掌握调度器原理 能够根据要求把Pod 定义到想要的节点运行
kube-scheduler是kubernetes系统的核心组件质疑,主要负责整个集群资源的调度功能,根据特定的调度算法和策略,将Pod调度到最优的一个工作节点上面去,从而更加的合理、更加充分的利用集群的资源。
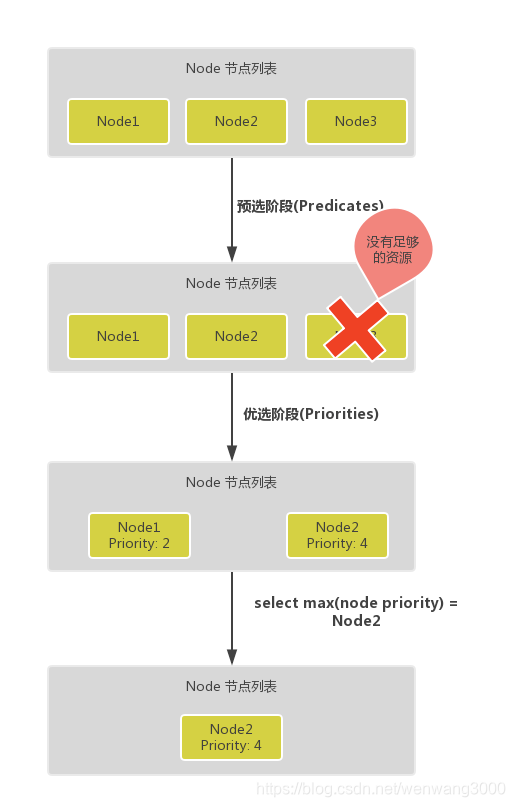
调度主要分为以下几个部分
- 预选过程 过滤不满足条件的节点,这个过程称为Predicates
- 优选过程 对通过的节点按照优先级排序,称之为Priorities
- 最后从中选择优先级最高的节点
其中Predicates过滤有一系列的算法可以使用,我们这里简单列举几个: - PodFitsResources:节点上剩余的资源是否大于 Pod 请求的资源
- PodFitsHost:如果 Pod 指定了 NodeName,检查节点名称是否和 NodeName 匹配
- PodFitsHostPorts:节点上已经使用的 port 是否和 Pod 申请的 port 冲突
- PodSelectorMatches:过滤掉和 Pod 指定的 label 不匹配的节点
- NoDiskConflict:已经 mount 的 volume 和 Pod 指定的 volume 不冲突,除非它们都是只读的
- CheckNodeDiskPressure:检查节点磁盘空间是否符合要求
- CheckNodeMemoryPressure:检查节点内存是否够用
除了这些过滤算法之外,还有一些其他的算法,更多更详细的我们可以查看源码文件:k8s.io/kubernetes/pkg/scheduler/algorithm/predicates/predicates.go。
Predicates阶段首先会遍历全部节点,过滤不满足条件的节点,属于强制性规则,这一阶段输出的所有满足要求的Node将被记录并作为第二阶段的输入,如果所有的节点都不满足条件,那么Pod将会一直处于Pending状态,直到有节点满足条件,在这期间调度器会不断的重试。
Priorities阶段即再次对节点进行筛选,如果有多个节点都满足条件的话,那么系统会根据节点的优先级(priorites)大小对节点进行排序,最后选择优先级最高的节点来部署Pod应用。
而Priorities优先级是由一系列键值对组成的,键是该优先级的名称,值是它的权重值,同样,我们这里给大家列举几个具有代表性的选项:
- LeastRequestedPriority:通过计算 CPU 和内存的使用率来决定权重,使用率越低权重越高,当然正常肯定也是资源是使用率越低权重越高,能给别的 Pod 运行的可能性就越大
- BalancedResourceAllocation 节点上CPU和Memory使用率约接近,权重越高,这个应该和上面的一起使用,不应该单独使用
- SelectorSpreadPriority:为了更好的高可用,对同属于一个 Deployment 或者 RC 下面的多个 Pod 副本,尽量调度到多个不同的节点上,当一个 Pod 被调度的时候,会先去查找该 Pod 对应的 controller,然后查看该 controller 下面的已存在的 Pod,运行 Pod 越少的节点权重越高
- ImageLocalityPriority:就是如果在某个节点上已经有要使用的镜像节点了,镜像总大小值越大,权重就越高
- NodeAffinityPriority:这个就是根据节点的亲和性来计算一个权重值,后面我们会详细讲解亲和性的使用方法
自定义调度
上面就是 kube-scheduler 默认调度的基本流程,除了使用默认的调度器之外,我们也可以自定义调度策略,通过spec:schedulername参数指定调度器的名字。
首先需要通过指定的 API 获取节点和 Pod
然后选择phase=Pending和schedulerName=my-scheduler的pod
计算每个 Pod 需要放置的位置之后,调度程序将创建一个Binding对象
然后根据我们自定义的调度器的算法计算出最适合的目标节点
调度器扩展
kube-scheduler在启动的时候可以通过 --policy-config-file参数来指定调度策略文件,我们可以根据我们自己的需要来组装Predicates和Priority函数。选择不同的过滤函数和优先级函数、控制优先级函数的权重、调整过滤函数的顺序都会影响调度过程。
下面是官方的 Policy 文件示例 (有时间在研究 TODO):
{
"kind" : "Policy",
"apiVersion" : "v1",
"predicates" : [
{
"name" : "PodFitsHostPorts"},
{
"name" : "PodFitsResources"},
{
"name" : "NoDiskConflict"},
{
"name" : "NoVolumeZoneConflict"},
{
"name" : "MatchNodeSelector"},
{
"name" : "HostName"}
],
"priorities" : [
{
"name" : "LeastRequestedPriority", "weight" : 1},
{
"name" : "BalancedResourceAllocation", "weight" : 1},
{
"name" : "ServiceSpreadingPriority", "weight" : 1},
{
"name" : "EqualPriority", "weight" : 1}
]
}
