文章目录
环检测及拓扑排序算法
这两个算法既可以用 DFS 思路解决,也可以用 BFS 思路解决,相对而言 BFS 解法从代码实现上看更简洁一些,但 DFS 解法有助于你进一步理解递归遍历数据结构的奥义。
一、环检测算法(DFS版本)
207. 课程表
其实该题目的理解不难,当修不完所有课程时就说明存在循环依赖(即判断一幅有向图中是否存在环)
其实其实这种场景在现实生活中也十分常见,比如我们写代码 import 包也是一个例子,必须合理设计代码目录结构,否则会出现循环依赖,编译器会报错,所以编译器实际上也使用了类似算法来判断你的代码是否能够成功编译。
看到依赖问题,首先想到的就是把问题转化成「有向图」这种数据结构,只要图中存在环,那就说明存在循环依赖。
即若必须修完课程1才能去修课程3,那么就有一条有向边从结点1指向结点3
如果发现这幅有向图中存在环,那就说明课程之间存在循环依赖,肯定没办法全部上完;反之,如果没有环,那么肯定能上完全部课程。
那现在如何基于题目给的数据转换成图呢?
我们知道图的两种常用存储形式:邻接矩阵和邻接表
这里选择使用邻接表:
List<Integer>[] graph;
//graph[s] 是一个列表,存储着节点 s 所指向的节点。
prerequisites数组记录的是每两个点之间的关系,其实就是谁指向谁
boolean hasCycle 记录图中是否有环
boolean[] visited 防止重复遍历同一个结点
boolean[] onPath 记录了当前traverse经过的路径(即记录一次递归堆栈中的节点)
关于如何利用onPath来判断是否存在环?
在进入节点
s的时候将onPath[s]标记为 true,离开时标记回 false,(这里有点回溯算法的意思)如果发现onPath[s]已经被标记,说明出现了环。
如何理解visited和onPath?
类比贪吃蛇游戏,
visited记录蛇经过过的格子,而onPath仅仅记录蛇身。onPath用于判断是否成环,类比当贪吃蛇自己咬到自己(成环)的场景。
完整的代码如下:
public boolean canFinish(int numCourses, int[][] prerequisites) {
List<Integer>[] graph=buildGraph(numCourses,prerequisites);
visited=new boolean[numCourses];
onPath=new boolean[numCourses];
//注意图中并不是所有节点都相连,所以要用一个 for 循环将所有节点都作为起点调用一次 DFS 搜索算法。
for(int i=0;i<numCourses;i++){
traverse(graph,i);
}
return !hashCycle;
}
//建图函数
public List<Integer>[] buildGraph(int numCourses,int[][] prerequisites){
//邻接表
List<Integer>[] graph=new LinkedList[numCourses];
for(int i=0;i<numCourses;i++){
graph[i]=new LinkedList<>();
}
//通过遍历题目所给的数据来建立图
for(int[] edge:prerequisites){
//这里是遍历每一个prerequisites[],里面存储的就是prerequisites[][1]指向prerequisites[][0]
int from=edge[1];
int to=edge[0];
graph[from].add(to);
}
return graph;
}
//遍历函数,遍历的时候记录是否有环
boolean[] visited;
boolean[] onPath;
boolean hashCycle=false;
public void traverse(List<Integer>[] graph,int s){
//如果一次遍历完之后该节点还是为true,说明存在环
if(onPath[s]){
hashCycle=true;
}
if(visited[s]||hashCycle){
return;
}
//将结点s添加到路径上
onPath[s]=true;
//标记为已经过
visited[s]=true;
//递归遍历这个结点的相邻结点
for(int each:graph[s]){
traverse(graph,each);
}
//将结点s移除路径
onPath[s]=false;
}
二、拓扑排序算法(DFS 版本)
210. 课程表 II
这道题就是上道题的进阶版,不是仅仅让你判断是否可以完成所有课程,而是进一步让你返回一个合理的上课顺序,保证开始修每个课程时,前置的课程都已经修完。
什么是拓扑排序?
拓扑排序就是让你把一幅图拉平,而且这个拉平的图里面,所有箭头方向都是一致的
很显然,如果一幅有向图中存在环,是无法进行拓扑排序的,因为肯定做不到所有箭头方向一致;反过来,如果一幅图是有向无环图,那么一定可以进行拓扑排序。
那这道题和拓扑排序有什么关系呢?
如果把课程抽象成节点,课程之间的依赖关系抽象成有向边,那么这幅图的拓扑排序结果就是上课顺序。
如何进行拓扑排序?
将后序遍历的结果进行反转就是拓扑排序的结果
为什么有的解法是不需要对后序遍历结果进行反转?
因为这种建图是对边的定义是依赖关系:graph[to].add(from)
而我们选择的是被依赖关系:graph[from].add(to)
被依赖关系就是比如节点
1指向2,含义是节点1被节点2依赖,即做完1才能去做2
还需要注意的是:
int from=edge[1];
int to=edge[0];
那到底是为什么拓扑排序需要反转呢?
