# 指定作为训练变量的列,不含目标列`admit`
train_cols = data.columns[0:14]
y=data.columns[14]
logit = sm.Logit(data[y], data[train_cols])
result=logit.fit()
print(result.summary())
#查看各个系数的置信区间
print(result.conf_int())
#用置信区间来估计系数的影响
params = result.params
conf = result.conf_int()
conf['OR'] = params
conf.columns = ['2.5%', '97.5%', 'OR']
print(np.exp(conf))
print(np.exp(result.params))
#深入挖掘预测
DB=np.linspace(data['D/B'].min(),data['D/B'].max(),5)
Region=np.linspace(data['Region'].min(),data['Region'].max(),5)
Gender=np.linspace(data['Gender'].min(),data['Gender'].max(),5)
Race=np.linspace(data['Race'].min(),data['Race'].max(),5)
Parents_education_background=np.linspace(data["Parents' education background"].min(),data["Parents' education background"].max(),5)
Household_income=np.linspace(data['Household income'].min(),data['Household income'].max(),5)
#Stratum=np.linspace(data['Stratum'].min(),data['Stratum'].max(),10)
R_and_u_areas=np.linspace(data['Rural and urban areas'].min(),data['Rural and urban areas'].max(),5)
import numpy as np
def cartesian(arrays):
arrays = [np.asarray(a) for a in arrays]
shape = (len(x) for x in arrays)
ix = np.indices(shape, dtype=int)
ix = ix.reshape(len(arrays), -1).T
for n, arr in enumerate(arrays):
ix[:, n] = arrays[n][ix[:, n]]
return ix
#如上自定义一个辅助函数创建矩阵
comobs=pd.DataFrame(cartesian([DB,Region,Gender,Race,Parents_education_background,Household_income,R_and_u_areas,[1,2,3,4,5,6],[1.]]))
#使用模型来预测数据,同样添加了虚拟变量Stratum
comobs.columns=['DB','Region','Gender','Race','Parents_education_background','Household_income','R_and_u_areas','Stratum','intercept']
dummy_ranks=pd.get_dummies(comobs['Stratum'],prefix='Stratum')
dummy_ranks.columns=['Stratum_1','Stratum_2','Stratum_3','Stratum_4','Stratum_5','Stratum_6']
cols_to_keep=['DB','Region','Gender','Race','Parents_education_background','Household_income','R_and_u_areas','Stratum','intercept']
comobs=comobs[cols_to_keep].join(dummy_ranks.ix[:,'Stratum_2':])
train_clos = comobs.columns[0:14]
comobs['recipient_pred']=result.predict(comobs[train_clos])
comobs.to_csv(r'F:\Desktop\logistic_model\comobs.csv')
由于样本数据的限制,以及我们队对于虚拟变量的处理还不够成熟,逻辑回归模型运行出来的结果不尽如人意。这里就不放上运行结果了。
最后实现的功能是:能够通过一组样本数据判断该系统是否健康;以及我们选取了各变量的回归系数,将它作为特征重要度,判断哪个因素对因变量的影响最大。
四、总结
DEA投入产出模型很大程度上参考https://zhuanlan.zhihu.com/p/60853027
在此感谢这位兄弟(姐妹)。
后面看过随机过程,了解到马氏链、转移矩阵那些,发现此题的第二问确定状态以及状态转移的时间,其实非常适合用马氏链来做。希望之后遇到这类题目可以有更多思路把!
兄弟姐妹们,有任何问题,可以在评论区留言。我看到回复。