目录
前面我们所讲的爬虫都只有一个线程,因此称为单线程爬虫。单线程爬虫每次只访问一个页面,而每个页面的内容最多几百KB,相对于计算机的网络带宽来说小太多,多出来的带宽被浪费掉了。如果可以让爬虫同时访问10个页面,那计算机爬取的速度就提高了10倍。为此,我们就可以使用多线程技术来提升爬虫的效率。
一、进程与线程
1.进程与多进程
进程从字面可理解为正在进行中的程序。当我们打开Windows的任务管理器,我们可以看到当前你的计算机有哪些进程正在运行,每个进程占用的CPU资源比例是多少,占用的内存空间有多大。
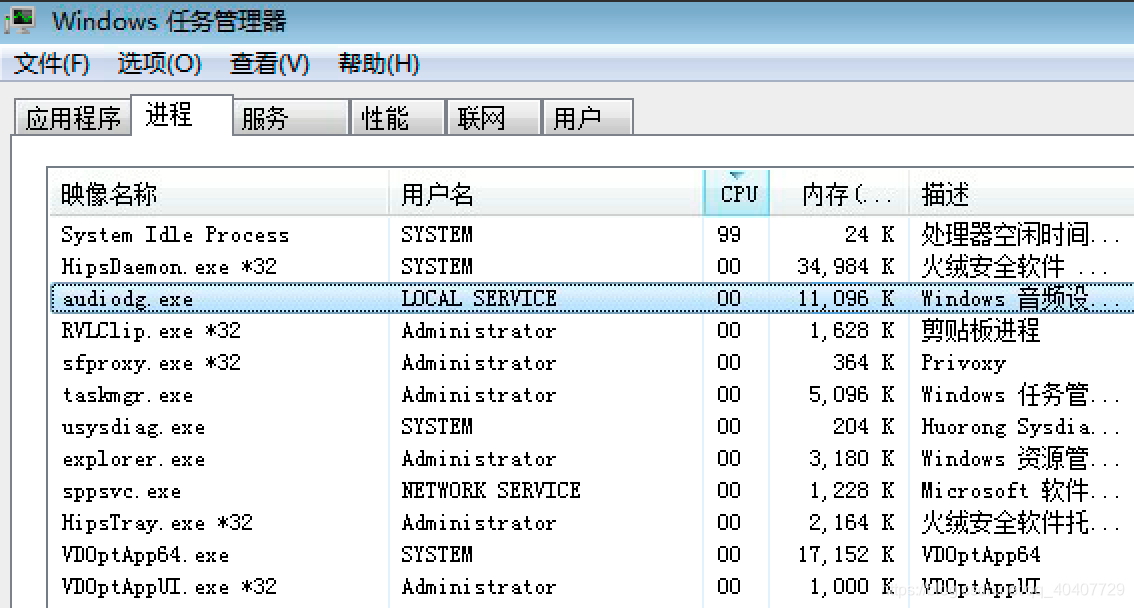
虽然我们看到进程管理器中有多个进程,但是他们并不是同时在使用cpu。cpu的使用是按照时间段来划分的,而如何分配是由操作系统的调度器来完成的,我们称进程是计算机系统对资源(包含cpu、内存、磁盘IO)分配和调度的基本单位。
单个cpu无法被多个进程同时并行使用,为了每个进程都有序运行,系统的调度器将cpu的使用分成多个时间段安排给各个进程,让各个进程轮流使用cpu完成各自任务,这就是所说的并发。
串行、并发和并行:
串行是将多个任务排成一行,一个一个的执行,前一个任务未结束后一个就无法进行。并发是多个任务在时间线上交替执行。并行是多个任务在时间线上同时执行。
举个现实的例子:串行就像在食堂中排队打饭,当只有一个窗口的时候,如果前一个人中途去取快递了,后面的人则永远只能等待。并发就像是排成两队或者多队打饭,如果其中一队排第一的人去买饮料了,其他队的照样可以打饭,到了一定间隔又回到这一队继续。到了并行的时候,增加了打饭的窗口数,所有队列可以同时打饭。
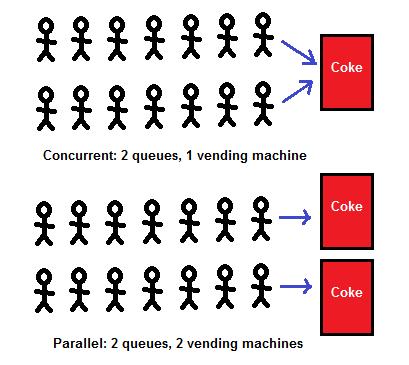
如果只有一个cpu,多个进程只能实现并发,也就是只有一个“打饭的窗口”,即使是多核cpu也是一样;如果有文章说一个cpu可以执行多个进程,这种说法也是没毛病的,因为它是以并发的方式执行多个进程,因为速度太快,具有了并行的假象。如果有多个cpu,多进程则可以实现并行。
2.线程与多线程
线程是cpu调度的最小单位,这里要和进程是操作系统分配资源的最小单元加以区别,cpu只能看到进程中的线程,而看不到其他进程。当一个进程获得cpu的使用权限后,cpu将为进程内的线程分配cpu使用时间、内存及磁盘IO(读取和写入操作)。如下图所示,微信这个进程组(进程组是一个或多个进程的集合,可能有一个主进程和多个子进程)内包含28个线程。
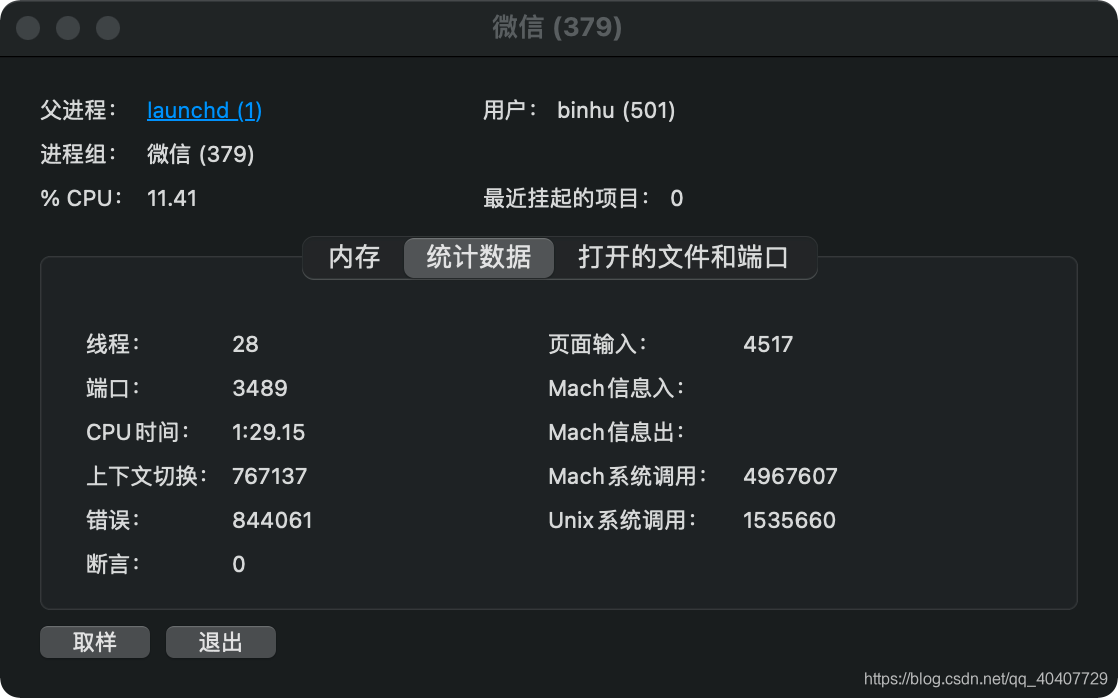
如果是单核cpu,进程中的多线程并发执行,cpu根据时间片切换线程;如果是多核cpu,多线程在cpu中并行执行,如果线程数小于cpu的内核数,则多余出来的内核将闲置。一个线程同一时刻只能在一个cpu中执行。
线程是进程完成具体任务的基本单位,一个进程中的多个线程共享进程中的全部资源,线程之间切换的开销较小,而进程间的切换有很大开销。
3.python中的多线程与多进程
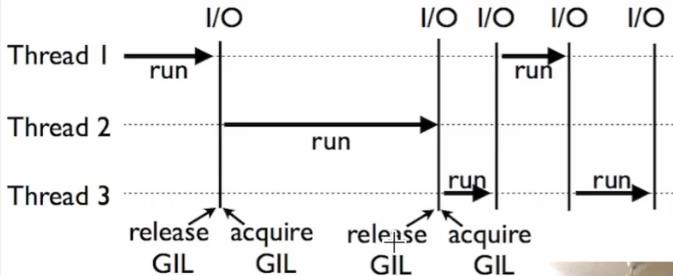
在python中,由于全局解释锁(GIL)的原因,一个时间段只允许一个线程来控制Python解释器。
这就意味着在任何一个时间点只有一个线程处于执行状态,即使是多核cpu。GIL对执行单线程任务没有影响,但是对计算密集型(CPU-bound)和多线程任务的影响显著,甚至多线程比单线程还要慢。
关于GIL的更多了解,推荐阅读下面这篇文章《Python的GIL是什么鬼,多线程性能究竟如何》。
二、多线程库Threading
导入threading库
import threading创建一个线程
class threading.Thread(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)使用threading.thread方法创建线程.
调用这个构造函数时,必需带有关键字参数。参数如下:
