Joint Object Detection and Multi-Object Tracking with Graph Neural Networks
论文链接:https://arxiv.org/pdf/2006.13164v3.pdf
论文代码:https://github.com/yongxinw/GSDT
Abstract: Object detection and Data association are critical components in multi-object tracking (MOT) systems. Despite the fact that the two components are dependent on each other, prior works often design detection and data association modules separately which are trained with separate objectives. As a result, one cannot back-propagate the gradients and optimize the entire MOT system, which leads to sub-optimal performance. To address this issue, recent works simultaneously optimize detection and data association modules under a joint MOT framework, which has shown improved performance in both modules. In this work, we propose a new instance of joint MOT approach based on Graph Neural Networks (GNNs). The key idea is that GNNs can model relations between variablesized objects in both the spatial and temporal domains, which is essential for learning discriminative features for detection and data association. Through extensive experiments on the MOT15/16/17/20 datasets, we demonstrate the effectiveness of our GNN-based joint MOT approach and show state-of-the-art performance for both detection and MOT tasks. Our code is available at: https://github.com/yongxinw/GSDT.
摘要:目标检测和数据关联是多目标跟踪系统的关键组成部分。尽管这两个组件相互依赖,但之前的工作通常会分别设计检测和数据关联模块,这些模块的训练目标不同,因此,无法反向传播梯度并优化整个MOT系统,从而导致次优性能。为了解决这个问题,最近的工作在联合MOT框架下同时优化了检测和数据关联模块,这两个模块的性能都有所提高。在这项工作中,我们提出了一种基于图神经网络(GNNs)的联合MOT方法的新实例。其关键思想是,GNN可以在空间和时间域中建模可变大小对象之间的关系,这对于学习用于检测和数据关联的鉴别特征至关重要。
1. 前言
目标检测和数据关联是多目标跟踪(Multiple Object Tracking, MOT)中的两个部分,通常用于tracking-by-detection范式的在线MOT中。检测器输出检测结果,然后由数据关联模块将检测结果与过去的轨迹匹配,以形成新的轨迹延续到当前帧。通常,检测器和数据关联模块分别训练。然而,通过这个单独的优化过程,我们不能在整个MOT系统中反向传播。换句话说,每个模块只针对其自身的局部最优进行优化,而不是针对MOT的目标进行优化。因此,以前工作中使用的这种单独的优化程序通常会产生次优性能。