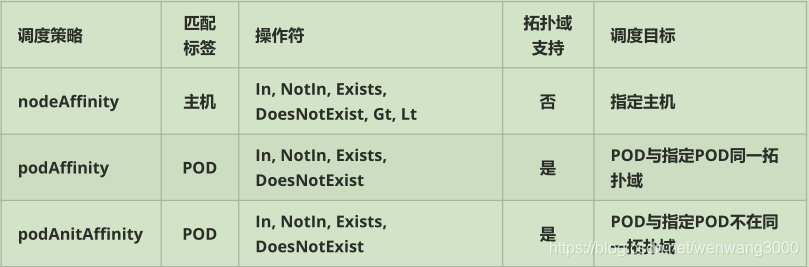
node亲和性
pod.spec.nodeAffinity
requiredDuringSchedulingIgnoredDuringExecution 硬策略
preferredDuringSchedulingIgnoredDuringExecution 软策略
键值运算关系
in :label的值在某个列表中
notin:不在
gt:大于
lt:小于
exists:存在
doesnotexist:不存在
查看节点标签
# kubectl get node --show-labels
标签信息

实验
# vim node.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: affinity
labels:
app: affinity
spec:
replicas: 3
selector:
matchLabels:
app: affinity
template:
metadata:
labels:
app: affinity
spec:
containers:
- name: nginx
image: nginx
ports:
- name: http
containerPort: 80
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: NotIn
values:
- k8s.node2.com
# kubectl apply -f node.yaml
# kubectl get pod -o wide
查看所有pod没有在node上运行

Pod亲和性
pod.spec.affinity.podAffinity/podAntAffinity
requiredDuringSchedulingIgnoredDuringExecution 硬策略
preferredDuringSchedulingIgnoredDuringExecution 软策略
实验
# vim tomcat.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: tomcat-test
labels:
app: web01
spec:
replicas: 1
selector:
matchLabels:
app: web01
template:
metadata:
labels:
app: web01
spec:
containers:
- name: tomcat
image: tomcat
ports:
- name: http
containerPort: 8080
# kubectl apply -f tomcat.yaml
# vim pod.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-test
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- name: http
containerPort: 8080
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- web01
topologyKey: kubernetes.io/hostname
# kubectl apply -f pod.yaml
# 查看结果,2个pod运行在同一个节点上
#kubectl get pod -o wide
调度策略
污点 Taint 容忍 Toleration
节点亲和性,是pod的一种属性(偏好或硬性要求),它使pod被吸引到一类特定的节点。Taint 则相反,它使节点能够排斥一类特定的pod。
Taint 和toleration 相互配合,可以用来避免pod被分配到不合适的节点上。每个节点上都可以应用一个或多个taint ,这表示对于那些不能容忍这些taint 的pod,是不会被该节点接受的。如果将toleration 应用于pod上,则表示这些pod可以(但不要求)被调度到具有匹配taint 的节点上
污点(Taint )
使用kubectl taint 命令可以给某node节点设置污点,Node被设置上污点之后就和pod之间存在了一种相斥的关系,可以让Node拒绝Pod的调度执行,甚至将Node已经存在的Pod驱逐出去
每个污点的组成如下:
key =value:effect
每个污点有一个key和value 作为污点的标签,其中value 可以为空,effect 描述污点的作用。当前taint
effect 支持如下三个选项:
- NoSchedule :表示k8s将不会将pod调度到具有该污点的Node上
- PreferNoSchedule :表示k8s将尽量避免将pod调度到具有该污点的Node上
- NoExecute :表示k8s将不会将pod调度到具有该污点的Node上,同时会将Node上已经存在的pod驱逐出去
#设置污点
kubectl taint nodes k8s.node1.com key1 =value1:NoSchedule
kubectl describe node k8s.node1.com |grep Taints
#节点说明中,查找Taints 字段
kubectl describe pod pod-name
#去除污点 【-】
kubectl taint nodes key1 :NoSchedule-
主节点默认有一个污点(NoSchedule ),所以pod不会被调度到主节点

容忍(Tolerations )