group 应该为 None;为了日后扩展 ThreadGroup 类实现而保留。
target 是用于 run() 方法调用的可调用对象。默认是 None,表示不需要调用任何方法。
name 是线程名称。默认情况下,由 "Thread-N" 格式构成一个唯一的名称,其中 N 是小的十进制数。
args 是用于调用目标函数的参数元组。默认是 ()。
kwargs 是用于调用目标函数的关键字参数字典。默认是 {}。
thread1 = threading.Thread(target = fun)以上代码创建了一个线程实例,并将它保存到thread1中。
使用start()方法开始一个线程。
thread1.start()使用join()方法控制一个线程执行结束后再执行下一个线程。
join的作用是等待直到线程终结。这会阻塞调用这个方法的线程,直到被调用 join() 的线程终结 -- 不管是正常终结还是抛出未处理异常 -- 或者直到发生超时,超时选项是可选的。
在下面的代码中,未使用join方法,线程执行顺序不确定,还未等到子线程结束,主线程就执行完毕,所以输出的执行时间也不包含子线程执行的时间。
def run():
print('开始执行子线程')
time.sleep(2)
print('子线程执行完毕')
start_time = time.time()
print('主线程开始')
thread1 = threading.Thread(target=run)
thread1.start()
print('主线程执行完毕')
print('花费时间%f'%(time.time()-start_time))
# 输出
主线程开始
开始执行子线程
主线程执行完毕
花费时间0.000776
子线程执行完毕增加了join()后,执行顺序正常。
import threading
import time
def run():
print('开始执行子线程')
time.sleep(2)
print('子线程执行完毕')
start_time = time.time()
print('主线程开始')
thread1 = threading.Thread(target=run)
thread1.start()
thread1.join()
print('主线程执行完毕')
print('花费时间%f'%(time.time()-start_time))
# 输出
主线程开始
开始执行子线程
子线程执行完毕
主线程执行完毕
花费时间2.002561实例一:单线程和多线程的简单对比
通过这个实例观察一下多线程的实际效果。蛋糕师傅制作一枚蛋糕需要2秒钟,我们的任务是需要制作两个蛋糕,看看采取不同的组织方式需要花费多少时间。
单线程模拟一位蛋糕师傅制作,多线程模拟两位蛋糕师傅制作。
import threading
import time
def run():
print('开始制作蛋糕')
time.sleep(2)
print('蛋糕制作完毕')
def single_thread():
start_time = time.time()
for i in range(2):
thread = threading.Thread(target = run)
thread.start()
thread.join()
end_time = time.time()
print('single_thread takes %f seconds'%(end_time - start_time))
def two_thread():
start_time = time.time()
thread1 = threading.Thread(target=run)
thread2 = threading.Thread(target=run)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
end_time = time.time()
