1. 论文简介
Look
论文名:You Only Look Once: Unified, Real-Time Object Detection
论文地址 :YOLOv1
论文作者:Joseph Redmon, Santosh Divvala, Ross Girshick , Ali Farhadi
论文时间:2016年CVPR
2. 网络结构
YOLOv1的网络结构借鉴了GooLeNet,共包含24个卷积层,2个全连接层,其中,3x3的卷积后接1x1 reduction layer来取代GooLeNet的inception module。

输入:448 x 448 x 3
前向传播:24个Conv Layer + 2个FC,3x3的卷积后接1x1的卷积来做通道上的降维,最后一个FC层包含1470个神经元,得到1470x1的输出,经过reshape后得到7 x 7 x 30的tensor。卷积层和全连接层采用Leaky ReLU激活函数,最后一层采用线性激活函数。

输出:最后一层FC的输出经过reshape后得到7 x 7 x 30的tensor,也就是,每个grid cell都有一个30维的输出,代表包含2个bounding box的信息和20个类别概率,下文马上介绍。
3. 7 x 7 x 30的解释
(1)YOLOv1首先会将图片划分为SxS个grid cell(网格),如果某个object的中心落在这个网格中,那么这个网格就负责预测这个object。论文中取S=7。例如,下图中,狗的中心点所在的grid cell就负责预测这只狗。


(2)每个网格预测B个bounding box。论文中取B=2。
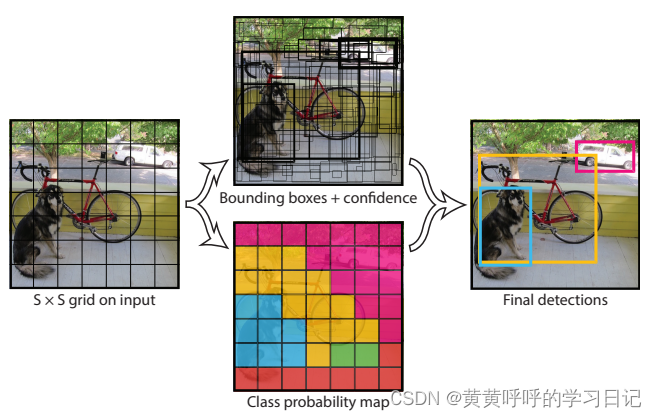
具体的:
每个bounding box的预测信息包含位置和confidence值m,也就是,每个bounding box的预测信息包含5个值:x,y,w,h,confidence。
confidence值是YOLO系列网络特有的一个值,它衡量了模型以多大的置信度认为这个box包含了目标物体以及这个box的准确率有多高。
当bounding box中存在目标时,Pr(Object)=1,此时confidence=IOU(交并比);当bounding box中不存在目标时,Pr(Object)=0,此时confidence=0。

x,y是bounding box的中心点坐标,它是相对于grid cell而言的值(所以是0-1之间的值),w,h是bounding box相对于整个图像的宽和高的相对值(所以也是0-1之间的值),即w=bounding box的宽/图片的宽,h=bounding box的高/图片的高。(YOLOv1中没有anchor的概念,是直接预测这几个值的)