以二叉树的遍历来讲解比较好理解:
我们都知道后序遍历是当左右子树的节点被装到结果列表里面,根节点才会被装进去
后序遍历的这一特点很重要,之所以拓扑排序的基础是后序遍历,是因为一个任务必须等到它依赖的所有任务都完成之后才能开始开始执行。
把二叉树理解成是一幅有向图,边的方向就是由父节点指向子节点
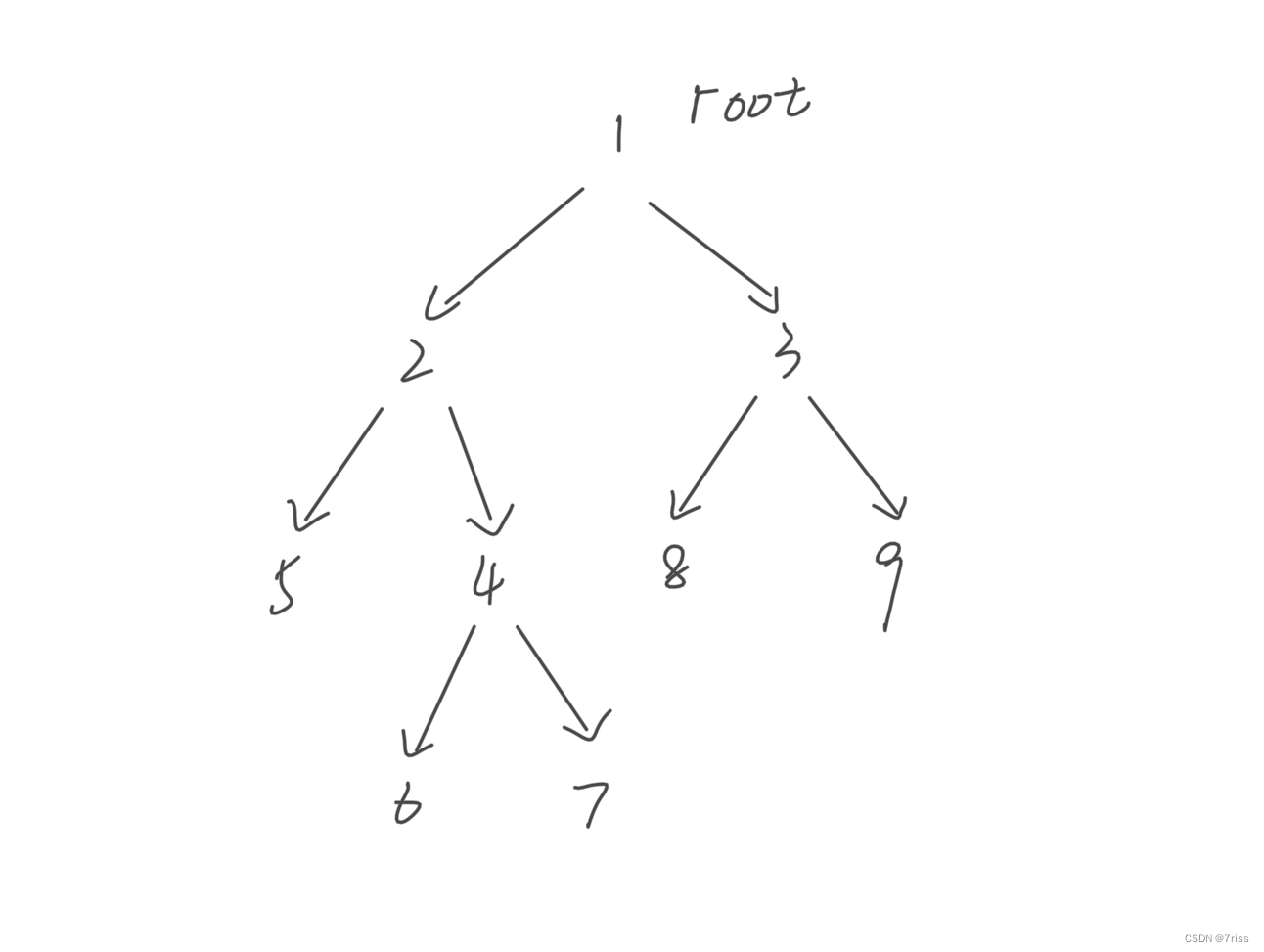
按照我们的定义,变得含义是被依赖关系,那么上图的拓扑排序应该是结点1,然后是2,3…
但显然标准的后序遍历结果不满足拓扑排序,而如果把后序遍历结果反转,就是拓扑排序结果了
完整代码如下:
//防止遍历重复结点
boolean[] visited;
//记录当前遍历的路径
boolean[] onPath;
//记录是否存在环
boolean hashCycle=false;
//后序遍历结果
List<Integer> post=new ArrayList<>();
public int[] findOrder(int numCourses, int[][] prerequisites) {
//建表
List<Integer>[] graph=buildGraph(numCourses,prerequisites);
visited=new boolean[numCourses];
onPath=new boolean[numCourses];
