ChatGPT带领着大模型像雨后春笋一般层出不穷,大家都对大模型微调跃跃欲试,现在咱们聊聊其中的常见的算法
1 LORA
理论
低秩矩阵分解(Low Rank Matrix Factorization,LRMF)是一种常见的数据降维技术,它可以将高维数据映射到低维空间中,并尽量保留原始数据的重要信息。LoRA(Low Rank Approximation)是一种基于LRMF的矩阵近似算法,它可以在保持原始矩阵低秩性的前提下,进一步减小矩阵的存储和计算复杂度。
LoRA算法的核心思想是,将原始矩阵 A A A分解为两个低秩矩阵 X X X和 Y Y Y的乘积形式,即 A = X ⋅ Y A=X\cdot Y A=X⋅Y。具体地,LoRA算法会首先对原始矩阵进行SVD分解,得到矩阵 A = U Σ V T A=U\Sigma V^T A=UΣVT,其中 U U U和 V V V分别是 A A T AA^T AAT和 A T A A^TA ATA的特征向量矩阵, Σ \Sigma Σ是奇异值矩阵。然后,LoRA算法会取 U U U的前 k k k列和 V V V的前 k k k行,得到低秩矩阵 X = U ( : , 1 : k ) X=U(:,1:k) X=U(:,1:k)和 Y = V ( 1 : k , : ) Y=V(1:k,:) Y=V(1:k,:),其中 k k k是预设的参数,表示矩阵 A A A的秩。最后,LoRA算法将近似矩阵 A k = X ⋅ Y A_k=X\cdot Y Ak=X⋅Y作为原始矩阵 A A A的近似,即 A k ≈ A A_k \approx A Ak≈A。
LoRA算法的优点在于,它可以在保证矩阵低秩性的前提下,进一步减小矩阵的存储和计算复杂度。特别地,LoRA算法的存储复杂度为 O ( m k + n k ) O(mk+nk) O(mk+nk),计算复杂度为 O ( m n k ) O(mnk) O(mnk),其中 m m m和 n n n分别是矩阵 A A A的行数和列数。因此,LoRA算法适用于大规模数据的处理,特别是在资源受限的环境下,可以大幅度降低计算和存储开销。
总结:冻结预训练模型权重,并将可训练的秩分解矩阵注入到Transformer层的每个权重中,大大减少了下游任务的可训练参数数量
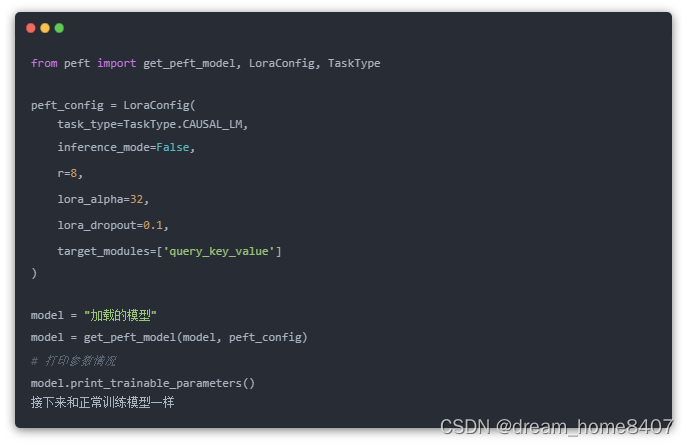
使用方式
HuggingFace的包peft对LoRA做了封装支持,调用api即可
模型并行计算
在并行训练过程中,各个显卡并行计算,每个模型使用同一份模型权重参数weights,在梯度下降更新时,各个进程会同步一次,致使每个进程的模型都跟新相同的梯度
具体实现,需要在model外套一层DistributedDataParallel,就可以实现backword前向更新梯度时,其他操作依旧,
使用DistributedDataParallel把model封装成ddp_model后,模型的参数名称里多了一个module,这是因为原来的模型model被保存到了ddp_model.module这个成员变量中。
在混用单GPU和多GPU的训练代码时,要注意这个参数名不兼容的问题,包括上面我们使用LoRA加载模型的时候,也会出现模型层名称变换了的情况。最好的做法是每次存取ddp_model.module,这样单GPU和多GPU的checkpoint可以轻松兼容。
人类反馈强化学习(RLHF)
RLHF-Stage1 是 supervised-fintuning,即使用上文提到的数据集进行模型微调。
RLHF-Stage2 训练了奖励模型,它通过对于同一个 prompt 的不同输出进行人工排序,得到对应分数,监督训练奖励模型。
RLHF-Stage3 使用了强化学习算法,是训练流程中最复杂的一部分:
RLHF(Reinforcement Learning Hyperparameter Optimization Framework)是一种用于强化学习模型的超参数优化框架。它结合了强化学习中的经典方法和贝叶斯优化技术,能够更高效地找到最佳超参数组合。下面是强化学习微调的完整 RLHF 流程:
数据预处理:根据需要对强化学习任务的数据进行处理,如归一化、去噪等。
确定超参数空间:为每个超参数指定范围和分布,以便进行超参数优化。
确定评估指标:根据强化学习任务的性质和目标,选择合适的评估指标,如累积回报、平均奖励等。
设计搜索策略:根据评估指标和超参数空间的特点,选择合适的搜索策略,如随机搜索、网格搜索、贝叶斯优化等。
进行超参数优化:使用选择的搜索策略在超参数空间中搜索最优超参数组合,并记录每个超参数组合的性能。
分析结果:分析每个超参数组合的性能和超参数之间的关系,以了解哪些超参数对模型性能有重要影响。
微调模型:根据分析结果,
p tuning v2简单来说其实是soft prompt的一种改进,soft prompt是只作用在embedding层中,实际测试下来只作用在embedding层的话交互能力会变弱,而且冻结模型所有参数去学习插入token,改变量偏小使得效果有时候不太稳定,会差于微调。p tuning v2则不只是针对embedding层,而是将连续型token插入每一层,增大改变量和交互性。
这是对于低资源微调大模型的共同点都是冻结大模型参数,通过小模块来学习微调产生的低秩改变。但目前存在的一些问题就是这两种训练方式很容易参数灾难性遗忘,因为模型在微调的时候整个模型层参数未改变,而少参数的学习模块微调时却是改变量巨大,容易给模型在推理时产生较大偏置,使得以前的回答能力被可学习模块带偏,在微调的时候也必须注意可学习模块不能过于拟合微调数据,否则会丧失原本的预训练知识能力,产生灾难性遗忘。
最好能够在微调语料中也加入通用学习语料一起微调,避免产生对微调语料极大的偏向,在instruct gpt论文中也提到在强化学习ppo的时候模型也会很容易对于ppo数据拟合,降低模型通用自然语言任务能力,所以在ppo loss中加入了SFT梯度和预训练梯度来缓解这种遗忘问题