1. 论文思想
YOLO(YOLO-v1)是最近几年提出的目标检测模型,它不同于传统的目标检测模型,将检测问题转换到一个回归问题,以空间分隔的边界框和相关的类概率进行目标检测。在一次前向运算中,一个单一的神经网络直接从完整的图像中预测边界框和类概率。由于整个检测管道是一个单一的网络,可以直接从检测性能上进行端到端优化。其结构如下图:

由于YOLO模型的独特,致使其速度相比之前的网络快了很多。与Fast R-CNN相比,YOLO产生更多的定位错误,但不太可能在后台预测误报。由于将对象检测作为一个单一的回归问题重新框架,直接从图像像素到边界框坐标和类概率。因而YOLO-V1具有如下的优点:
(1)YOLO的速度极快,并且其平均精确度是论文当时其它实时目标检测算法的两倍。
(2)YOLO由全图的信息进行推理和预测。
(3)YOLO学习对象的可推广表示。YOLO在检测精度上落后于最先进的目标检测系统,但是它可以快速检测出图像中的物体,提升特别是小目标定位的精度。
2. 统一检测网络
在YOLO中将目标检测与识别结合起来形成一个网络。网络中使用全图的特征进行检测边界框的预测以及对应目标的分类。因而YOLO就可以使用全图信息进行全图目标检测与识别。这就使得YOLO具有端到端的检测能力与实时的检测速度,同时保持较高的平均精度。
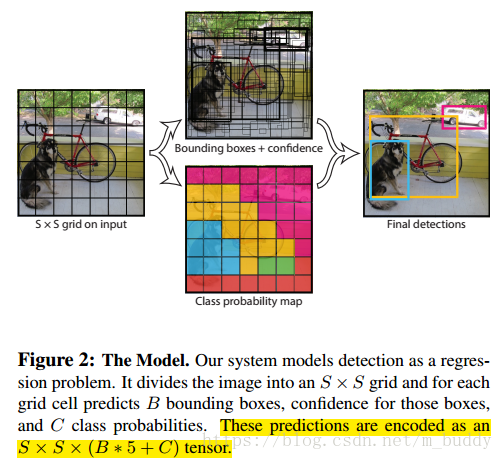
YOLO将图像划分为S*S的网格,如上图。如果目标物体的中心落到了某个网格的中心,那么该网格负责检测该目标。
每个单元格预测B个边界框和其置信度。这些置信度的值反映了边界框是否包含目标概率与当前边界框与Ground Truth重合的情况(IOU)。其定为
对于那些没有包含目标的单元格,他们的置信度应该等于0。否则应该由IOU以及是否包含目标的结果确定。
每个边界框包含了5个预测值: 以及置信度, 的坐标代表边界框的中心相对于所在单元格的位置。 是相对于整幅图像而言的。置信度的含义上面讲过了。
对于每个单元格预测全部分类的条件概率。代表的是当前单元格包含某类目标的条件概率。论文中只预测每个单元格分类的概率,并不是边界框B。即是
在测试时,我们将条件类的概率和单个盒子的置信度预测相乘,得到
2.1 网络设计
论文使用的网络结构为卷积网络(24层)加上两层全连接层,卷积层负责图像特征的提取,全连接层负责概率预测与坐标预测。在YOLO的tiny版本中为了速度的提升,自然也减少了卷积层(9层)的数量以及滤波器的数量。

2.2 网络训练
在ImageNet的1000类数据集上完成卷积层的预训练任务,并取得了top-5 88%的准确率。之后论文将分类模型转换为检测模型。对预训练增加网络的卷积与全连接层会使得网络的性能提升,为此论文中增加了4个卷积与2个全连接层,同时为了更好的检测视觉信息,将输入图像的尺寸从224*224提升到448*448。最后网络输出的是目标类别的概率以及边界框的坐标。
使用该激活函数作为网络的激活函数:
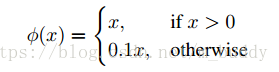
论文使用平方损失函数,该损失函数方便进行优化。但是,它并不是与论文的目标相匹配。平方损失函数中定位错误与分类错误的权重是相同的。但是考虑到在图像中的许多单元格中是没有目标的,因而这些单元格对应的边界框置信度就是0,这将会将覆盖包含了变目标单元格的梯度。进而会导致网络稳定以及训练发散。