联合MOT框架中,如何学习到更具有判别性的特征:先前的工作要么利用边界框前后直接关联,去除了数据关联部分;要么无法联合优化,仅数据关联。
为了解决这个问题,我们提出了联合MOT框架的新方法,此方法能为目标检测和数据关联统一建模目标间关系。此外,为了表征更具有判别性的特征,我们使用GNN去挖掘目标间关系。然后,将获得的特征用于检测和数据关联的任务。使用GNN,每个目标提取出的特征不再是孤立的,而是可以通过其相关对象在空间和时间域中的特征进行调整(GNN能聚合周围目标特征)。
据我们所知,我们的工作是第一次在联合MOT框架中通过GNN建模对象关系。之前工作的限制:
- 在忽略对象关系的情况下执行MOT
- 对关联中的对象关系进行建模,但不能解决联合MOT问题,也不能使用对象关系来改进检测。
2. 创新点
一种联合MOT方法,通过GNN建模对象关系,以改进检测和数据关联;
这篇文章是优化JDE或FairMOT范式的,具体方式为,单一的目标检测只用了当前帧的属性,而没有使用前后帧的目标信息,因此此网络将GNN融入到目标检测框架中,形成统一的框架,在训练时,每个目标都融合了先前帧目标信息。
总结:
- 考虑了JDE中存在的Detection和ReID的时序问题,利用了先前帧目标的信息
- 将GNN完整地融入到了Detection中,端到端一次性训练
- 每个目标的特征都随着检测器的检测也在不断更新
- 方法还是传统的tracking-by-detection范式,再匈牙利算法做数据关联
3. 方法
我们的方法是Online的。给定第 t − 1 t-1 t−1帧的图像 F t − 1 F_{t-1} Ft−1、第 t t t帧的图像 F t F_t Ft、第 t − 1 t-1 t−1帧的轨迹段 T t − 1 = { T t − 1 1 , T t − 1 2 , T t − 1 P t − 1 } T_{t-1}=\{ T_{t-1}^1,\;T_{t-1}^2,\;T_{t-1}^{P_{t-1}} \} Tt−1={ Tt−11,Tt−12,Tt−1Pt−1}。我们旨在图像 F t F_t Ft中检测出目标 D t = { D t 1 , D t 2 , D t K t } D_t=\{ D_t^1,\; D_t^2,\; D_t^{K_t} \} Dt={ Dt1,Dt2,DtKt},然后 D t D_t Dt和 T t − 1 T_{t-1} Tt−1数据关联。其中 K t K_t Kt代表检测出的目标数量, P t − 1 P_{t-1} Pt−1表示轨迹段的数量。通过将检测结果关联到过去的轨迹,我们可以确定是连接或终止现有轨迹,还是在第t帧启动新的轨迹。我们在每一帧迭代执行此过程,以获得整个视频的轨迹。
注:到目前为止,都是tracking-by-detection常见范式,先检测,再帧间关联。
为了同时检测和关联MOT的对象,我们在模型中集成了一个检测器和一个Re ID模块。然而,单独这样做并不能利用时空对象关系。因此,我们使用GNNs来提取对象之间的关系,并学习更好的特征,以改进检测和数据关联。由于我们使用GNN同时进行检测和跟踪,我们将我们的方法缩写为GSDT(GNNs for Simultaneous Detection and Tracking)。
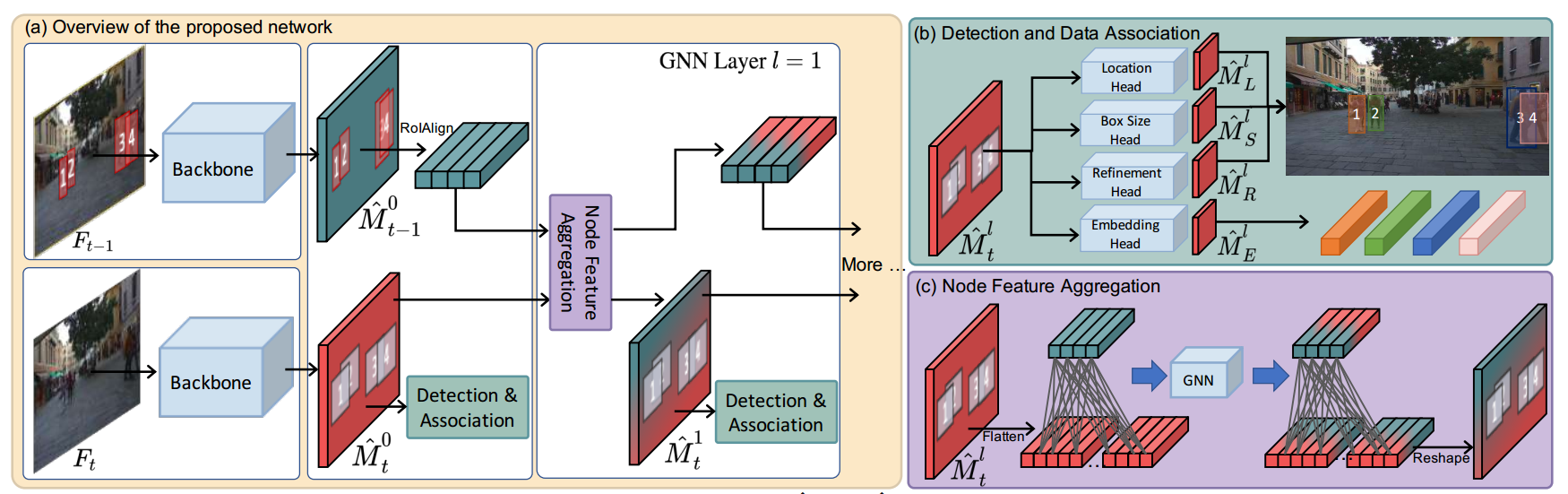
a. Overview of the proposed network
-
首先通过目标检测算法提取出 F t − 1 F_{t-1} Ft−1和 F t F_t Ft的特征 M ^ t − 1 0 \hat{M}_{t-1}^0 M^t−10和 M ^ t 0 \hat{M}_{t}^0 M^t0。
-
为了获得轨迹 T t − 1 T_{t-1} Tt−1的每个特征,算法采用RoIAlign从 M ^ t − 1 0 \hat{M}_{t-1}^0 M^t−10上裁剪轨迹( M ^ t − 1 0 \hat{M}_{t-1}^0 M^t−10上的red box)的特征,称为tracklets的特征
-
为了获得潜在检测结果 D t D_t Dt的每个特征,算法采用 M ^ t 0 \hat{M}_{t}^0 M^t0中的每个像素的特征,称为potential detections的特征
-
