目录
通过对文件的操作,可以读取文件中的数据、文本,也可以将利用程序处理好的结果数据存放到文件中保存起来。
一、文件的打开与读写
1.打开文件
要想读取文件中的内容,首先要打开文件。在python中我们使用"open"这个关键字,它的作用是打开一个文件,并创建一个文件对象。
使用python打开文件,有两种写法,第一种方式是:
file = open('文件路径','文件操作方法',encoding='utf-8') # 打开文件
对文件进行操作的代码块 # 操作文件
file.close() # 关闭文件第二种方式:使用python的上下文管理器
with open('文件路径','文件操作方法',encoding='utf-8') as file: # 打开文件
对文件进行操作的代码块 # 操作文件两种方式相比较,第一种方式需要配合使用close()方法手动关闭文件,但在程序开发中经常会出现忘记关闭文件的情况,第二种方式利用上下文管理器,在退出时都会自动关闭文件。
后面我们将利用上下文管理器来介绍文件操作。
2.文件路径
我们来看一个读取文件的实例。首先,我们准备一个文档,文档中包含一些文本信息。
This is a test file.
This is the first row.
This is the second row.
This is the third row.你可以在编辑器中录入这些文本,然后将他们保存为“test.txt”文件,这个文件我保存在learnpython文件夹下。
另外创建一个名为readfile的python文件,实现对文件的读取,注意目前readfile在learnpython文件夹的外面。

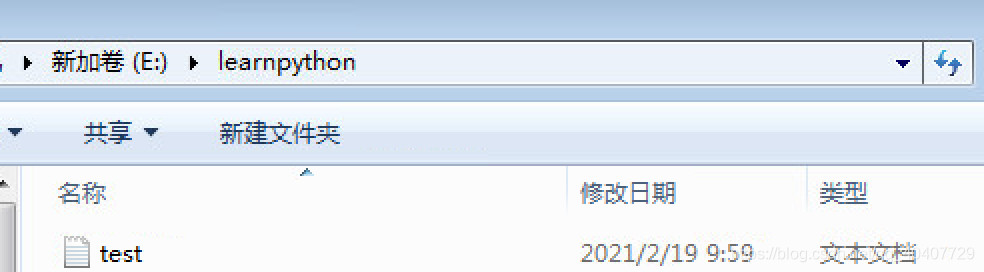
这个部分的重点是书写正确的文件路径。
文件路径用以指明打开文件的位置及文件名,可以是绝对路径,也可以是相对路径。
绝对路径是标识文件位于磁盘中的完整地址信息。
mac OS系统中的绝对路径
with open('/users/binhu/pycharmprojects/learnpython/test.txt','r',encoding = 'utf-8') as file:
content = file.read()
print(content)windows系统中的绝对路径
with open('e:/learnpython/test.txt','r',encoding = 'utf-8') as file:
content = file.read()
print(content)
# 或者使用转义字符r
with open(r'e:\learnpython\test.txt','r',encoding = 'utf-8') as file:
content = file.read()
print(content)相对路径是文本文件相对于现在的工作区而言的路径,并不总是相对于当前正在运行的这个Python文件的路径。
在使用相对路径时,在文件路径中只要写清楚从当前位置向下直到文件名的路径信息。
mac OS系统中的相对路径
with open('learnpython/test.txt','r',encoding = 'utf-8') as file:
content = file.read()
print(content)
windows系统中的相对路径
with open(r'learnpython\test.txt','r',encoding = 'utf-8') as file:
content = file.read()
print(content)还有另外一种简化处理方式,当我们将python文件和需要操作的文件放在一起的时候(也就是相同的路径下),我们可以不用再关心除了文件名称以外的其他路径信息,如下图所示。

在文件路径部分只需要注明文件名称即可。
with open('test.txt',encoding='utf-8') as file:# 打开文件
lines = file.read()
print(lines)
# 输出
This is a test file.
This is the first row.
This is the second row.