每个grid cell还会预测C个条件类别概率,,它表示在bounding box包含了目标的情况下属于C个类别的概率。这里需要注意,虽然每个grid cell会预测B个bounding box,但是每个grid cell只预测一组类别概率。
在测试阶段,会将条件概率和confidence值相乘。条件概率即:每个bounding box分别属于每个类的概率值,例如Pascal VOC数据集有20个类,那么这里的概率值就有20个,公式为:
也就是测试阶段输出的概率分数即包含了这个bounding box内包含某个目标的概率,也包含了这个bounding box与真实目标的重合程度。
于是!!!最终的输出为7x7x30。(Pascal VOC数据集一共有20类)
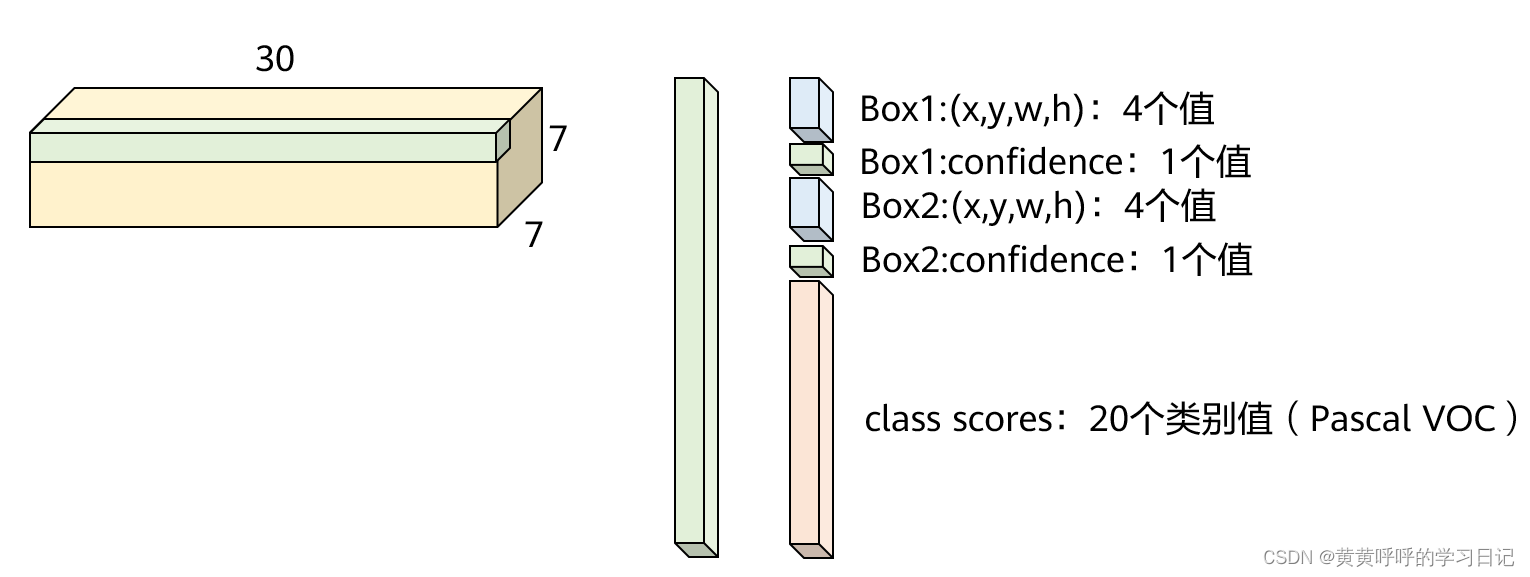
输入图片被分成7x7个网格,每个网格预测输出2个bounding box,每个bounding box包含5个值:4个坐标+1个置信度,另外每个网格预测输出20个类别(针对Pascal VOC数据集),所以最终预测输出的维度为:7 x 7 x (4 + 1 + 4 + 1 + 20) = 7 x 7 x 30,如下图所示。
4. 损失函数

包含了:bounding box损失+confidence损失+classes损失。
主要采用:sum-square error,因为优化起来比较方便。
损失函数中,bounding box损失的系数,不包含目标的confidence系数
,这是因为:在一张图片中,很多grid cell并不包含目标,这会导致confidence值为0,影响包含了目标的这些grid cell的梯度的作用,也会导致模型不稳定,过早发散。