为了构造边数可控的图,我们只在tracklets和potential detections的特征之间构建边,且potential detections的空间距离要和tracklets在一个窗口内( M ^ t 0 \hat{M}_{t}^0 M^t0上的grey box)
-
利用构造的图,执行3层GNN,使用node feature aggregation更新tracklets和potential detections的特征
-
Detection & Association头作用于每层GNN以获得检测结果和匹配结果
b. Detection & Association head
location head、box size head、refinement head用于生成检测结果
embedding head用于生成ID嵌入用于数据关联
c.Node Feature Aggregation
混合颜色说明来自tracklets和potential detections的特征通过图网络的聚合方式相互影响
A. 特征提取和目标检测
给定输入图像 F t − 1 F_{t-1} Ft−1和 F t F_t Ft,使用DLA-34作为Backbone生成特征图 M ^ t − 1 0 , M ^ t 0 ∈ R W r × H r × C \hat{M}_{t-1}^0,\;\hat{M}_{t}^0\in R^{\frac{W}{r} \times \frac{H}{r} \times C} M^t−10,M^t0∈RrW×rH×C。如图1的a中左图所示, r r r表示下采样率。 [ W , H ] [W,H] [W,H]是图像的宽高, C C C是通道数。同时,第 t t t帧的图像特征图,我们在GNN的第 l l l层更新特征图,用 M ^ t l \hat{M}_{t}^l M^tl表示。
对于目标检测,我们遵循CenterNet的方式,检测每个目标并且找到其中心 ( x , y ) (x,y) (x,y)和宽高 ( w , h ) (w,h) (w,h)。我们对每帧图像有三个预测头——location,box size,refinement heads分别对应三个特征图 M ^ L l ∈ R W r × W r \hat{M}_L^l\in \R^{\frac{W}{r} \times \frac{W}{r}} M^Ll∈RrW×rW, M ^ S l ∈ R W r × W r × 2 \hat{M}_S^l\in \R^{\frac{W}{r} \times \frac{W}{r} \times 2} M^Sl∈RrW×rW×2, M ^ R l ∈ R W r × W r × 2 \hat{M}_R^l\in \R^{\frac{W}{r} \times \frac{W}{r} \times 2} M^Rl∈RrW×rW×2。需要注意的是,三个预测头在每一层GNN中都会预测结果
训练:设计GT
- 设计 M ^ L l \hat{M}_L^l M^Ll的GT,利用Gaussian heatmap——focal loss
M ^ L l ( i , j ) = ∑ k = 1 N e x p ( − ( i − ⌊ x k r ⌋ ) 2 − ( i − ⌊ y k r ⌋ ) 2 2 σ k 2 ) \hat{M}_L^l(i,j)=\sum_{k=1}^Nexp(-\cfrac{(i-\lfloor \frac{x_k}{r} \rfloor)^2 - (i-\lfloor \frac{y_k}{r} \rfloor)^2}{2\sigma_k^2}) M^Ll(i,j)=k=1∑Nexp(−2σk2(i−⌊rxk⌋)2−(i−⌊ryk⌋)2)
- 设计 M ^ S l \hat{M}_S^l M^Sl的GT,宽高作为GT——L1 loss
M ^ S l ( i , j , : ) = ( w , h ) \hat{M}_S^l(i,j,:)=(w,h) M^Sl(i,j,:)=(w,h)
- 设计 M ^ R l \hat{M}_R^l M^Rl的GT,待微调偏移量作为GT——L1 loss
M ^ R l ( i , j , : ) = ( x r − ⌊ x r ⌋ , y r − ⌊ y r ⌋ ) \hat{M}_R^l(i,j,:)=(\frac{x}{r} - \lfloor \frac{x}{r} \rfloor,\frac{y}{r} - \lfloor \frac{y}{r} \rfloor) M^Rl(i,j,:)=(rx−⌊rx⌋,ry−⌊ry⌋)