This is the third row.3.文件操作方法
文件操作方法是可以缺省的,默认是以只读方式打开文件,如果要想对文件进行其他的操作,则需要指明相应的访问模式。
| 访问模式 | 说明 |
| r | 默认模式。以只读方式打开文件,文件的指针会放在文件的开头。 |
| w | 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。如果是读取文件,会从首个字符开始读取数据,如果是以该模式打开文件,就写数据,则会从首个字符开始写,并一个一个字符的向后面覆盖。如果想从末尾添加内容,则可先read()然后在向其中添加数据。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。如果想读取的内容的话,只能在写内容的时候,同时读取其中的内容,相当于只能读取出你刚刚写入的内容。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。在读文件的时候,会发现读出来的数据为空,是因为a+模式是在文件末尾添加内容,所以其指针已经指到了文件末尾,所以读出来的数据就是空的。 |
| 备注:1.rb,wb,ab,rb+,wb+,ab+分别是以二进制格式对文件进行操作。 2.在open函数中注写文件操作方法时,需要用单引号将访问模式作为字符串括起来。 |
|
4.encoding参数
使用Python打开文件时,文件数据按照文件本身的编码方式转换为字节码,如果这时需要将编码转换,那么我们可以使用encoding参数来指定转换为的编码格式,如果文件不存在则该参数指定新建文件的编码格式。
UTF-8是多种编码方式中的一种,除此以外还有GBK、GB2312等。
该参数只支持在python3中使用。
5.写文件
当向文件中写入数据时,需要用到write方法。在操作某个文件时,每调用一次write方法,写入的数据就会追加到文件末尾。
下面的例子中,列表包含了四个字符串,新建一个名为‘test2.txt’的文档,通过循环逐句写入到文档中,最后将文档中的内容输出出来。注意write在写的过程中不会自动换行,需要添加换行符'\n'强制换行。
lines = ['You were the shadow to my life','Did you feel us','Another start','You fade away','Afraid our aim is out of sight']
with open('test2.txt','w+') as file:
for line in lines:
file.write(line + '\n')
file.seek(0)
print(file.read())
# 输出
You were the shadow to my life
Did you feel us
Another start
You fade away
Afraid our aim is out of sightwrite方法需要传入字符串,writelines方法则可以传入字符串或字符串序列。上面的例子使用writelines可修改为:
lines = ['You were the shadow to my life\n','Did you feel us\n','Another start\n','You fade away\n','Afraid our aim is out of sight']
with open('test2.txt','w+') as file:
file.writelines(lines)
file.seek(0)
print(file.read())
# 输出
You were the shadow to my life
Did you feel us
Another start
You fade away
Afraid our aim is out of sight6.读文件内容
(1)read方法
read方法可以从文件中读取数据,该方法的格式如下:
content = read(size)size表示要从文件中读取的数据的长度,单位为字节。如果没有指定size,那么就表示读取文件的全部数据。
with open('test2.txt','r',encoding='utf-8') as file:
print(file.read(10))
print(file.read())
# 输出
You were t
he shadow to my life
Did you feel us
Another start
You fade away
Afraid our aim is out of sight
# test2.txt中的原文
You were the shadow to my life
Did you feel us
Another start
You fade away
Afraid our aim is out of sight
从输出我们可以发现,第一次输出了前10个字符的内容,第二次从第一次输出结束的地方开始输出后面的所有内容。
这里我们可以了解到,在读文件的时候是按照一定的顺序进行的(写文件也是如此),如果要在读或写时对位置(也叫指针)进行控制,可以用到file自带的seek方法。
在上面的例子中,如果希望第二次从头开始输出,我们可以进行如下修改。
with open('test2.txt','r',encoding='utf-8') as file:
print(file.read(10))
file.seek(0) # 当seek的值为0时,表示指针回到开始位置
print(file.read())
# 输出
You were t
You were the shadow to my life
Did you feel us
Another start
You fade away
Afraid our aim is out of sight如果希望输出最末尾的10个字符,我们修改为:
with open('test2.txt','rb+') as file:
print(file.read(10).decode('utf-8'))
file.seek(-10,2)
print(file.read().decode('utf-8'))
# 输出
You were t
t of sight另外,注意这里将读取模式改为了‘rb+’,是因为如果要从末尾计算读取位置,必须使用二进制模式,不然会出现‘python can't do nonzero end-relative seeks’的错误提示。decode('utf-8')是将字节码解码为字符串。
seek函数的语法格式我们稍加了解。
seek(offset[,whence])
(1)offset:表示偏移量,也就是需要移动的字节数。
(2)whence:表示方向,该参数的值有三个:
0,whence参数的默认值,表示从文件的起始位置开始偏移。
1,表示从文件当前的位置开始偏移。
2,表示从文件末尾开始偏移。(2)readlines方法读取文件
该函数的作用是读取所有行,并以列表的形式返回结果,代码如下:
f.readlines()实例:使用readlines方法读取test.txt文档中的内容,输出返回的列表,并添加行号后逐行输出文件中的内容。
with open('test2.txt','r') as file:
lines = file.readlines()
print(lines)
for i in range(len(lines)):
print('%d:%s'%(i+1,lines[i]))
# 输出
['You were the shadow to my life\n', 'Did you feel us\n', 'Another start\n', 'You fade away\n', 'Afraid our aim is out of sight']
1:You were the shadow to my life
2:Did you feel us
3:Another start
4:You fade away
5:Afraid our aim is out of sight(3)readline方法读取文件
使用readline方法可以一行一行地读取文件中的数据。
with open('test2.txt','r') as file:
row_one = file.readline()
print(row_one)
row_two = file.readline()
print(row_two)
# 输出
You were the shadow to my life
Did you feel us二、文件和文件夹的其他操作
Python的os模块提供了非常丰富的方法来处理文件和目录。
1.获取当前目录
使用os.getcwd方法获取当前所在的路径。
import os
os.getcwd()
# 输出
'/Users/binhu/PycharmProjects/learnpython'2.改变当前目录
os.chdir('需要切换的新路径')方法用于改变当前工作目录到指定的路径。例如,将当前目录改变为上一级目录的代码如下:
os.chdir('../')
os.getcwd() # 将改变后的目录输出
# 输出
'/Users/binhu/PycharmProjects'3.创建文件夹
os.mkdir('新的文件夹名称')方法用于创建一个新的文件夹。例如创建一个名为‘newpath'的文件夹,然后切换到这个文件夹下,并输出目录。
os.mkdir('newpath')
os.chdir('newpath')
os.getcwd()
# 输出
'/Users/binhu/PycharmProjects/newpath'4.删除文件
os.remove('要删除的文件路径及文件名')。将之前新建的'test.txt'文件删除。
os.remove('learnpython/test2.txt')5.删除文件夹
os.rmdir('要删除的文件路径及文件夹名称')用以删除指定的空目录,如果目录非空,则抛出一个OSError异常。将之前新建的'newpath'文件夹删除。
os.rmdir('newpath')6.文件重命名
os.rename(src,dst)函数可以重命名文件或目录,从src到dst。将‘test.txt’改为‘测试文档.txt’
os.rename('test.txt','测试文档.txt')7.获取文件和文件夹的列表
os.listdir(path)返回path指定的文件夹包含的文件或文件夹的名字的列表。如果不指定path,则获取当前文件夹下的文件和文件夹列表。
os.listdir()8.os.path模块
os.path 模块主要用于获取文件的属性及实现对文件路径的操作,可以实现的操作特别多,主要如下[1]:
| 方法 | 说明 |
|---|---|
| os.path.abspath(path) | 返回绝对路径 |
| os.path.basename(path) | 返回文件名 |
| os.path.commonprefix(list) | 返回list(多个路径)中,所有path共有的最长的路径 |
| os.path.dirname(path) | 返回文件路径 |
| os.path.exists(path) | 如果路径 path 存在,返回 True;如果路径 path 不存在,返回 False。 |
| os.path.lexists | 路径存在则返回True,路径损坏也返回True |
| os.path.expanduser(path) | 把path中包含的"~"和"~user"转换成用户目录 |
| os.path.expandvars(path) | 根据环境变量的值替换path中包含的"$name"和"${name}" |
| os.path.getatime(path) | 返回最近访问时间(浮点型秒数) |
| os.path.getmtime(path) | 返回最近文件修改时间 |
| os.path.getctime(path) | 返回文件 path 创建时间 |
| os.path.getsize(path) | 返回文件大小,如果文件不存在就返回错误 |
| os.path.isabs(path) | 判断是否为绝对路径 |
| os.path.isfile(path) | 判断路径是否为文件 |
| os.path.isdir(path) | 判断路径是否为目录 |
| os.path.islink(path) | 判断路径是否为链接 |
| os.path.ismount(path) | 判断路径是否为挂载点 |
| os.path.join(path1[, path2[, ...]]) | 把目录和文件名合成一个路径 |
| os.path.normcase(path) | 转换path的大小写和斜杠 |
| os.path.normpath(path) | 规范path字符串形式 |
| os.path.realpath(path) | 返回path的真实路径 |
| os.path.relpath(path[, start]) | 从start开始计算相对路径 |
| os.path.samefile(path1, path2) | 判断目录或文件是否相同 |
| os.path.sameopenfile(fp1, fp2) | 判断fp1和fp2是否指向同一文件 |
| os.path.samestat(stat1, stat2) | 判断stat tuple stat1和stat2是否指向同一个文件 |
| os.path.split(path) | 把路径分割成 dirname 和 basename,返回一个元组 |
| os.path.splitdrive(path) | 一般用在 windows 下,返回驱动器名和路径组成的元组 |
| os.path.splitext(path) | 分割路径,返回路径名和文件扩展名的元组 |
| os.path.splitunc(path) | 把路径分割为加载点与文件 |
[1]Python os.path() 模块.https://www.runoob.com/python/os-chdir.html.
