0.概述
温度漂移属于趋势线误差,可以通过数据拟合反向抵消其影响。温补的本质是系统辨识。
之前我们在介绍标定的时候,也说过一句类似的话“标定的本质是参数辨识”。这两者之间相似又不同。 参数辨识是指已知误差模型,去估计各误差量的实际值是多少,而系统辨识在做参数辨识之前,还要做模型辨识,因为器件偏差随温度变化的模型是未知的,不知道有几个变量,也不知道是几阶模型,这个事情就变得不那么简单。
按照搞技术的套路,事情越复杂,业界出现的方法就越多,我们一一来看。
1.温度补偿方法
1.1多项式拟合方法
最简单也最暴力的方法就是直接对"偏差-温度"曲线进行多项式拟合。
做这件事你需要有一台温箱,首先把温箱门打开,然后把IMU放进去,最后把温箱门带上。操作温箱让它升到设定温度,过程中采集IMU数据。
由于模型未知,我们需要先假设出多个模型,通过拟合参差来选择最合适的模型。比如你可以先假设这样的模型
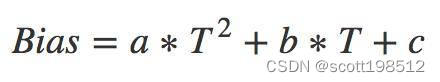
拟合时候可能会发现曲线重合度不好,觉得公式阶次有点低,那就改成3阶模型
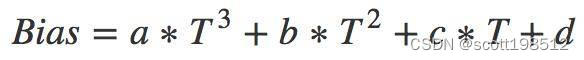
实际上,阶次越高,拟合的重合度越好,但是阶次太高,明显就会过拟合了,一般控制在3阶问题不大。
做完温补,满怀期待地拿去使用时,发现好像精度没有那么高,不得不重新再做一次,看看上次是不是做错了。于是把温箱门打开,把IMU放进去,把温箱门带上。操作温箱让它升到设定温度,过程中采集IMU数据。这次有点着急,让温度升得快了些。
使用上次同样的模型拟合参数,发现这次的重合度却非常不好,反复检查数据,两次都没有出错,问题出在哪了呢?
既然两次唯一的不同是温度升的快慢不一样,那是不是说明Bias除了和温度有关,还和温度的变化率相关?于是尝试这样的模型

其中dT就是温度变化率。
好像重合度变好了一些,而且两次采集的数据可以用同一个模型拟合了,多采几组数据,尝试不同的升降温速率,发现还有部分不太好,那是不是还有别的模型?尝试下

好像又好了一些,于是不停地把温箱门打开,把IMU放进去,把温箱门带上,不停地尝试新的模型。数天乃至数周之后选定了一个模型,不是因为找到了最精确的,是实在没劲儿了,就这么地吧,差不多得了。
1.2基于分段拟合的方法
之所以反复尝试,但最终仍不会太满意,是因为"偏差-温度"曲线都是奇型怪状的曲线,阶次高了则过拟合,阶次低了则重合度不够。于是会自然想到,把曲线分几段去拟合行不行,整体是不规则的,但是可以把它分割成几段规则的曲线。
这不失为一个可行的办法,分段的方式在各种论文里也随处可见。当然,发论文嘛,如果只是分段则显得逼格不够,总要在理论上搞得高端一些才行。于是,会经常看到有引入各种逻辑的分段,比如,在段与段的交界处,是应该更倾向于用左边这段的模型,还是右边这段的呢?为了解决这个问题,可以整一个模糊分段,交界处一定权重上属于左边模型,也一定权重上属于右边模型。
1.3基于神经网络的拟合
深度学习作为一门显学,已经统治一切,没有任何一个领域可以幸免。它把模型辨识和参数辨识直接一步完成,免去了要去假设模型的麻烦。
虽然深度学习在一些领域的渗透受到诸多争议,但是我认为把它用在这里,并非全是无意义的炼丹。
首先,在这次深度学习大火之前,神经网络已经在IMU器件温补上得到使用,因为温补模型的复杂性,导致它确实有这样明确的需求存在。
其次,排斥深度学习渗透的领域,多是物理模型极其明确的领域,比如,当我看到使用深度学习去做惯性导航位姿解算的方法时,会感到很反感,因为惯性导航的误差模型已经透明到不能再透明了。而对于温补这种模型还需要辨识的东西,使用神经网络去"端到端"一下,似乎并无不妥,当然,得使用更多的数据,否则过拟合也会很严重。
1.4 基于支持向量机(SVM)的拟合
SVM的主要思路是把数据映射到高维空间去拟合,既然在二维空间中,“偏差-温度”曲线不好拟合,那么就把它映射到高维空间去,那样,数据的线性度就会更强,可辨识度会更高一些。
2.总结与思考
1.为什么温度相关的模型都那么复杂?
本质上,器件偏差随温度的变化,是由温度引起器件材料变形导致的,器件不是一个理想的质点,而是一个材料块,所以它的温度不是一个温度点,而是一个温度场。
但是,对于我们测量来讲,只能测量一个点的温度,无法预知其他点的实际温度变化。虽然,各个点温度之间有相关关系,而且在互相热传导,我们可以对温度场建模,消除一部分影响,但随着复杂的外界环境变化,想靠一个模型就实现所有温度点的预测是完全不可能的。更恶劣的是,温度预测只是第一步,材料变形与温度变化的关系,器件偏差与材料变形的关系,都是极其复杂的。
面对这种问题,我们是不可能找到那个“正确”的模型的,虽然它就在那里,但就是得不到。这让我想起技术领域的一句名言"All models are wrong, but some are useful",找不到"正确"的,就找近似的,能用就行。
2.怎么选近似的?
那么多方法,应该怎么选,这是一个必须要回答的问题。
选择,其实就是把方法的优缺点和实际的需求去匹配。多项式拟合的方法显然是最工程的,它需要的运算量最小,物理意义最明确,缺点也很明显,就是拟合度不会那么高。对于基于神经网络或SVM的方法,理论上可以提高拟合度,但是会对数据量有大的需求,而且实际使用时,要消耗比较多的计算量。
所以,如果IMU器件本身的精度不是特别高,那么使用多项式拟合就足够用了。如果想再高一些,可以搞个分段,或者适当提高阶次。如果就非得跟残差死磕,那搞个神经网络也不是不可以。这种方法不只存在论文里,实际工程中确实有人在用,只是你要多开关几次温箱门,多费点功夫。
3.怎样设计样本数据?
我们知道,拟合就是个解方程的过程。构建方程时,各未知量的系数要提供足够的变化,这个方程才可解,才能解的好,或者说,才能正确辨识。
如果我们建的模型里有变温率的因素存在,而拟合时只提供一组升温的数据,那就是在玩自己了,因为我们提供的数据里,每一个温度点只对应一个变温率。因此,要反复升温降温,而且使用不同的升降温速率,提供丰富变化的数据,才是一个好的样本数据。