文章目录
一、什么是享元模式
享元模式(Flyweight Pattern)也叫蝇量模式,又称为轻量级模式,是对象池的一种实现。类似于线程池,线程池可以避免不停的创建和销毁多个对象,消耗性能。提供了减少对象数量从而改善应用所需的对象结构的方式。其宗旨是共享细粒度对象,将多个对象的访问集中起来,不比为每个访问者创建一个单独的对象,以此来降低内存的消耗,属于结构型模式。
面向对象技术可以很好地解决一些灵活性或可扩展性问题,但在很多情况下需要在系统中增加类和对象的个数。当对象数量太多时,将导致运行代价过高,带来性能下降等问题。享元模式正是为解决这一类问题而诞生的。
享元模式把一个对象的状态分成内部状态和外部状态,内部状态是不变的,外部状态是变化的;然后通过共享不变的部分,达到减少对象数量并节约内存的目的。
享元模式的本质是缓存共享对象,降低内存消耗。
1、享元模式的角色
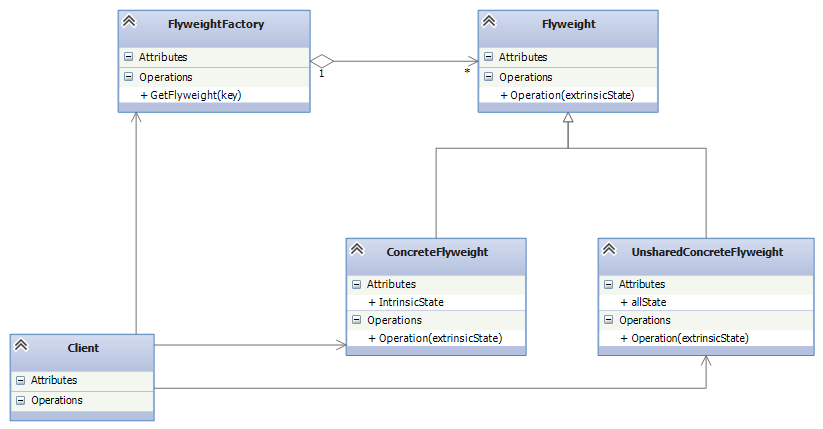
享元模式的主要有以下角色:
- 抽象享元角色(Flyweight):通常是一个接口或抽象类,在抽象享元类中声明了具体享元类公共的方法,这些方法可以向外界提供享元对象的内部数据(内部状态),同时也可以通过这些方法来设置外部数据(外部状态)。
- 具体享元(Concrete Flyweight)角色 :它实现了抽象享元类,称为享元对象;在具体享元类中为内部状态提供了存储空间。通常我们可以结合单例模式来设计具体享元类,为每一个具体享元类提供唯一的享元对象。该角色的内部状态处理应该与环境无关,不能出现会有一个操作改变内部状态,同时修改了外部状态。
- 非享元(Unsharable Flyweight)角色 :并不是所有的抽象享元类的子类都需要被共享,不能被共享的子类可设计为非共享具体享元类;当需要一个非共享具体享元类的对象时可以直接通过实例化创建。
- 享元工厂(Flyweight Factory)角色 :负责创建和管理享元角色。当客户对象请求一个享元对象时,享元工厂检査系统中是否存在符合要求的享元对象,如果存在则提供给客户;如果不存在的话,则创建一个新的享元对象。
2、享元模式应用场景
当系统中多处需要同一组信息时,可以把这些信息封装到一个对象中,然后对该对象进行缓存,这样,一个对象就可以提供给多处需要使用的地方,避免大量同一对象的多次创建,消耗大量内存空间。
享元模式其实就是工厂模式的一个改进机制,享元模式同样要求创建一个或一组对象,并且就是通过工厂方法生成对象的,只不过享元模式中为工厂方法增加了缓存这一功能。主要总结为以下应用场景:
- 一个系统有大量相同或者相似的对象,造成内存的大量耗费。
- 对象的大部分状态都可以外部化,可以将这些外部状态传入对象中。
- 在使用享元模式时需要维护一个存储享元对象的享元池,而这需要耗费一定的系统资源,因此,应当在需要多次重复使用享元对象时才值得使用享元模式。
3、享元模式的内部状态和外部状态
享元模式的定义为我们提出了两个要求:细粒度和共享对象。因为要求细粒度对象,所以不可避免地会使对象数量多且性质相近,此时我们就将这些对象的信息分为两个部分:内部状态和外部状态。
- 内部状态,即不会随着环境的改变而改变的可共享部分,对象共享出来的信息。
- 外部状态,指随环境改变而改变的不可以共享的部分。
享元模式的实现要领就是区分应用中的这两种状态,并将外部状态外部化。
比如,连接池中的连接对象,保存在连接对象中的用户名、密码、连接url等信息,在创建对象的时候就设置好了,不会随环境的改变而改变,这些为内部状态。而每个连接要回收利用时,我们需要给它标记为可用状态,这些为外部状态。
4、享元模式的优缺点
优点:
- 减少对象的创建,降低内存中对象的数量,降低系统的内存,提高效率;
- 减少内存之外的其他资源占用。
缺点:
- 关注内、外部状态、关注线程安全问题;
- 使系统、程序的逻辑复杂化。
5、享元模式跟单例的区别
在单例模式中,一个类只能创建一个对象,而在享元模式中,一个类可以创建多个对象,每个对象被多处代码引用共享。实际上,享元模式有点类似于单例的变体:多例。
其实,区别两种设计模式,不能光看代码实现,而是要看设计意图,也就是要解决的问题。尽管从代码实现上来看,享元模式和多例有很多相似之处,但从设计意图上来看,它们是完全不同的。应用享元模式是为了对象复用,节省内存,而应用单例模式是为了限制对象的个数。
6、享元模式跟缓存的区别