for(int i=0;i<numCourses;i++){
traverse(graph,i);
}
//判断是否有环
if(hashCycle){
return new int[]{
};
}
//没有环则进行拓扑排序
Collections.reverse(post);
for(int each:post){
System.out.println(each);
}
int[] result=new int[numCourses];
for(int j=0;j<numCourses;j++){
result[j]=post.get(j);
}
return result;
}
//建图函数
public List<Integer>[] buildGraph(int numCourses,int[][] prerequisites){
List<Integer>[] graph=new LinkedList[numCourses];
for(int i=0;i<numCourses;i++){
graph[i]=new LinkedList<>();
}
for(int[] edge:prerequisites){
int from=edge[1];
int to=edge[0];
graph[from].add(to);
}
return graph;
}
//图的遍历
public void traverse(List<Integer>[] graph,int s){
if(onPath[s]){
//表示存在环
hashCycle=true;
}
if(visited[s]||hashCycle){
return;
}
onPath[s]=true;
visited[s]=true;
for(int each:graph[s]){
traverse(graph,each);
}
post.add(s);
onPath[s]=false;
}
三、环检测算法(BFS 版本)
刚才讲了用 DFS 算法利用 onPath 数组判断是否存在环;也讲了用 DFS 算法利用逆后序遍历进行拓扑排序。
其实 BFS 算法借助 indegree 数组记录每个节点的入度,也可以实现这两个算法。
解题的思路:
- 构建邻接表,和DFS一样,边的方向表示被依赖关系。
- 构建一个
indegree数组记录每个节点的入度,即indegree[i]记录节点i的入度。- 对 BFS 队列进行初始化,将入度为 0 的节点首先装入队列。
- 开始执行 BFS 循环,不断弹出队列中的节点,减少相邻节点的入度,并将入度变为 0 的节点加入队列。
- 如果最终所有节点都被遍历过(
count等于节点数),则说明不存在环,反之则说明存在环。
用图理解就是:
以下图为例:
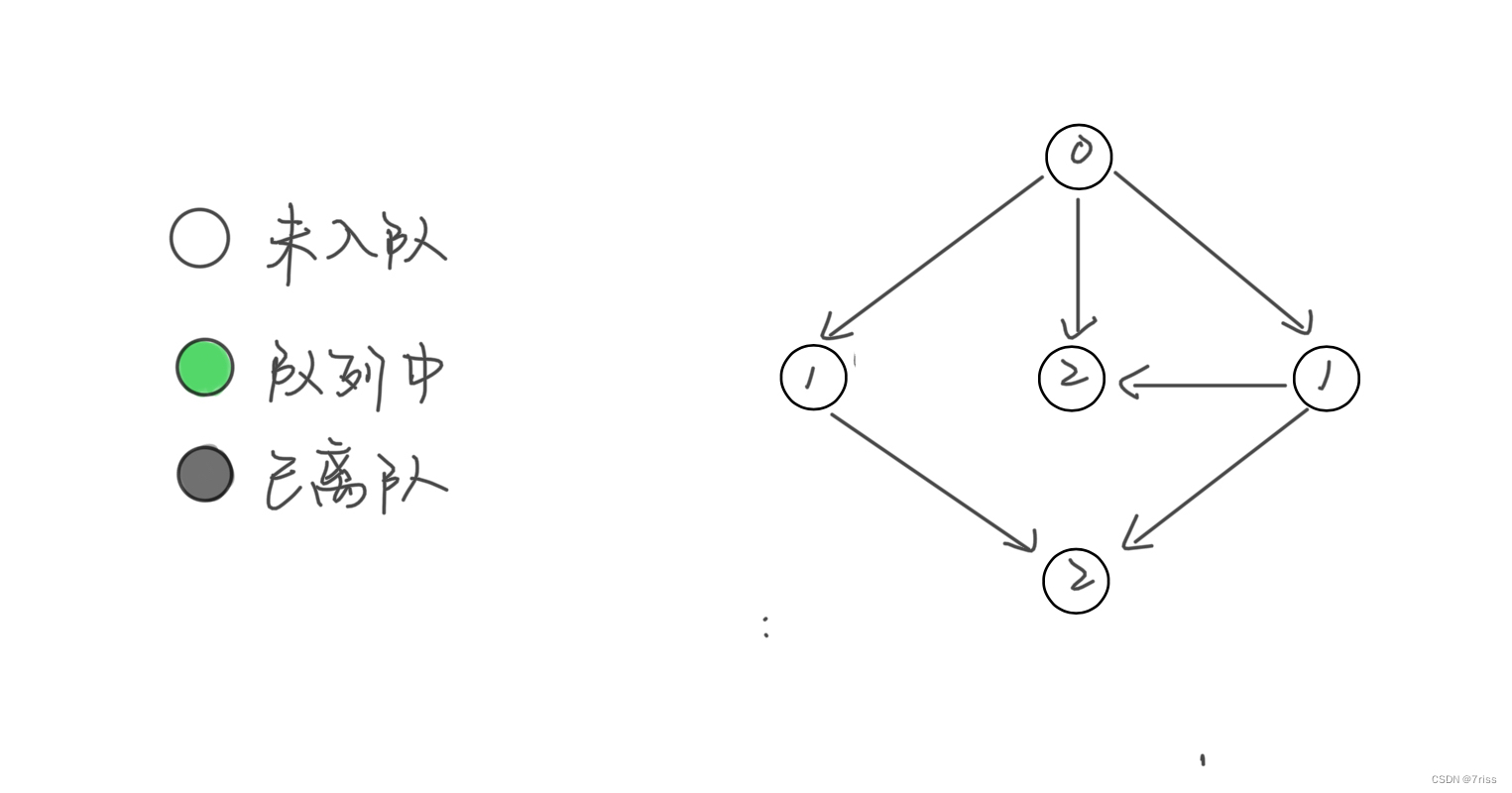