三、读写csv文件
CSV是comma-separated values的简写,从字面理解就是用逗号分割的值,每行代表一条数据。我们用文本编辑器打开CSV文件(如图3),可以清晰看到这种数据的存储形式,但是这并不方便对数据的查看。
CSV文件同时还可以用excel或者Numbers打开,主要用于对数据的管理。
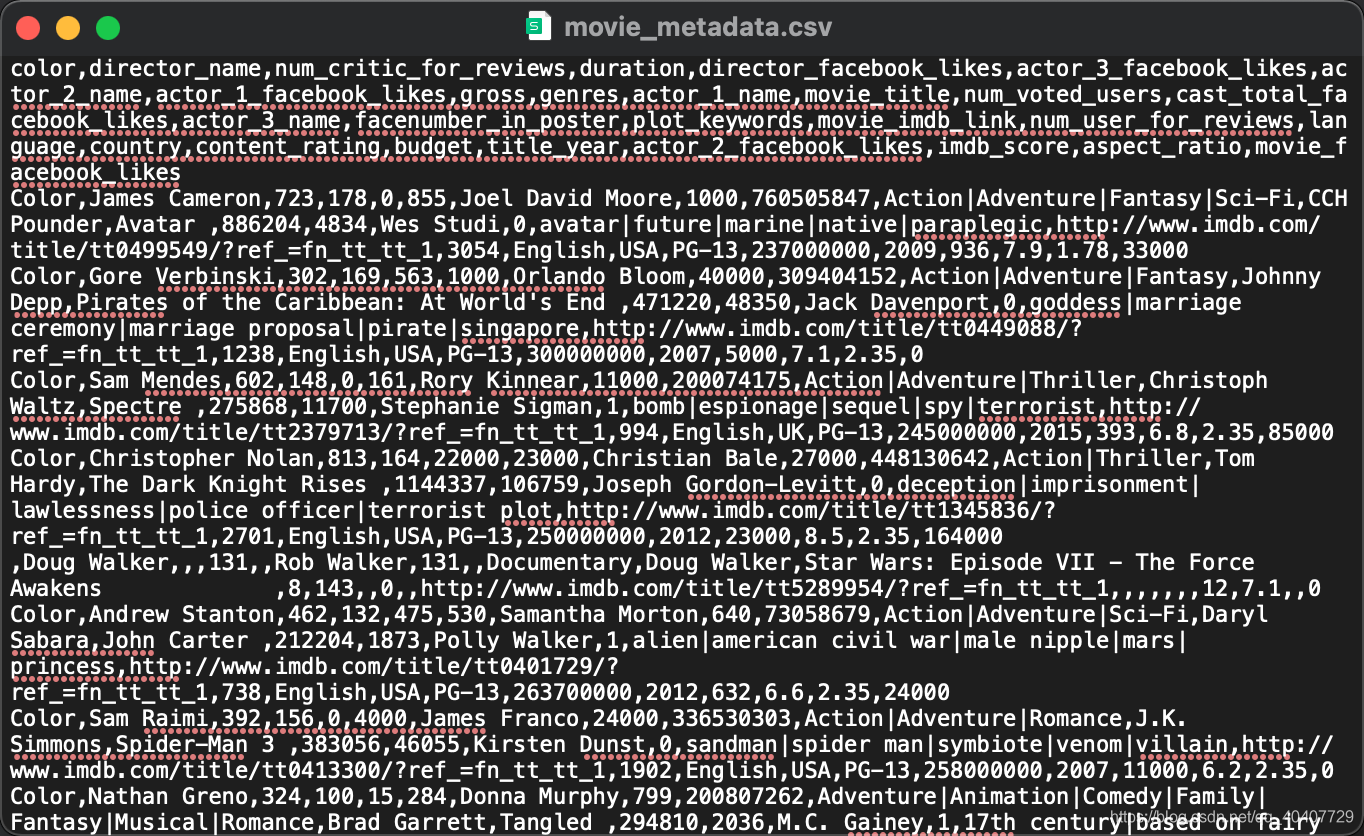
Python自带操作CSV的模块。使用这个模块,可以将CSV文件的内容转换为Python的字典,从而方便使用。
1.读CSV文件
CSV文件本质上是文本文件,所以需要先以文本文件的方式打开,再将文本对象传递给CSV模块。
import csv
with open('movie_metadata.csv') as file: # 打开并生成文本对象
reader = csv.DictReader(file) # 将文本对象作为DictReader的参数,生成一个可迭代的对象
for row in reader: # 循环访问每一行数据,row的类型是字典
print(row)DictReader会将第一行的内容(类标题)作为key值,第二行开始才是数据内容。
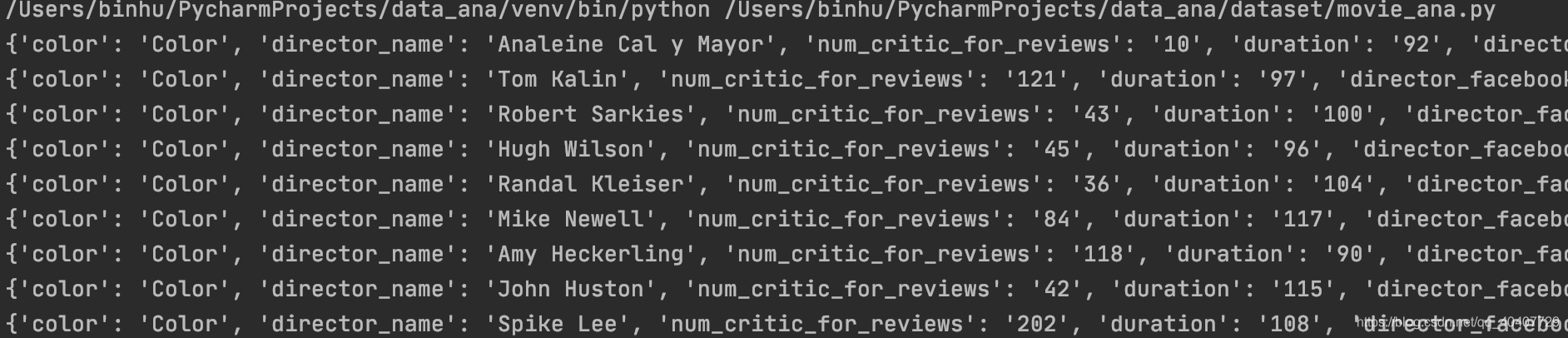
可以直接像普通字典那样操作每个row。
import csv
with open('movie_metadata.csv') as file:
reader = csv.DictReader(file)
for row in reader:
color = row['color']
director_name = row['director_name']
print(color,director_name)
# 输出
Color James Cameron
Color Gore Verbinski
Color Sam Mendes
Color Christopher Nolan
Doug Walker