在享元模式的实现中,我们通过工厂类来“缓存”已经创建好的对象。这里的“缓存”实际上是“存储”的意思,跟我们平时所说的“数据库缓存”“CPU 缓存”“MemCache 缓存”是两回事。我们平时所讲的缓存,主要是为了提高访问效率,而非复用。
7、享元模式注意事项及细节
- 享元模式这样理解:“享”就是共享, “元”表示对象。
- 系统中有大量对象,这些对象消耗大量内存,并且对象的状态大部分可以外部化时,我们就可以考虑选用享元模式。
- 用唯一标识码判断,如果在内存中有,则返回这个唯一标识码所标识的对象,用HashMap/HashTable存储。
- 享元模式大大减少了对象的创建,降低了程序内存的占用,提高效率。
- 享元模式提高了系统的复杂度。需要分理出内部状态和外部状态,而外部状态具有固化特性,不应该随着内部状态的改变而改变,这是我们使用享元模式需要注意的地方。
- 使用享元模式时,注意划分内部状态和外部状态,并且需要有一个工厂类加以控制。
- 享元模式经典的应用场景是需要缓冲池的场景,比如String常量池、数据库连接池等。
二、实例
1、享元模式一般写法
// 抽象享元角色
public interface IFlyweight {
void operation(String extrinsicState);
}
// 具体享元角色
public class ConcreteFlyweight implements IFlyweight {
private String intrinsicState;
public ConcreteFlyweight(String intrinsicState) {
this.intrinsicState = intrinsicState;
}
public void operation(String extrinsicState) {
System.out.println("Object address: " + System.identityHashCode(this));
System.out.println("IntrinsicState: " + this.intrinsicState);
System.out.println("ExtrinsicState: " + extrinsicState);
}
}
// 享元工厂
public class FlyweightFactory {
private static Map<String, IFlyweight> pool = new HashMap<String, IFlyweight>();
// 因为内部状态具备不变性,因此作为缓存的键
public static IFlyweight getFlyweight(String intrinsicState) {
if (!pool.containsKey(intrinsicState)) {
IFlyweight flyweight = new ConcreteFlyweight(intrinsicState);
pool.put(intrinsicState, flyweight);
}
return pool.get(intrinsicState);
}
}
public class Test {
public static void main(String[] args) {
IFlyweight flyweight1 = FlyweightFactory.getFlyweight("aa");
IFlyweight flyweight2 = FlyweightFactory.getFlyweight("bb");
flyweight1.operation("a");
flyweight2.operation("b");
}
}
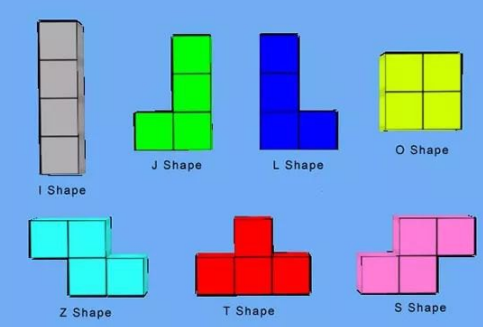
2、俄罗斯方块案例
下面的图片是众所周知的俄罗斯方块中的一个个方块,如果在俄罗斯方块这个游戏中,每个不同的方块都是一个实例对象,这些对象就要占用很多的内存空间,下面利用享元模式进行实现。
看一下类图:
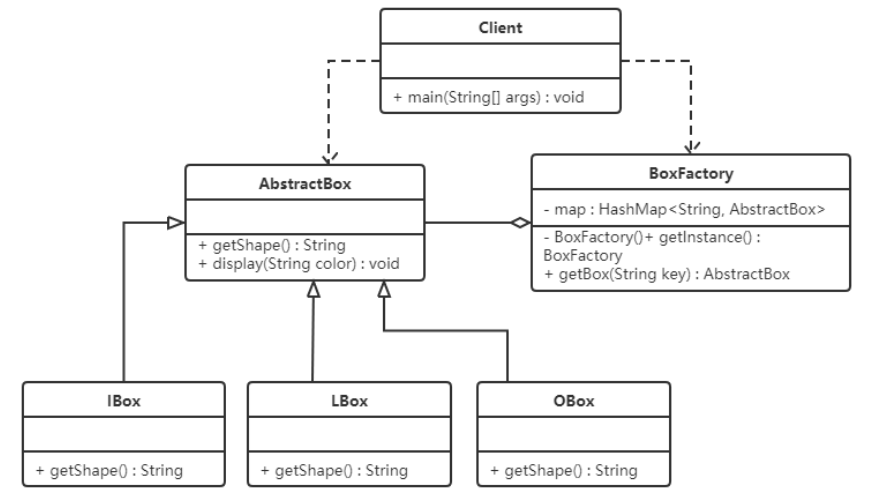
俄罗斯方块有不同的形状,我们可以对这些形状向上抽取出AbstractBox,用来定义共性的属性和行为。
// 抽象
public abstract class AbstractBox {
public abstract String getShape();
public void display(String color) {