- 队列进行初始化后,入度为 0 的节点首先被加入队列
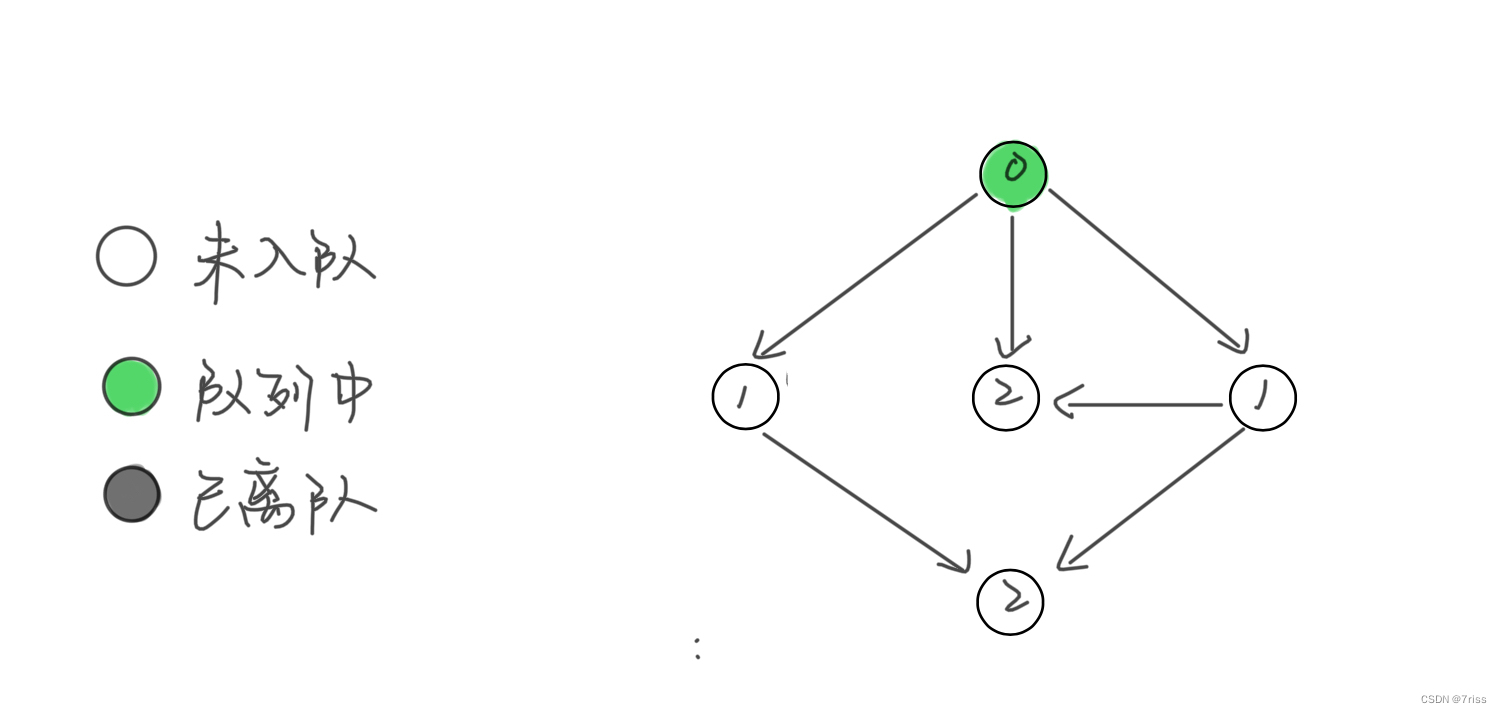
- 开始执行 BFS 循环,从队列中弹出一个节点,减少相邻节点的入度,同时将新产生的入度为 0 的节点加入队列
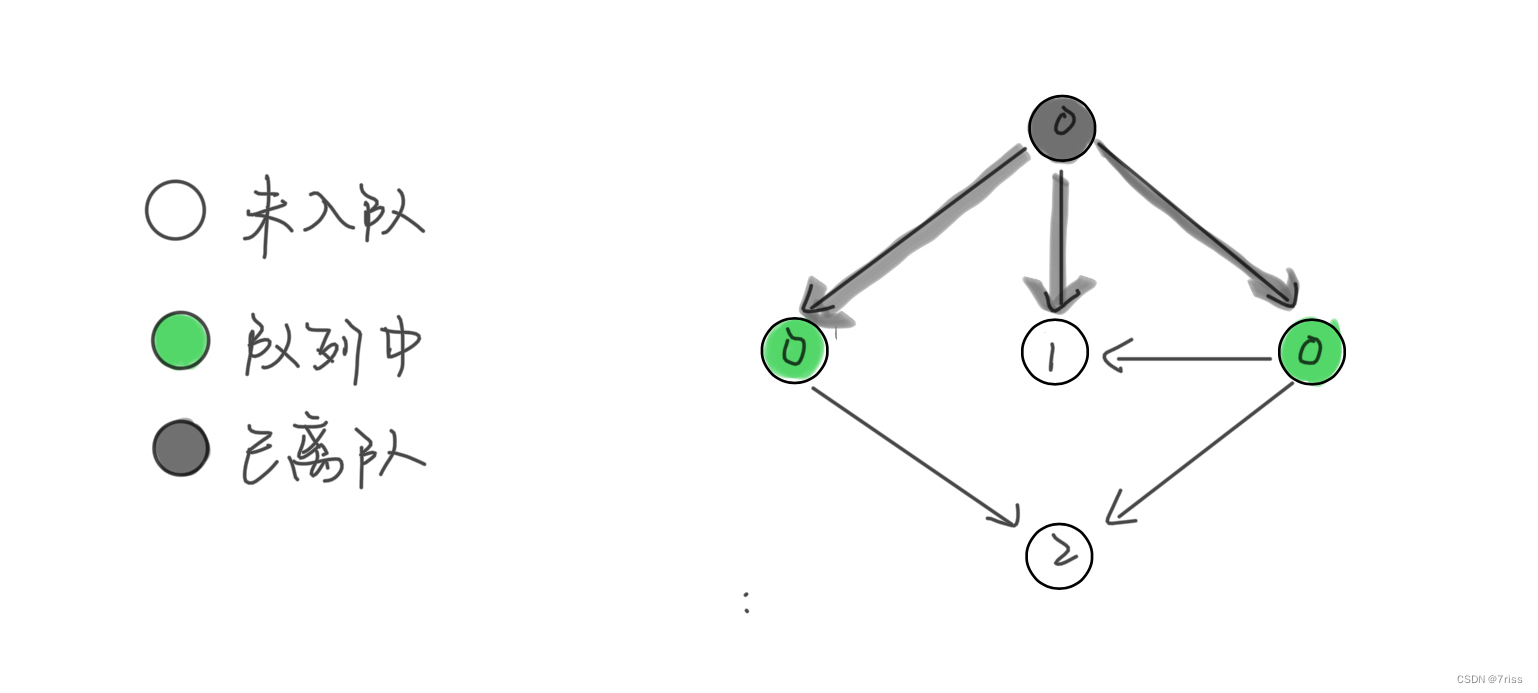
- 继续从队列弹出节点,并减少相邻节点的入度,这一次没有新产生的入度为 0 的节点
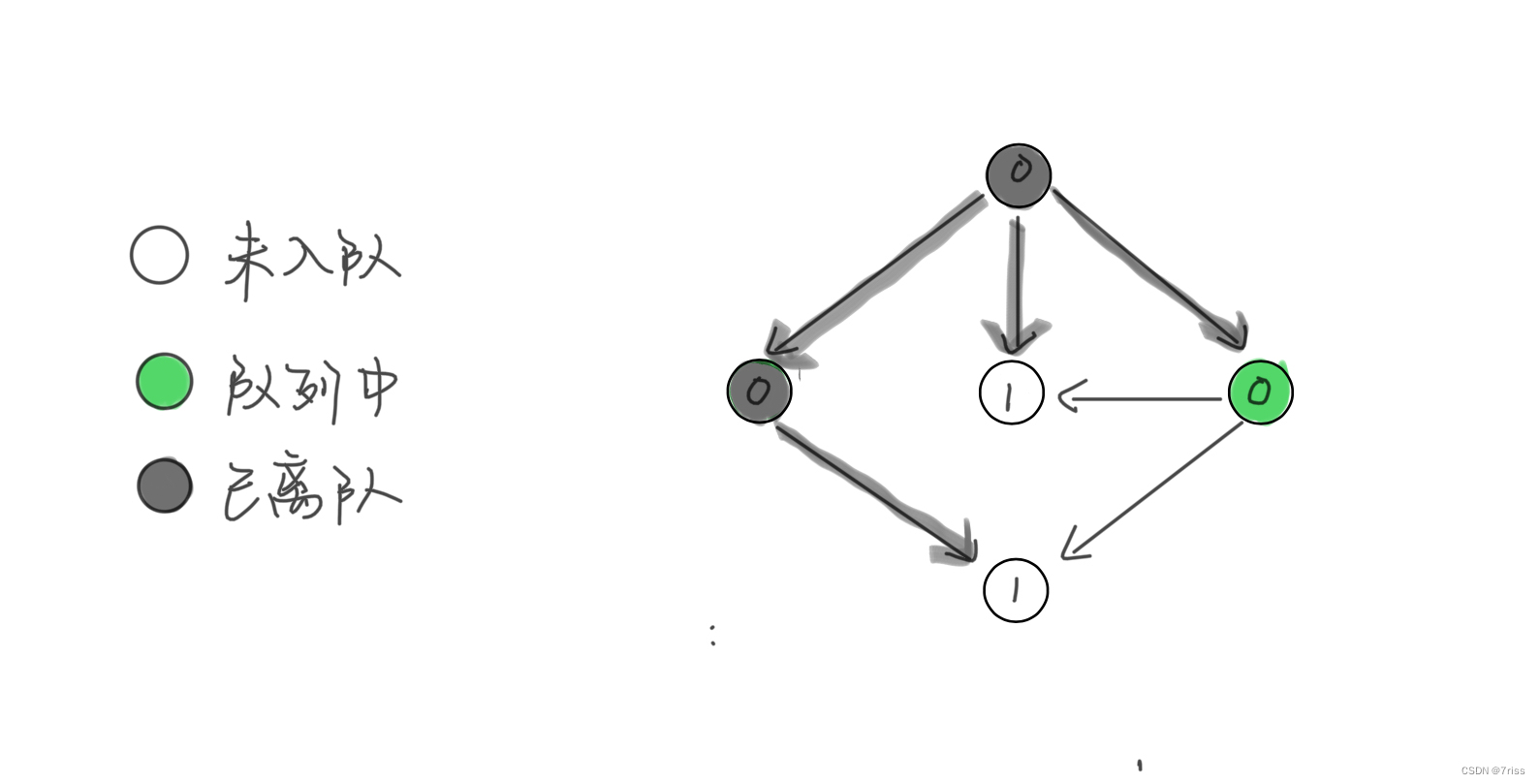
- 继续从队列弹出节点,并减少相邻节点的入度,同时将新产生的入度为 0 的节点加入队列
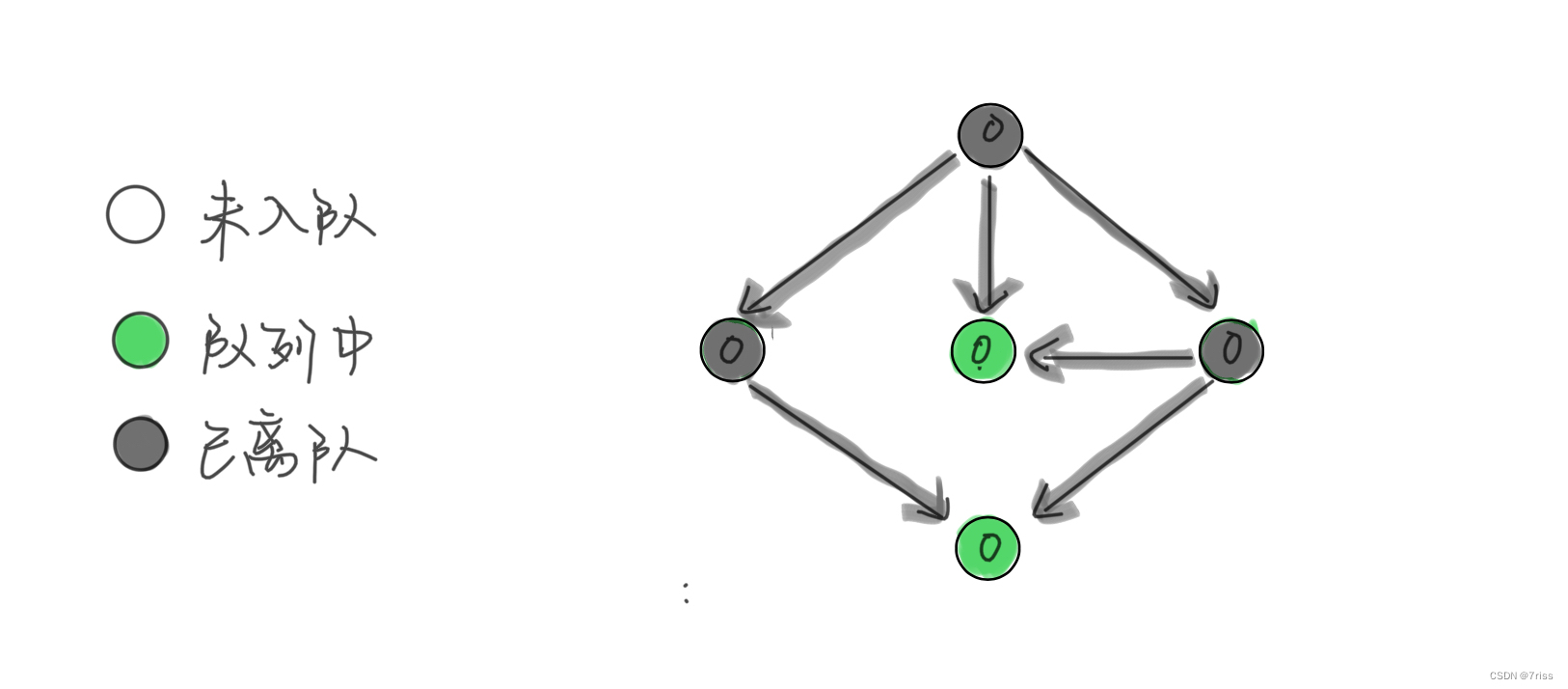
- 继续弹出节点,直到队列为空
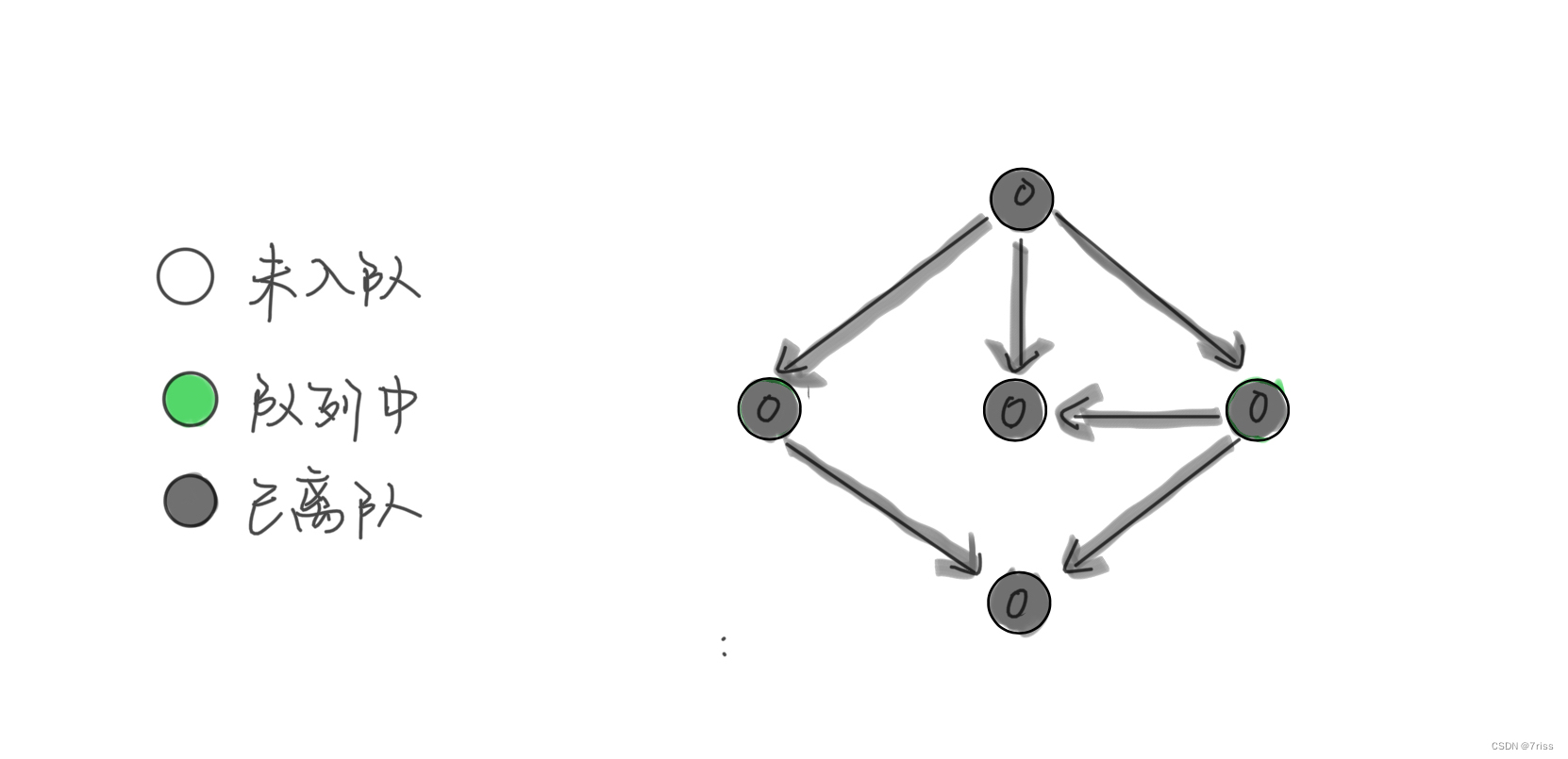
这时候,所有节点都被遍历过一遍,也就说明图中不存在环。
即如果按照上述逻辑执行 BFS 算法,存在节点没有被遍历,则说明成环。例如:
- 队列中最初只有一个入度为 0 的节点
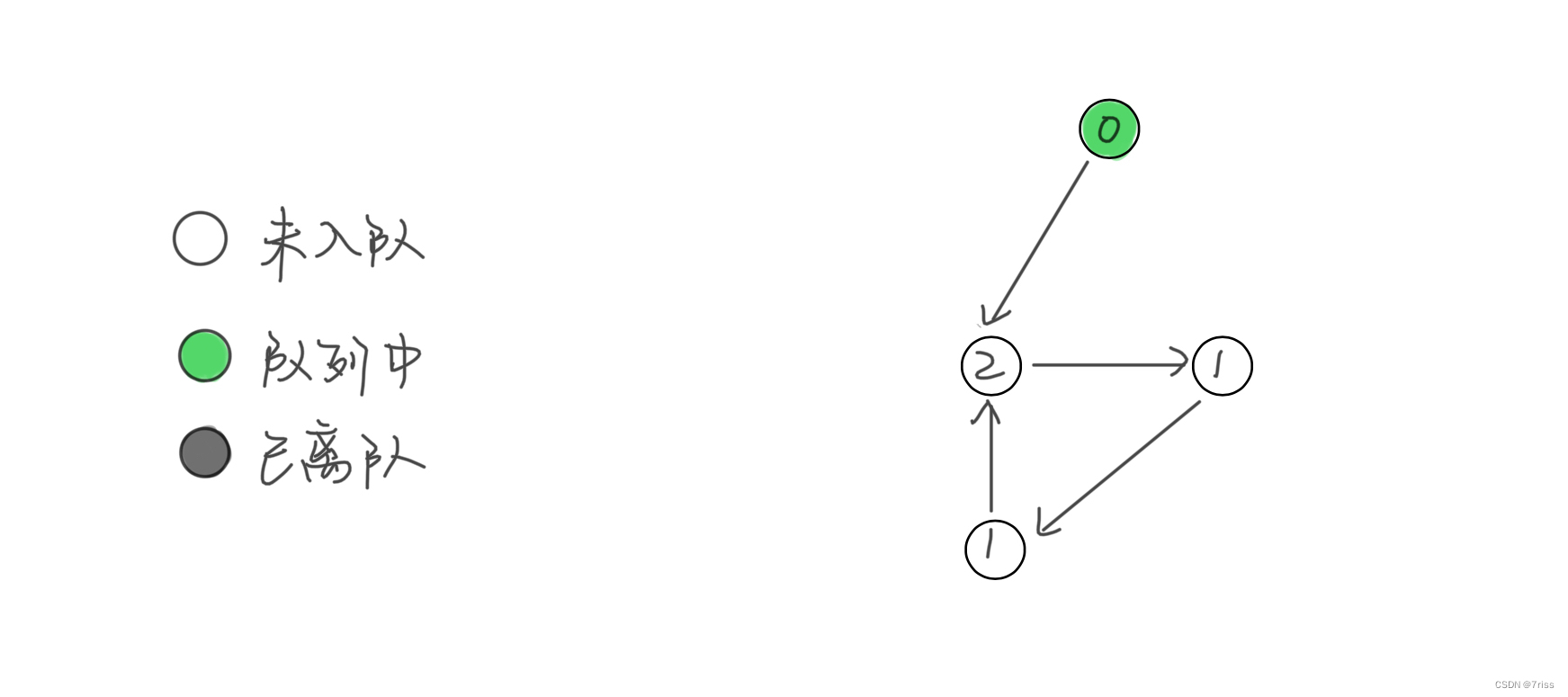
- 当弹出这个节点并减小相邻节点的入度之后队列为空,但并没有产生新的入度为 0 的节点加入队列,所以 BFS 算法终止
完整代码如下:
// 主函数