设置了污点的Node将根据taint 的effect :NoSchedule PreferNoSchedule .、NoExecute :和pod之间产生互的关系,od将在一定程度上不会被调度到ode上。但我们可以在pod上设置容忍(( Toleration),意思
是设置了容忍的Pod将可以容忍污点的存在,可以被调度到存在污点的Node上
pod.spec.tolerations
tolerations :
-key :" key1
operator :" Equal
value :" value1"
effect :" NoSchedule
tolerationseconds :3600
-key :" key1"
operator :" Equal
value :" value1"
effect :" NoExecute
-key :" key2
operator :" Exists
effect :" NoSchedule"
- 其中key,vaule ,effect !要与ode上设置的taint 保持一致
- operator 的值为Exists 将会忽略value 值
- tolerationSeconds 用于描述当pod需要被驱逐时可以在pod上继续保留运行的时间
1.当不指定key值时,标识容忍所有的污点key:
tolerations:
- operator: “Exists”
2.当不指定effect值时,标识容忍所有的污点作用
tolerations:
- key: "key"
operator: "Exists"
3.有多个master存在时,防止资源浪费,可以如下设置
kubectl taint nodes Node-name node-role.kubernates.io/master=:PerferNoSchedule
实验
#首先在k8s-01节点配置污点,将之前的pod全部移除
kubectl taint nodes k8s.node1.com key1=value:NoExecute
kubectl describe node k8s.node1.com |grep Taints
# vim tolerations.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: affinity
labels:
app: affinity
spec:
replicas: 3
selector:
matchLabels:
app: affinity
revisionHistoryLimit: 10
template:
metadata:
labels:
app: affinity
spec:
containers:
- name: nginx
image: nginx
ports:
- name: http
containerPort: 80
tolerations:
- key: "key1"
operator: "Equal"
value: "value"
effect: NoExecute
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- k8s.node1.com
kubectl apply -f tolerations.yaml
#目前所有的Pod都调度在k8s.node1.com节点上,
但是如果我们这里规则写的不匹配,那么Pod将处于pending状态
# kubectl get pod -o wide
实战应用
当集群中的某一个节点需要升级时(维护、停服重启),可以在该节点上打一个污点,把上面的pod转移到其他节点,升级完成后在删除污点
指定节点调度
1.Pod.spec.nodeName 见Pod直接调度到指定的node节点上,会调过schedule的调度策略,是强制匹配
apiVersion: apps/v1
kind: Deployment
metadata:
name: affinity
labels:
app: affinity
spec:
replicas: 3
selector:
matchLabels:
app: affinity
revisionHistoryLimit: 10
template:
metadata:
labels:
app: affinity
spec:
nodeName: k8s.node1.com
containers:
- name: nginx
image: nginx
ports:
- name: http
containerPort: 80
2.Pod.spec.nodeSelector:通过kubernates的label-selector机制选择节点,由调度器调度策略匹配label,然后调度pod到目标节点,该匹配规则属于强制约束
apiVersion: apps/v1
kind: Deployment
metadata:
name: affinity
labels:
app: affinity
spec:
replicas: 3
selector:
matchLabels:
app: affinity
revisionHistoryLimit: 10
template:
metadata:
labels:
app: affinity
spec:
nodeSelector:
disk: ssd
containers:
- name: nginx
image: nginx
ports:
- name: http
containerPort: 80
# 服务启动后 处于pending状态
kubectl label node k8s.node1.com disk=ssd
给节点1打个标签,查看服务创建成功