System.out.println("方块形状:" + this.getShape() + " 颜色:" + color);
}
}
定义不同的形状,IBox类、LBox类、OBox类等。
public class IBox extends AbstractBox {
@Override
public String getShape() {
return "I";
}
}
public class LBox extends AbstractBox {
@Override
public String getShape() {
return "L";
}
}
public class OBox extends AbstractBox {
@Override
public String getShape() {
return "O";
}
}
提供了一个工厂类(BoxFactory),用来管理享元对象(也就是AbstractBox子类对象),该工厂类对象只需要一个,所以可以使用单例模式。并给工厂类提供一个获取形状的方法。
public class BoxFactory {
private static HashMap<String, AbstractBox> map;
private BoxFactory() {
map = new HashMap<String, AbstractBox>();
AbstractBox iBox = new IBox();
AbstractBox lBox = new LBox();
AbstractBox oBox = new OBox();
map.put("I", iBox);
map.put("L", lBox);
map.put("O", oBox);
}
public static final BoxFactory getInstance() {
return SingletonHolder.INSTANCE;
}
private static class SingletonHolder {
private static final BoxFactory INSTANCE = new BoxFactory();
}
public AbstractBox getBox(String key) {
return map.get(key);
}
}
3、购票业务案例
逢年过节会有火车票刷票软件,刷票软件会将我们填写的信息缓存起来,然后定时检查余票信息。抢票的时候,我们肯定是要查询下有没有我们需要的票信息,这里我们假设一张火车的信息包含:出发站、目的站、价格、座位类别。现在要求编写一个查询火车票的功能,可以通过出发站、目的站查到相关票的信息。
public interface ITicket {
void showInfo(String bunk);
}
// 具体票
public class TrainTicket implements ITicket {
private String from;
private String to;
private int price;
public TrainTicket(String from, String to) {
this.from = from;
this.to = to;
}
public void showInfo(String bunk) {
this.price = new Random().nextInt(500);
System.out.println(String.format("%s->%s:%s价格:%s 元", this.from, this.to, bunk, this.price));
}
}
// 抢票工厂
public class TicketFactory {
private static Map<String, ITicket> sTicketPool = new ConcurrentHashMap<String,ITicket>();
public static ITicket queryTicket(String from, String to) {
return new TrainTicket(from, to);
}
}
编写客户端代码:
public static void main(String[] args) {
ITicket ticket = TicketFactory.queryTicket("北京西", "长沙");
ticket.showInfo("硬座");
ticket = TicketFactory.queryTicket("北京西", "长沙");