public boolean canFinish(int numCourses, int[][] prerequisites) {
// 建图,有向边代表「被依赖」关系
List<Integer>[] graph = buildGraph(numCourses, prerequisites);
// 构建入度数组
int[] indegree = new int[numCourses];
for (int[] edge : prerequisites) {
int from = edge[1], to = edge[0];
// 节点 to 的入度加一
indegree[to]++;
}
// 根据入度初始化队列中的节点
Queue<Integer> q = new LinkedList<>();
for (int i = 0; i < numCourses; i++) {
if (indegree[i] == 0) {
// 节点 i 没有入度,即没有依赖的节点
// 可以作为拓扑排序的起点,加入队列
q.offer(i);
}
}
// 记录遍历的节点个数
int count = 0;
// 开始执行 BFS 循环
while (!q.isEmpty()) {
// 弹出节点 cur,并将它指向的节点的入度减一
int cur = q.poll();
count++;
for (int next : graph[cur]) {
indegree[next]--;
if (indegree[next] == 0) {
// 如果入度变为 0,说明 next 依赖的节点都已被遍历
q.offer(next);
}
}
}
// 如果所有节点都被遍历过,说明不成环
return count == numCourses;
}
// 建图函数
List<Integer>[] buildGraph(int n, int[][] edges) {
// 见前文
}
四、拓扑排序算法(BFS 版本)
如果能理解BFS版本的环检测算法,那么很容易就得到BFS版本的拓扑排序,因为结点的遍历顺序就是拓扑排序的结果(即入队顺序)
完整代码如下:
// 主函数
public int[] findOrder(int numCourses, int[][] prerequisites) {
// 建图,和环检测算法相同
List<Integer>[] graph = buildGraph(numCourses, prerequisites);
// 计算入度,和环检测算法相同
int[] indegree = new int[numCourses];
for (int[] edge : prerequisites) {
int from = edge[1], to = edge[0];
indegree[to]++;
}
// 根据入度初始化队列中的节点,和环检测算法相同
Queue<Integer> q = new LinkedList<>();
for (int i = 0; i < numCourses; i++) {
if (indegree[i] == 0) {
q.offer(i);
}
}
// 记录拓扑排序结果
int[] res = new int[numCourses];
// 记录遍历节点的顺序(索引)
int count = 0;
// 开始执行 BFS 算法
while (!q.isEmpty()) {
int cur = q.poll();
// 弹出节点的顺序即为拓扑排序结果
res[count] = cur;
count++;
for (int next : graph[cur]) {
indegree[next]--;
if (indegree[next] == 0) {
q.offer(next);
}
}
}
if (count != numCourses) {
// 存在环,拓扑排序不存在
return new int[]{
};
}
return res;
}
// 建图函数
List<Integer>[] buildGraph(int n, int[][] edges) {
// 见前文
}
注意:图的遍历都需要 visited 数组防止走回头路,这里的 BFS 算法其实是通过 indegree 数组实现的 visited 数组的作用,只有入度为 0 的节点才能入队,从而保证不会出现死循环。