print('two_thread takes %f seconds'%(end_time - start_time))
if __name__ == '__main__':
single_thread()
two_thread()
# 输出
开始制作蛋糕
蛋糕制作完毕
开始制作蛋糕
蛋糕制作完毕
single_thread takes 4.009257 seconds
开始制作蛋糕
开始制作蛋糕
蛋糕制作完毕
蛋糕制作完毕
two_thread takes 2.002863 seconds结果发现使用多线程完成的时间是单线程的1/2。
实例二:单线程与多线程执行计算密集型任务对比
在其他代码不变的情况下,将run函数的内容改称如下:
def run():
n = 0
print('开始计算')
for i in range(100000000):
n += pow(2*2,3*3)
print('计算完毕')
# 输出
开始计算
计算完毕
开始计算
计算完毕
single_thread takes 89.111831 seconds
开始计算
开始计算
计算完毕
计算完毕
two_thread takes 95.156550 seconds结果发现此例中多线程处理计算密集型任务的时间比单线程还要多,主要原因是受GIL的影响,等待的线程被无效唤醒而产生多出来的等待时间。
解决途径:使用多进程库。
三、多进程库multiprocessing
multiprocessing 是一个用与 threading 模块相似API的支持产生进程的包。 multiprocessing 包同时提供本地和远程并发,使用子进程代替线程,有效避免 Global Interpreter Lock 带来的影响。因此, multiprocessing 模块允许程序员充分利用机器上的多个核心。Unix 和 Windows 上都可以运行。
1.使用Process类创建进程
使用Process类创建进程的方法和threading.Thread基本相似
process1 = multiprocessing.Process(target=run)创建并运行一个进程
import multiprocessing
import time
def run():
print('%s进程开始'%(multiprocessing.current_process().name))
time.sleep(2)
print('%s进程结束'%(multiprocessing.current_process().name))
if __name__ == '__main__':
n_cpu = multiprocessing.cpu_count()
print('cpu有%d个核心'%n_cpu)
start_time = time.time()
process1 = multiprocessing.Process(target=run)
process1.start()
process1.join()
print('multiprocess takes %f seconds'%(time.time()-start_time))
# 输出
cpu有4个核心
Process-1进程开始
Process-1进程结束
multiprocess takes 2.201348 seconds这里我们看到实际花费的时间超过了2.2,多出来的时间是进程调度的时间。
cpu_count用以获取电脑的核心数,作者电脑有2个核心,由于超线程的原因,Python可利用的核心数是真实数量的2倍。

current_process用来返回进程这个对象,current_process().name用来返回当前进程的名称。
与threading一样,start()用以启动进程,join()用以结束进程。
实例三:多进程的简单使用
import multiprocessing
import time
def run():
print('%s进程开始'%(multiprocessing.current_process().name))