ticket.showInfo("软座");
ticket = TicketFactory.queryTicket("北京西", "长沙");
ticket.showInfo("硬卧");
}
以上代码,我们发现客户端进行查询时,系统通过TicketFactory直接创建一个火车票对象,这样的话,某个瞬间如果有大量的用户请求同一张票信息时,会创建大量火车票对象,系统压力骤增。更好的方式是使用缓存,复用票对象:
// 使用缓存
public class TicketFactory {
private static Map<String, ITicket> sTicketPool = new ConcurrentHashMap<String,ITicket>();
public static ITicket queryTicket(String from, String to) {
String key = from + "->" + to;
if (TicketFactory.sTicketPool.containsKey(key)) {
System.out.println("使用缓存:" + key);
return TicketFactory.sTicketPool.get(key);
}
System.out.println("首次查询,创建对象: " + key);
ITicket ticket = new TrainTicket(from, to);
TicketFactory.sTicketPool.put(key, ticket);
return ticket;
}
}
其中ITicket就是抽象享元角色,TrainTicket就是具体享元角色,TicketFactory就是享元工厂。其实这种方式,非常类似于注册式单例模式。
4、数据库连接池案例
我们经常使用的数据库连接池,因为我们使用Connection对象时主要性能消耗在建立连接和关闭连接的时候,为了提高Connection在调用时的性能,我们将Connection对象在调用前创建好进行缓存,用的时候从缓存取,用完再放回去,达到资源重复利用的目的。
public class ConnectionPool {
private Vector<Connection> pool;
private String url = "jdbc:mysql://localhost:3306/test";
private String username = "";
private String password;
private String driverClassName = "com.mysql.jdbc.Driver";
private int poolSize = 100;
public ConnectionPool() {
pool = new Vector<Connection>(poolSize);
try{
Class.forName(driverClassName);
for (int i = 0; i < poolSize; i++) {
Connection conn = DriverManager.getConnection(url,username,password);
pool.add(conn);
}
}catch (Exception e){
e.printStackTrace();
}
}
public synchronized Connection getConnection(){
if(pool.size() > 0){
Connection conn = pool.get(0);
pool.remove(conn);
return conn;
}
return null;
}
public synchronized void release(Connection conn){
pool.add(conn);
}
}
public static void main(String[] args) {
ConnectionPool pool = new ConnectionPool();
Connection conn = pool.getConnection();
System.out.println(conn);
}
类似这样的连接池,普遍应用于开发框架,提高性能。
三、源码中的享元模式
1、String字符串常量池
更多字符串常量池请移步:
String的Intern()方法,详解字符串常量池!