总的损失函数设计如下:
L d e t l = λ 1 L l o c l + λ 2 L s i z e l + λ 3 L r e f l L_{det}^l= \lambda_1L_{loc}^l + \lambda_2 L_{size}^l +\lambda_3 L_{ref}^l Ldetl=λ1Llocl+λ2Lsizel+λ3Lrefl
在代码中, λ 1 = λ 3 = 1 , λ 2 = 0.1 \lambda_1=\lambda_3=1,\quad \lambda_2=0.1 λ1=λ3=1,λ2=0.1
B. 数据关联
为了用于检测结果和轨迹的关联,我们额外加入了embedding head,对应了特征图 M ^ E l ∈ R W r × W r × D \hat{M}_E^l\in \R^{\frac{W}{r} \times \frac{W}{r} \times D} M^El∈RrW×rW×D。学习每个潜在检测目标的特征,即 M ^ t l \hat{M}_{t}^l M^tl中的每个像素。
训练:设计GT
- 设计 M ^ E l \hat{M}_E^l M^El的GT,对训练行人ID编码,就是JDE的做法,只在有真实目标的位置上才设计目标ID进行预测和反向传播——cross entropy loss
L e m b l = 1 N ∑ k = 1 N ∑ m = 1 M p k ( m ) l o g ( p ^ k ( m ) ) L_{emb}^{l}=\frac{1}{N} \sum_{k=1}^N \sum_{m=1}^M p^k(m)log(\hat{p}^k(m)) Lembl=N1k=1∑Nm=1∑Mpk(m)log(p^k(m))
其中M是训练时所有行人的ID总数,N是当前图片中的GT objects个数,即对每张图片,预测真实目标位置上那个人属于哪个ID,这是ReID在MOT中的 应用做法。
特征提取、目标检测、数据关联,其实还是在说JDE和FairMOT范式,以下才是文章的创新点
C. 基于图神经网络的关系建模
为了应用到图神经网络,我们需要建模图 G ( V , E ) G(V,E) G(V,E),V为节点,E为连接边,V是每个检测结果和轨迹的features向量。
- 对于tracklets,我们能很容易通过它的bbox获得其特征,我们利用ROIAlign从特征图 M ^ t − 1 0 \hat{M}_{t-1}^0 M^t−10裁剪出轨迹特征。
- 获取Detection的特征是有难度的。这是因为当 M ^ t l \hat{M}_{t}^l M^tl中没有检测到对象,无bbox就无法从 M ^ t l \hat{M}_{t}^l M^tl中裁剪特征的位置。为了克服这个问题,我们使用 M ^ t l \hat{M}_{t}^l M^tl的每个像素处的特征来表示潜在的检测,从而产生 W r × H r \frac{W}{r} \times \frac{H}{r} rW×rH个检测节点。采用这种方法的原因是我们相信 M ^ t l \hat{M}_{t}^l M^tl包含了足够的检测目标信息。
除了节点构造,我们还需要一组边E。一个简单的解决方案是在每对节点之间定义一条边,从而生成一个完全连通的图。然而,这样一个具有大量边的图在计算上可能很昂贵,当轨迹数量和潜在检测的数量(即 M ^ t l \hat{M}_{t}^l M^tl中的像素数量)太大时,有时不切实际。
因此我们分析了MOT中的一些问题:
- MOT只能在帧间关联,而不在帧内关联
- 每个目标在帧间的位移都是很小的
因此,针对(1),我们只在轨迹节点和检测节点间连接;针对(2),我们只连接和每个轨迹最近位置的潜在检测,这个位置为每个轨迹的bbox的中心画出的 s × s s\times s s×s的窗口,在代码中, s = 15 s=15 s=15。
聚合节点特征
我们的关键思想是利用GNN建模目标-目标间的关系,并且提升特征学习的能力,以用于目标检测和数据关联。
为此,我们通过聚合邻居节点的特征来迭代更新节点特征。通过这种方式,信息可以通过图形传播,节点可以进行交互。所以问题是我们应该如何准确地执行节点特性聚合?