result = 0
for num in range(100000):
result += pow(99,99)
print('%s进程结束'%(multiprocessing.current_process().name))
if __name__ == '__main__':
n_cpu = multiprocessing.cpu_count()
process_list = []
for n in range(n_cpu):
start_time = time.time()
process = multiprocessing.Process(target=run)
process.start()
process_list.append(process)
for process in process_list:
process.join()
print('multiprocess takes %f seconds'%(time.time()-start_time))
# 输出
Process-1进程开始
Process-2进程开始
Process-3进程开始
Process-4进程开始
Process-1进程结束
Process-2进程结束
Process-4进程结束
Process-3进程结束
multiprocess takes 0.495185 seconds
这里有一个细节我们需要注意,在监视器中,一共出现了5个名称为Python的进程,这就是我们使用multiprocessing创建并运行的进程。他们cpu占用的百分比之和小于400%,原因是有4个核心。
import multiprocessing
import threading
import time
def run():
n = 0
print('开始计算')
for i in range(100000000):
n += pow(2*2,3*3)
print('计算完毕')
def single_thread():
start_time = time.time()
for i in range(2):
thread = threading.Thread(target = run)
thread.start()
thread.join()
end_time = time.time()
print('single_thread takes %f seconds'%(end_time - start_time))
def two_thread():
start_time = time.time()
thread1 = threading.Thread(target=run)
thread2 = threading.Thread(target=run)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
end_time = time.time()
print('two_thread takes %f seconds'%(end_time - start_time))
def two_process():
start_time = time.time()
process1 = multiprocessing.Process(target=run)
process2 = multiprocessing.Process(target=run)
process1.start()
process2.start()
process1.join()
process2.join()
end_time = time.time()
print('two_process takes %f seconds'%(end_time - start_time))
if __name__ == '__main__':
single_thread()
two_thread()
two_process()
# 输出
开始计算
计算完毕
