基础练习:
这节课的主要内容,就是调用函数来操作文件,函数和文件的结合使用;
理解起来可能有点麻烦,看不懂就自己写一遍!
#导入argv模块
from sys import argv
#解包
script, input_file = argv
#定义一个函数:读取并打印传参文件
def print_all(f):
print(f.read())
#定义一个函数:跳转到传参文件的0字节,也就是第1个字节
def rewind(f):
f.seek(0)
#定义一个函数:打印传参的行数及该行的内容
def print_a_line(line_count, f):
print(line_count, f.readline())
#打开文件对象,并把文件对象赋值给变量
current_file = open(input_file)
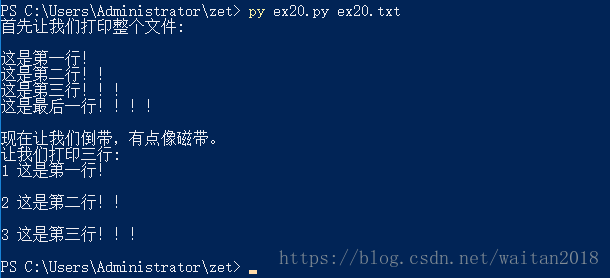
print("首先让我们打印整个文件:\n")
#调用函数:读取并打印
print_all(current_file)
print("现在让我们倒带,有点像磁带。")
#调用函数:跳转到文件的首字节
rewind(current_file)
print("让我们打印三行:")
#给1取个变量名
current_line = 1
#调用函数:打印行数,和文件的一行内容;第一个传参是变量current_line,第二个传参是变量current_file)
print_a_line(current_line, current_file)
#同34#和37#
current_line = current_line + 1
print_a_line(current_line, current_file)
#同34#和37#
current_line = current_line + 1
print_a_line(current_line, current_file)结果:
有几个小问题:
1. seek(0)为什么不把current_line设置成0?
因为seek(0)是跳转到文件的0字节,也就是第1个字节,也就是说在首行,所以current_line设置成1;
2.readline是怎么知道每一行在哪里的?
readline()会扫描文件的每一个字节,直到找到第一个\n(也就是换行符)时为止,然后它会返回此次发现的所有内容,包括\n本身;文件也会记录每次readline()读取的位置,下次readline()再读取时就会从之前记录的位置开始读取,而不是从头开始;
3.为什么结果里会有间隔符(空行)?
因为readline()返回的结果本身就带有\n,而print()在打印时又会添加一个\n,所以就会多出一行;解决办法就是在print()函数的末尾多加一个参数end = "",这样print()就不会自己添加\n了;
折腾一下:
+=是什么? +=是一个简写,x += y的意思就是x = x + y;
然后我们用这个简写用在习题的代码中:
from sys import argv
script, input_file = argv
def print_all(f):
print(f.read())
def rewind(f):
f.seek(0)
def print_a_line(line_count, f):
print(line_count, f.readline())
current_file = open(input_file)
print("首先让我们打印整个文件:\n")
print_all(current_file)
print("现在让我们倒带,有点像磁带。")
rewind(current_file)
print("让我们打印三行:")
current_line = 1
print_a_line(current_line, current_file)
current_line += 1
print_a_line(current_line, current_file)
current_line += 1
print_a_line(current_line, current_file)注意第30和33行代码,使用的+=简写,和之前不一样了,但是结果是一样的!!!
