目录

1.决策树分类算法概述及相关公式
(1)基本思路
决策树(decision tree)分类算法是一种逼近离散函数值的方法,是一种典型的分类算法。首先对已有分类好的数据进行处理,归纳出其中的规则并生成决策树;然后根据生成的决策树对新输入数据进行分析并判断属于哪一类别。
(2)熵公式
熵公式:
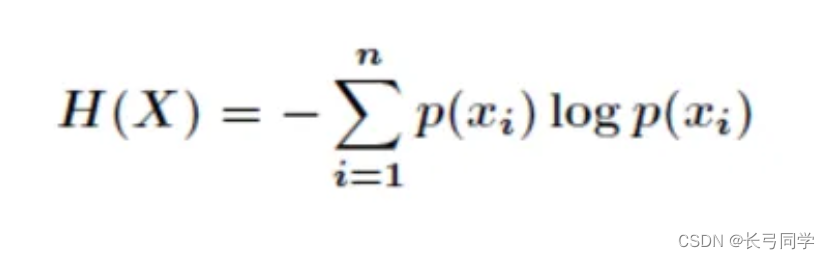
条件熵公式:
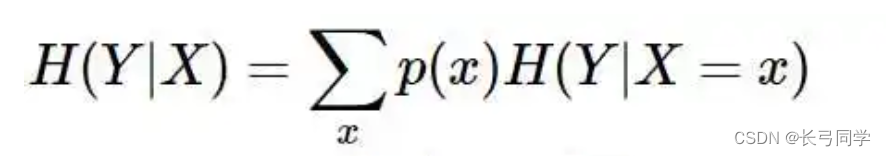
信息增益公式:

(3)基尼(Gini)系数公式
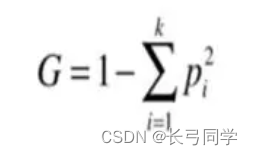
2.ID3算法
具体步骤:
(1)从根节点开始,对节点计算所有可能特征的信息增益,将信息增益最大的特征作为该节点。
(2)由该特征的取值建立子节点,再对子节点重复调用以上方法并建立下一个子节点。
(3)重复以上两步,直到没有特征可以选择为止。
3.C4.5算法
以信息增益作为划分训练数据集的特征,存在偏向于选择取值比较多的特征的问题(是对ID3算法的优化)
具体步骤:
(1)从根节点开始,对节点计算所有可能特征的信息增益。
(2)结合各个特征的熵,求出所有可能特征的信息增益比。
(3)比较各信息增益比,选择信息增益比最大的作为根节点。
(4)由该特征的取值建立子节点。
(5)重复上述步骤,直至特征选择完毕为止。
4.CART算法
CART算法假设决策树是二叉树,内部节点特征的取值为0(否)或1(是),通常左取值为1,右取值为0。
具体步骤:
(1)在训练数据集所在的样本空间,递归地将每一个特征划分为两个区域
(2)根据基尼求解公式计算基尼系数
(3)选择基尼系数最小的特征作为最优特征,其对应切分作为最优切分点
(4)根据切分点将训练集特征分配到其两个子节点中
(5)重复以上步骤
(6)若样本个数小于阈值,或者基尼系数小于阈值,或者特征已经使用完毕,则停止计算。
5.各类决策树分类算法比较
| 算法 | 支持模型 | 树结构 | 特征选择 | 连续值处理 | 缺失值处理 | 剪枝 |
| ID3 | 分类 | 多叉树 | 信息增益 | 不支持 | 不支持 | 不支持 |
| C4.5 |
分类 | 多叉树 | 信息增益比 | 支持 | 支持 | 支持 |
| CART | 分类、回归 | 二叉树 | 基尼系数、均方差 | 支持 | 支持 | 支持 |
6.过拟合与决策树剪枝
(1)过拟合(overfitting)
若一个模型,在训练集上的效果很好,但在测试集上效果很差,则称出现了过拟合现象(就相当于一个学生对课本上的题进行死记硬背,结果在考试的时候换了一种出题方法就不会了,一般管这种就叫过拟合)
决策树十分容易过拟合,但是可以通过剪枝的方式来减小这个问题。
(2)决策树剪枝方法
1.先剪枝:
提前定义一个高度或者阈值,限制决策树的自由生长
2.后剪枝
常用方法:REP(reduced-error pruning,错误率降低剪枝),CCP(cost-complexity pruning,代价复杂度剪枝)
7.决策树实战(Iris数据集的训练)
(1)Iris数据集:
也称鸢尾花数据集,是一类多重变量分析的数据集。该数据集包含150个数据样本,分为3类,每一类有50条数据,每条数据又包含4个属性值。可以通过这4个属性值来预测某一朵鸢尾花属于哪个类别。
(2)实战开始
为了最后查看保存的决策树dot文件,需要在python的设置里下载下图的插件:
那么让我们开始吧!
1.导入Iris数据集并实例化
代码:
import pandas as pd
# classification_report用来显示主要分类指标的文本报告
from sklearn.metrics import classification_report
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.tree import export_graphviz
# 加载数据
iris=load_iris()
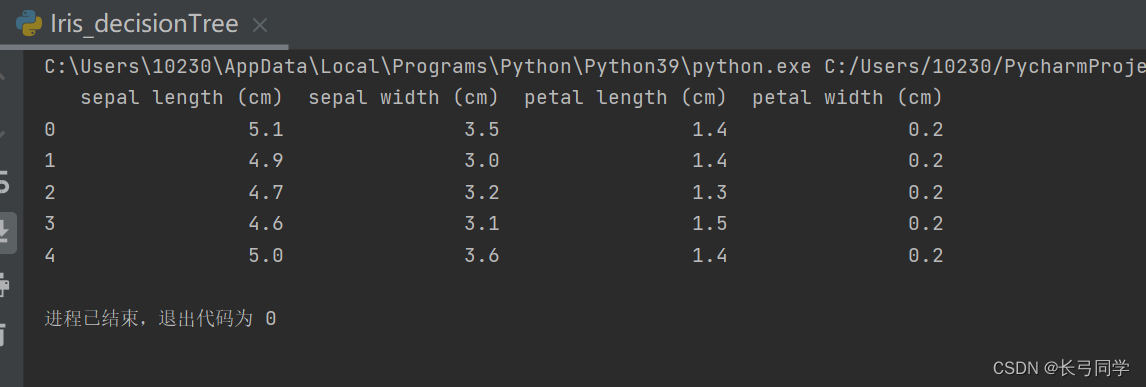
irisdf=pd.DataFrame(iris.data,columns=iris.feature_names)
print(irisdf.head(5))运行结果:
2.训练模型
代码:
dct=DecisionTreeClassifier()
dct.fit(iris.data,iris.target)3.显示精确度(precision)、召回率(recall)和F1分数等模型评估参数
代码:
print(classification_report(iris.target,dct.predict(iris.data)))运行结果如下:

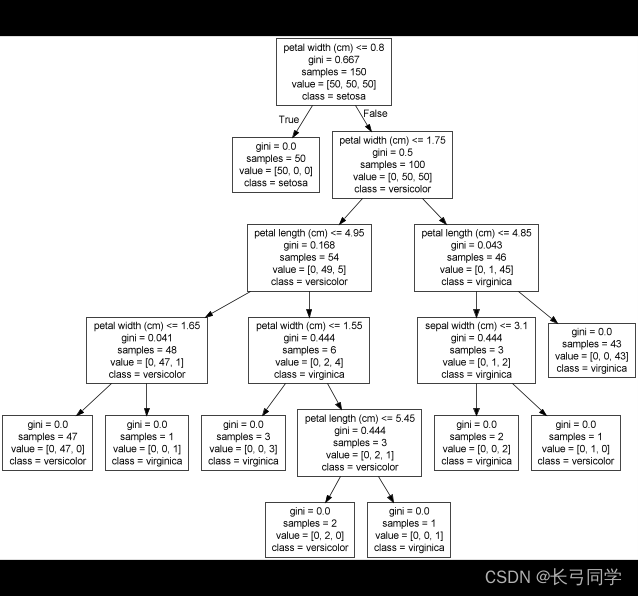
4.使用export_graphviz将决策树保存为dot文件,并打开下载完GraphViz后的gvedit.exe查看决策树
export_graphviz(dct,out_file='tree1.dot',feature_names=iris.feature_names,class_names=iris.target_names)运行结果:(决策树结构可视化)
8.iris数据集实战完整代码
(可以根据自身的需要进行修改和添加可视化的结果)
import pandas as pd
# classification_report用来显示主要分类指标的文本报告(显示模型各项指标)
from sklearn.metrics import classification_report
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
# export_graphviz将决策树保存为dot文件,并打开下载完GraphViz后的gvedit.exe查看决策树
from sklearn.tree import export_graphviz
# 加载数据
iris=load_iris()
irisdf=pd.DataFrame(iris.data,columns=iris.feature_names)
dct=DecisionTreeClassifier()
dct.fit(iris.data,iris.target)
print(classification_report(iris.target,dct.predict(iris.data)))
export_graphviz(dct,out_file='tree1.dot',feature_names=iris.feature_names,class_names=iris.target_names)