开始计算
计算完毕
single_thread takes 97.737577 seconds
开始计算
开始计算
计算完毕
计算完毕
two_thread takes 116.953237 seconds
开始计算
开始计算
计算完毕
计算完毕
two_process takes 88.401921 seconds实例二中的问题,改用多进程后使用了最短的时间完成计算任务。
2.使用Pool类实现多进程
multiprocessing提供了一个Pool类来代表进程池对象。Pool可以提供指定数量的进程供用户调用,默认大小是CPU的核数。当有新的请求提交到Pool时,如果池还没有满,那么会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到规定最大值,那么该请求就会等待,指导池中有进程结束,才会创建新的进程来处理她。
import multiprocessing
import os
import time
def run(m):
print('task%d 进程开始'%m)
print(os.getpid(),multiprocessing.current_process().name)
time.sleep(2)
print('task%d 进程结束'%m)
if __name__ == '__main__':
pool = multiprocessing.Pool(processes=2)
for i in range(4):
pool.apply_async(run,args=(i,))
pool.close()
pool.join()
# 输出
task0 进程开始
60832 SpawnPoolWorker-1
task1 进程开始
60833 SpawnPoolWorker-2
task0 进程结束task1 进程结束
task2 进程开始
60833 SpawnPoolWorker-2
task3 进程开始
60832 SpawnPoolWorker-1
task2 进程结束
task3 进程结束上面程序中先创建了容量为2的进程池,依次向进程池中添加了4个任务。从运行结果可以看到虽然添加了4个任务,但是一开始只运行了2个,但一个任务结束后,新的任务依次添加进来,任务执行使用的进程依然是原来的进程,这一点通过进程的pid就可以可以看出来。
3.使用dummy.Pool类实现多线程
multiprocessing下面有一个dummy模块,它的下面有一个Pool类,用它可以批量生成线程池,它可以让python的线程使用multiprocessing的各种方法。
from multiprocessing import dummy
import threading
import time
def run(m):
print('task%d (id=%d)%s is running......'%(m,threading.current_thread().ident,dummy.current_process().name))
time.sleep(2)
print('task%d (id=%d)%s is ending......'%(m,threading.current_thread().ident,dummy.current_process().name))
if __name__ == '__main__':
pool = dummy.Pool(2)
for i in range(4):
pool.apply_async(run,args=(i,))
pool.close()
pool.join()
# 输出
task0 (id=123145509961728)Thread-1 is running......
task1 (id=123145526751232)Thread-2 is running......
task0 (id=123145509961728)Thread-1 is ending......