为了解决该问题,论文增加边界框定位精度的损失,减少边界框没有包含物体置信度的损失。使用两个参数 、 。
平方损失函数对于大边界框与小边界框错误的权重也是相同的。论文的误差度量应该反映出大盒子里的小偏差比小盒子里的小偏差更重要。为了部分解决这个问题,论文中预测边界框宽度和高度的平方根,而不是直接预测宽度和高度。
YOLO预测每个网格单元有多个边界框。在训练时,我们只需要一个边界框预测器来负责每个对象。我们指定一个预测器来“负责”预测一个对象,该对象基于哪个预测具有最高的当前IOU与Ground Truth。这导致了边界框之间的特化。每个预测器都能更好地预测特定的大小、纵横比或对象的类别,从而提高整体的回忆能力。
根据上面的内容因而将网络的损失函数定义为:
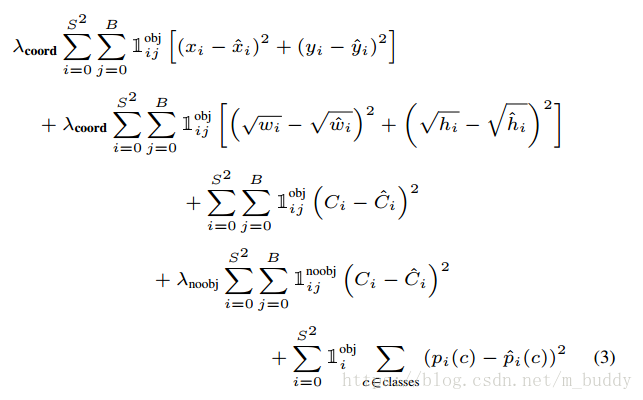
前面两行是对空间位置的惩罚,接下来的两行是对是否是包含目标的惩罚,最后一项便是对分类概率的惩罚。
损失函数只惩罚在网格单元中存在对象的分类错误(因此前面讨论的条件类概率)。如果预测器对ground truth负责(即在网格单元中有最高的IOU),它也只能惩罚边界框坐标误差。
在训练的第一次迭代中缓慢将学习率从
提升到
,之后迭代75个周期,之后
迭代30个周期,最后
迭代30个周期。
为了避免过度拟合,论文使用drop和广泛的数据增强。第一个全连接层之后加入rate=0.5的drop_out层。为了增强数据,论文引入了高达20%原始图像大小的随机缩放和平移。论文还在HSV颜色空间中随机调整图像的曝光和饱和度,调整到1.5倍。
2.3 推论
网格设计在边界框预测中强制空间多样性。通常,一个对象落在哪个网格单元格上是很清楚的,而且网络仅为每个对象预测一个框。但是,一些大的对象或多单元边界附近的对象可以被多个单元很好地定位。非最大抑制可用于修复这些多检测。非最大抑制在mAP中增加了2- 3%。
2.4 YOLO的不足
YOLO对边界框预测施加了强烈的空间约束,因为每个网格单元格只能预测两个框,并且只能有一个类。这种空间约束限制了我们的模型能够预测的附近对象的数量。我们的模型在处理以群体形式出现的小物体时遇到了困难,比如成群的鸟。
由于我们的模型学会了从数据中预测边界框,所以它很难推广到新的或不常见的纵横比或配置对象。我们的模型还使用了相对粗糙的特性来预测边框,因为我们的架构有多个从输入图像向下采样的层。
最后,当我们训练一个近似检测性能的损失函数时,我们的损失函数处理小边界框和大边界框中的错误是一样的。大边界框里的小错误通常是良性的,但小边界框里的小错误对借据的影响要大得多。错误的主要来源是不正确的定位。
3. 实验
这里将YOLO与Fast R-CNN进行比较,主要从
(1)正确:正确的分类且
;
(2)定位:正确分类,
(3)相似:分类相似且
(4)其它:分类错误,
(5)背景:对于任意其它目标,
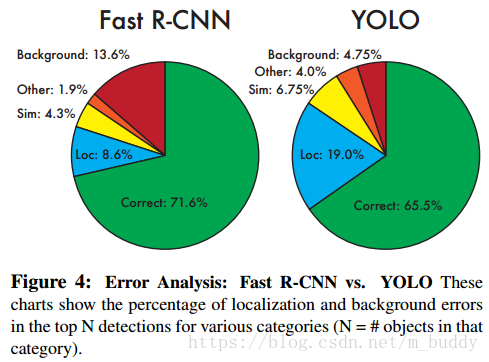
YOLO很难正确定位对象。定位错误占YOLO错误的比例超过了所有其他源的总和。快速R-CNN的定位误差要小得多,但背景误差要大得多。13.6%的检测结果是假阳性,不包含任何对象。与YOLO相比,快速R-CNN预测背景的可能性几乎是前者的3倍。