Java将String类定义为final(不可改变的),JVM中字符串一般保存在字符串常量池中,java会确保一个字符串在常量池中只有一个拷贝,这个字符串常量池在JDK6.0以前是位于永久代,而在JDK7.0中,JVM将其从永久代拿出来放置于堆中。
String s1 = "hello";
String s2 = "hello";
String s3 = "he" + "llo";
String s4 = "hel" + new String("lo");
String s5 = new String("hello");
String s6 = s5.intern();
String s7 = "h";
String s8 = "ello";
String s9 = s7 + s8;
// 由于s2指向的字面量 hello 在常量池中已经存在了(s1先于s2),于是JVM就返回这个字面量绑定的引用,所以s1 == s2
System.out.println(s1==s2);//true
// s3字面量的拼接其实就是 hello ,JVM在编译期间就已经做了优化,所以s1 == s3
System.out.println(s1==s3);//true
// new String("lo")生成了两个对象,lo和String("lo"),lo存在于字符串常量池中,String("lo")存在于堆中,s4其实是两个对象的相加,编译器不会进行优化,相加的结果存在堆中,而s1存在字符串常量池中,不相等
System.out.println(s1==s4);//false
// 同上
System.out.println(s1==s9);//false
// 都在堆中
System.out.println(s4==s5);//false
// intern方法能使一个位于堆中的字符串在运行期间动态地加入到字符串常量池中,并返回字符串常量池的引用
System.out.println(s1==s6);//true
以字面量的形式创建String变量时,JVM会在编译期间就把该字面量“hello”放到字符串常量池中,由Java程序启动的时候就已经加载到内存中了。这个字符串常量池的特点就是有且只有一份相同的字面量,如果有其它相同的字面量,JVM则返回这个字面量的引用,如果没有相同的字面量,则在字符串常量池创建这个字面量并返回它的引用。
2、Integer常量池
Integer a = Integer.valueOf(100);
Integer b = 100;
Integer c = Integer.valueOf(1000);
Integer d = 1000;
System.out.println("a==b:" + (a==b)); // true
System.out.println("c==d:" + (c==d)); // false
Integer的valueOf方法默认的话先从缓存获取:
static final int low = -128;
static final int high = 127; // 静态代码块初始化的
@IntrinsicCandidate
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
h = Math.max(parseInt(integerCacheHighPropValue), 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(h, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
// Load IntegerCache.archivedCache from archive, if possible
CDS.initializeFromArchive(IntegerCache.class);
int size = (high - low) + 1;
// Use the archived cache if it exists and is large enough
if (archivedCache == null || size > archivedCache.length) {
Integer[] c = new Integer[size];
int j = low;
for(int i = 0; i < c.length; i++) {
c[i] = new Integer(j++);
}
archivedCache = c;
}
cache = archivedCache; // 初始化缓存
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
我们发现,Integer源码的valueOf方法做了一个判断,如果目标值在-128到127之间,则直接取缓存,否则创建新对象。为什么呢?因为-128到127之间的数据在int范围是使用最频繁的,为了节省频繁创建对象带来的内存消耗,这里就利用了享元模式,提高性能。
3、Long常量池
同样的,Long也有缓存,只不过无法指定最大值:
@IntrinsicCandidate
public static Long valueOf(long l) {
final int offset = 128;
if (l >= -128 && l <= 127) {
// will cache
return LongCache.cache[(int)l + offset];
}
return new Long(l);
}
参考资料
http://www.uml.org.cn/sjms/202105262.asp