文中采用了5种不同的聚合方式测试,最终发现GraphConv的聚合方式最好,其公式如下:
h l i = ρ 1 ( h l − 1 i ) + ∑ j ∈ N ( i ) ρ 2 ( h l − 1 j ) ) h_l^i=\rho_1(h_{l-1}^i)+\sum_{j\in N(i)}\rho_2(h_{l-1}^j)) hli=ρ1(hl−1i)+j∈N(i)∑ρ2(hl−1j))
N ( i ) N(i) N(i)为节点 i i i的邻居节点, ρ 1 \rho_1 ρ1和 ρ 2 \rho_2 ρ2为linear layers,即,对邻居节点的特征各使用同一个MLP,对当前节点使用MLP,之后sum邻居节点,和自身现行变换后的节点特征相加。注意,对于没有任何和轨迹相连的检测节点,上述公式的第二项消失,并且这些潜在的检测节点仅用于在帧t中发现新对象(在帧t-1中没有相应的轨迹)。
此外,有人可能会认为,由于我们的边缘仅在帧之间定义,因此对象-对象关系仅在时域中建模以进行数据关联,而不在时空域中建模以进行对象检测,即同一帧内的节点无法交互。如果我们只有一层GNN,这是真的。在我们使用多个层的情况下,信息可以来回传播,从而实现时空对象关系建模。例如,在第一层中,检测节点 i 1 i_1 i1的特征被聚合到小轨迹节点 j j j。然后在第二层中,小轨迹节点j的特征被传播到不同的检测节点i2,即,节点特征i1的一部分被传播到检测节点i2,这使得能够在同一帧中进行空间关系建模。在消融研究中,我们将探索GNN层的数量将如何影响我们模型的性能。在我们最好的模型中,我们使用了三层GNN。
注:利用节点的信息传播特点,每个节点融合了周围节点的特征,在多次迭代之后,每个节点都能建模当前帧目标间的关系。这是利用图自身的信息传播特点所做的简化,即不连接同帧的目标也能获得其特征关系。
D. 利用GNN联合Detection和Association
利用A和B的预测头,可以端到端训练模型。但如果它们只使用 M ^ t − 1 0 \hat{M}_{t-1}^0 M^t−10和 M ^ t 0 \hat{M}_{t}^0 M^t0中的特征,则不会利用对象关系。 为了利用GNN方法,我们还将检测(location boxsize refine)和关联(appearance)头应用于GNN第1层、第2层、第3层。通过relation编码进行节点特征聚合后,具有更好的特征。总而言之,我们网络的总体损失是GNN所有层的检测和数据关联损失的总和
文章把appearance head叫做数据关联头,我觉得是有问题的
L t o t a l = ∑ l η 1 L d e t l + η 2 L e m b l L_{total}=\sum_l \eta_1L_{det}^l+ \eta_2L_{emb}^l Ltotal=l∑η1Ldetl+η2Lembl
l l l为GNN的层数, η 1 \eta_1 η1和 η 2 \eta_2 η2为损失函数权重,即自动平衡损失方法(仍然是JDE的方法)
E. 推理和跟踪管理
测试
测试阶段,我们迭代地检测对象,并将它们与现有的tracklets关联。每帧 F t F_t Ft通过 M ^ L l \hat{M}_L^l M^Ll、 M ^ S l \hat{M}_S^l M^Sl、 M ^ R l \hat{M}_R^l M^Rl的NMS后处理获得检测结果。同时,我们从 M ^ E l \hat{M}_E^l M^El中获得每个像素点的ID embeddings。
剩下的和JDE一致
总结
这篇论文整体是用GNN对帧间目标建模,融合特征的过程。GNN在里面充当特征融合和建模的角色。整体还是JDE的范式,但加入了GNN。这也是与普通的GNN与MOT联合的方式不同,大部分的GNN加入是为了进行边预测,或者说GNN的特征融合和检测阶段是分离的。这篇文章给融合到了一起,端到端训练。