bounding box损失:
1)并不是所有的bounding box都参与损失的计算。满足:第i个grid cell中包含目标,同时,该grid cell中第j个bounding box和ground truth有最大的IoU值,那么这个bounding box才参与loss的计算,其他的不满足条件的bounding box不参与损失的计算。
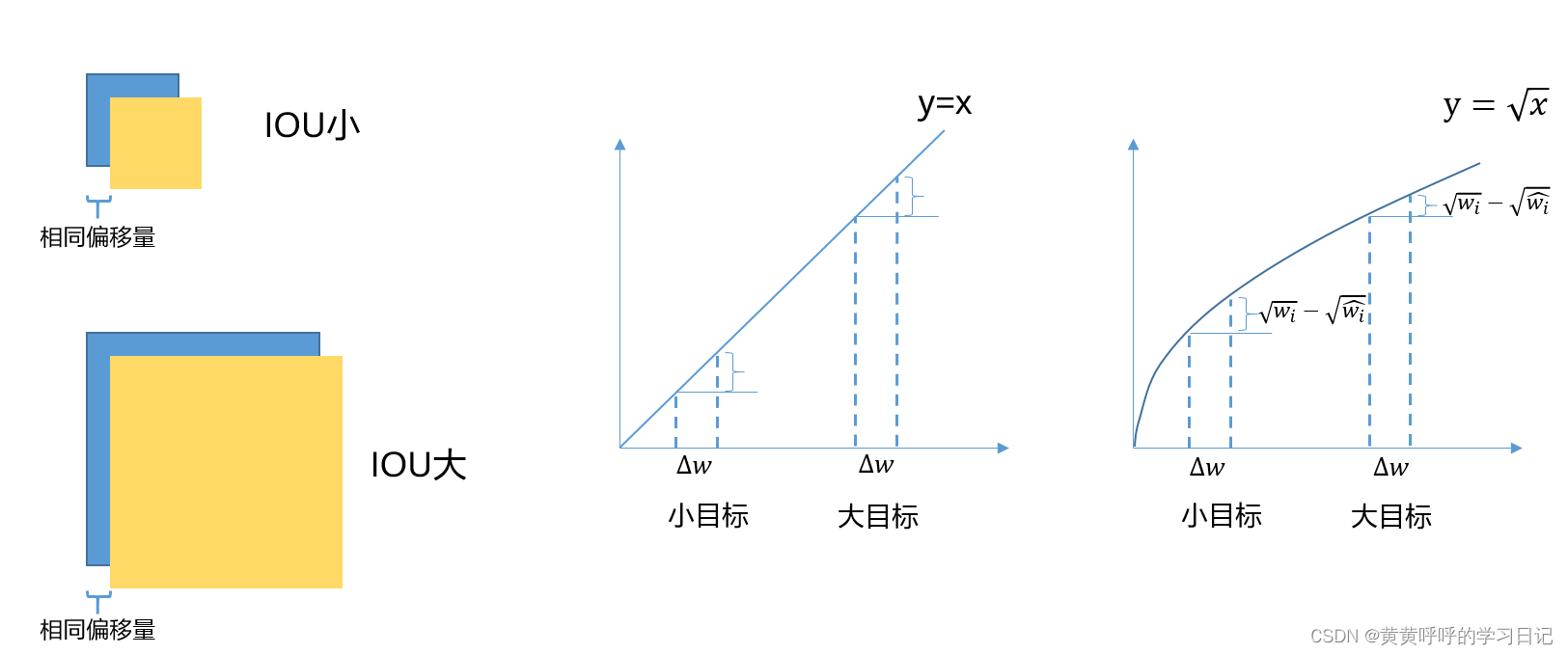
2)位置损失部分,宽和高取开根号处理。作者在论文中提出,损失是应该要反映出小偏移量对于大目标带来的影响是小于小目标的。具体分析如下:假设有两个不同大小的目标,在两个bounding box有相同的偏移量时,小目标相对于大目标来说,这个bounding box的预测效果明显更差,如左图所示。而在采用开根号之后,相同的偏移量下,小目标带来的损失明显是大于大目标的,对比右边两图可知。
confidence损失:
同样需要满足:第i个grid cell中包含目标,同时,该grid cell中第j个bounding box和ground truth有最大的IoU值,那么这个bounding box才参与loss的计算。
分类误差:以回归误差的方式来计算,同样是使用sum-squared error。需要注意的是只有包含object的grid cell才参与分类loss的计算。
5. 模型训练
首先在ImageNet上对网络中的前20层+一个平均池化层+FC层进行预训练,训练花了将近一个星期获得top-5正确率88%(ImageNet2012验证集上)。然后,前20层后接上4层卷积和2层全连接层进行检测训练。也就是,前20层是用预训练网络初始化的,最后的这6层是随机初始化的。
因为检测需要更多的图片细节信息,训练时,将输入图片从224x224调整为448x448。
batch size大小为64,优化器选择momentum(0.9),weight decay=0.0005。
学习率:先逐渐从0.001增大到0.01(如果一开始就比较大,模型训练会因为梯度的不稳定而发散),然后的75个epoch,学习率为0.01,再30个epoch,学习率为0.001,最后的30个epoch是0.0001。
采用了dropout,第一个全连接后引入了dropout,rate设为0.5。
数据增强:近20%的图片进行了随机scaling,随机调整了图片HSV颜色空间的exposure值和saturation值。
6. 存在问题
每个grid cell只预测两个bounding box和一组类别,这就限制了预测重叠或邻近物体的数量,比如说两个物体的中心点都落同一个grid cell中,这个grid cell只能预测一个类别。对于群体性的目标难以检测。
YOLOv1是根据训练数据来预测bounding box的,当测试数据中出现了新的或者不太常见的长宽比(尺寸)时,预测结果较差,泛化能力较差。
网络经过多次下采样,最终得到coarse feature(分辨率小,比较粗?),这会影响到物体的检测。
损失函数的设计没有很好地区分小目标和大目标。
作者发现,主要的错误原因来自于定位不准确,因为YOLOv1直接预测目标的坐标信息,而Faster R-CNN预测的是相对于anchor box的offset。从YOLOv2开始基于anchor的预测。
7. 性能对比


8.如果某处表达不当,烦请指出,谢谢。