task1 (id=123145526751232)Thread-2 is ending......
task2 (id=123145526751232)Thread-2 is running......
task3 (id=123145509961728)Thread-1 is running......
task2 (id=123145526751232)Thread-2 is ending......
task3 (id=123145509961728)Thread-1 is ending......四、开发多线程爬虫
实例四:单线程与多线程访问百度首页
import multiprocessing
from multiprocessing import dummy
import time
import threading
import requests
def spider_baidu(url):
response = requests.get(url).status_code
print('百度请求成功,状态码%s'%response)
def single_thread(url):
print('单线程开始')
start_time = time.time()
for i in range(10):
spider_baidu(url)
print('单线程结束')
print('单线程花费的时间是%.2f秒'%(time.time()-start_time))
def multi_thread(url):
print('%s多线程开始'%threading.current_thread().name)
start_time = time.time()
lst = []
for i in range(10):
lst.append(url)
pool = dummy.Pool(4)
pool.map(spider_baidu,lst)
pool.close()
pool.join()
print('%s多线程结束'%threading.current_thread().name)
print('多线程花费的时间是%.2f秒'%(time.time()-start_time))
def multi_process(url):
print('%s多进程开始'%multiprocessing.current_process().name)
start_time = time.time()
lst = []
for i in range(10):
lst.append(url)
pool = multiprocessing.Pool(4)
pool.map(spider_baidu,lst)
pool.close()
pool.join()
print('%s多进程结束'%multiprocessing.current_process().name)
print('多进程花费的时间是%.2f秒'%(time.time()-start_time))
if __name__ == '__main__':
url = 'https://www.baidu.com/'
single_thread(url)
multi_thread(url)
multi_process(url)
# 输出
单线程开始
百度请求成功,状态码200
百度请求成功,状态码200
百度请求成功,状态码200
百度请求成功,状态码200
百度请求成功,状态码200
百度请求成功,状态码200
百度请求成功,状态码200
百度请求成功,状态码200
百度请求成功,状态码200
百度请求成功,状态码200
单线程结束
单线程花费的时间是1.43秒
MainThread多线程开始
百度请求成功,状态码200
百度请求成功,状态码200
百度请求成功,状态码200
百度请求成功,状态码200
百度请求成功,状态码200
百度请求成功,状态码200
百度请求成功,状态码200
百度请求成功,状态码200
百度请求成功,状态码200
百度请求成功,状态码200
MainThread多线程结束
多线程花费的时间是0.46秒
MainProcess多进程开始
百度请求成功,状态码200
百度请求成功,状态码200
百度请求成功,状态码200
百度请求成功,状态码200
百度请求成功,状态码200
百度请求成功,状态码200
百度请求成功,状态码200
百度请求成功,状态码200
百度请求成功,状态码200
百度请求成功,状态码200
MainProcess多进程结束
多进程花费的时间是0.92秒从结果来看,多线程花费的时间最少,其次是多进程,最后是单线程。对于IO密集型的任务多线程的表现最好,这也就是爬虫为什么适合使用多线程开发的原因。
五、练习
在努努书坊(https://www.kanunu8.com/)中找到一篇自己喜欢的小说,例如金庸系列、四大名著等,使用多线程、requests库和正则表达式,将小说按章节全文爬取下来。作业需要提交的文件包含:章节网址链接(csv),小说正文的文件/文件夹目录索引(txt)
说明:
1.每个章节的名称及网址链接:格式为csv,headers包含章节名称、网址两个字段。
2.将爬取下来的正文存到.txt中,文件以章节名称命名;如果章节按‘部’或‘篇’分类,应将章节存放到以‘部’‘篇’命名的相应子文件夹下。爬取下来的正文文件不需要提交,只需要将文件下所有文件、文件夹的索引存放到txt中提交即可,所以可能需要用到os的相关操作方法和递归算法,不清楚的请百度。
3.文明爬虫,每篇正文在爬取时需设置sleep时间为1.5秒。