Color Andrew Stanton
Color Sam Raimi
Color Nathan Greno
……2.写CSV文件
Python写CSV文件需要用到csv.DictWriter()这个类,然后基于这个类生成一个DictWriter实例。它接收两个参数:第1个参数是文件对象file;第2个参数名为fieldnames,值为字典的Key列表。
import csv
with open('new_csv.csv','w',encoding='utf-8') as file: # 利用open新建一个名为‘new_csv.csv’的文件,访问方式为‘w’,文本编码方式为‘utf-8’,生成一个file对象
writer = csv.DictWriter(file,fieldnames=['name','old','sex']) # 生成一个DictWriter实例,将file作为参数,表头为'name','old','sex'接下来使用writer.writerheader()写入表头,使用writerows将包含字典的列表写入csv。以下为完整代码:
import csv
data = [{'name':'Jone','old':18,'sex':'male'},
{'name':'Tom','old':20,'sex':'male'},
{'name':'Susan','old':17,'sex':'female'}]
with open('new_csv.csv','w',encoding='utf-8') as file:
writer = csv.DictWriter(file,fieldnames=['name','old','sex'])
writer.writeheader()
writer.writerows(data)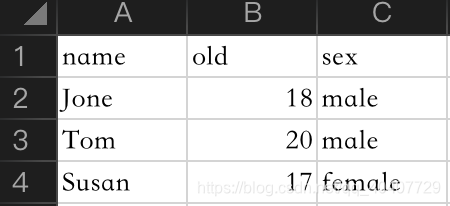
注意写入的字典的key必须与fieldnames相同。除了使用writerows批量写入多个字典,也可以使用writerow写入单个字典。