前言
今天开始,要进行代码的学习,先将训练自监督网络的代码跑起来。
1. 数据集:
-
数据的获取
Potsdam数据集下载链接
百度网盘提取码:lala
Vaihingen数据集下载链接
百度网盘提取码:lala
Toronto数据集下载链接
百度网盘提取码:lala -
数据集的介绍
上述的数据详细介绍请大家移步至对应官网进行查看,其中有对应数据集的详细介绍
数据集的官网 -
数据集的处理
点击链接下载数据集处理源码 -
处理之后的数据集下载
百度网盘提取码:lala
2.网络训练
作者提供的帮助文档中所给的命令是错误的,要用下面的这个:
python main_ss.py --root=./data_example/Potsdam --ex_mode=1 --self_mode=1 --self_max_epoch=400 --ft_max_epoch=150 --self_data_name=train --ft_train_name=trainR1
训练的前期准备:
1.数据集
- 训练所使用的训练集为RGBIR模式的tif图片,其中RGB是颜色模式,分别代表Red, Green, Blue,是最广泛应用的色彩模式。IR是Infrared,即红外线,其波长(约760nm~1mm)比红光长,是不可见光。是一种四通道的图片。
- 数据集中的图片是大图,要拆分之后才能用。代码如下:
import os
from skimage import io
def division(folder_in, folder_out, split_size=256):
for tif_nanme in os.listdir(folder_in):
imgPath = folder_in +'\\' +tif_nanme
tif = io.imread(imgPath) # 读取RGB原图像
for i in range(int(tif.shape[0] /split_size)):
for j in range(int(tif.shape[1] /split_size)):
if tif.shape[-1]<=4: # 处理多通道图片
img = tif[split_size * i: split_size * (i + 1), split_size * j: split_size * (j + 1), :]
else: # 处理单通道图片
img = tif[split_size * i: split_size * (i + 1), split_size * j: split_size * (j + 1)]
name = i * int(tif.shape[0] /split_size) + j
# 让RGB图像和标签图像的文件名对应
name_Path = folder_out + tif_nanme[:-4] + str(name) + '.tif'
io.imsave(name_Path, img, check_contrast=False)
division(folder_in=r'D:\dataset\image',
folder_out=r'./dataset/images/',
split_size=256)
division(folder_in=r'D:\dataset\label',
folder_out=r'./dataset/labels/',
split_size=256)
2. 数据集索引文件生成
数据集目录结构如下:
- train_lbl: 训练集标签图片
- train_RGBIR: 训练集图片
- val_lbl, val_RGBIR: 测试集的标签和图片
- class_dict.txt: 元素种类信息
- train_RGBIR: 训练集图片名(用于自监督训练)
- trainR1_lbl.txt,trainR1_RGBIR.txt:训练集图片名(用于对比训练-微调)
- val_lbl.txt, val_RGBIR.txt: 测试集的标签名和图片名
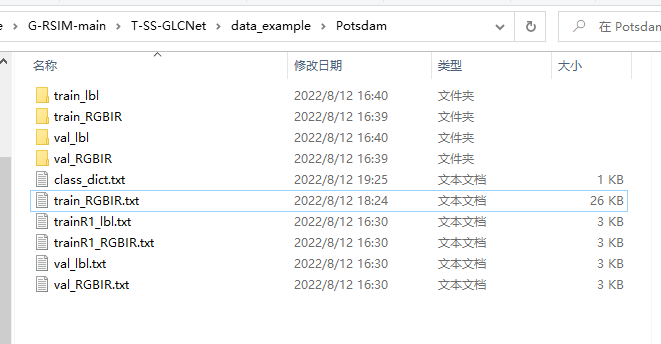
准备好了训练所需要的图片后,现在开始生成用来索引图片的txt文件。代码如下:
def OutName_TXT(root_path='D:\\BaiduNetdiskDownload\\ISPRS-data-preprocessing\\Potsdam',
datasets_name={
'train': 13800, 'trainR1': 138, 'val': 1000}):
for k, i in datasets_name.items():
b = 0
id_list = os.listdir(root_path)
random.shuffle(id_list)
f = open(k + '_RGBIR.txt', "w+")
f1 = open(k + '_lbl.txt', "w+")
for j in id_list[b:b+i]:
f.write(j + "\n")
f1.write(j + "\n")
f.close()
f1.close()
print("Success crated {0}_lbl.txt and {0}_RGBIR.txt!".format(k))
OutName_TXT(root_path='D:\\BaiduNetdiskDownload\\ISPRS-data-preprocessing\\Potsdam\\images',
datasets_name={
'train': 13800, 'trainR1': 138, 'val': 1000})
# val为文件名字,100是训练集图片个数,是在训练集中随机抽取的
3. 开始训练
点击 “运行->编辑配置”,将运行所需的参数加入
–root=./data_example/Potsdam
–ex_mode=1
–self_mode=1
–self_max_epoch=400
–ft_max_epoch=150
–self_data_name=train
–ft_train_name=trainR1
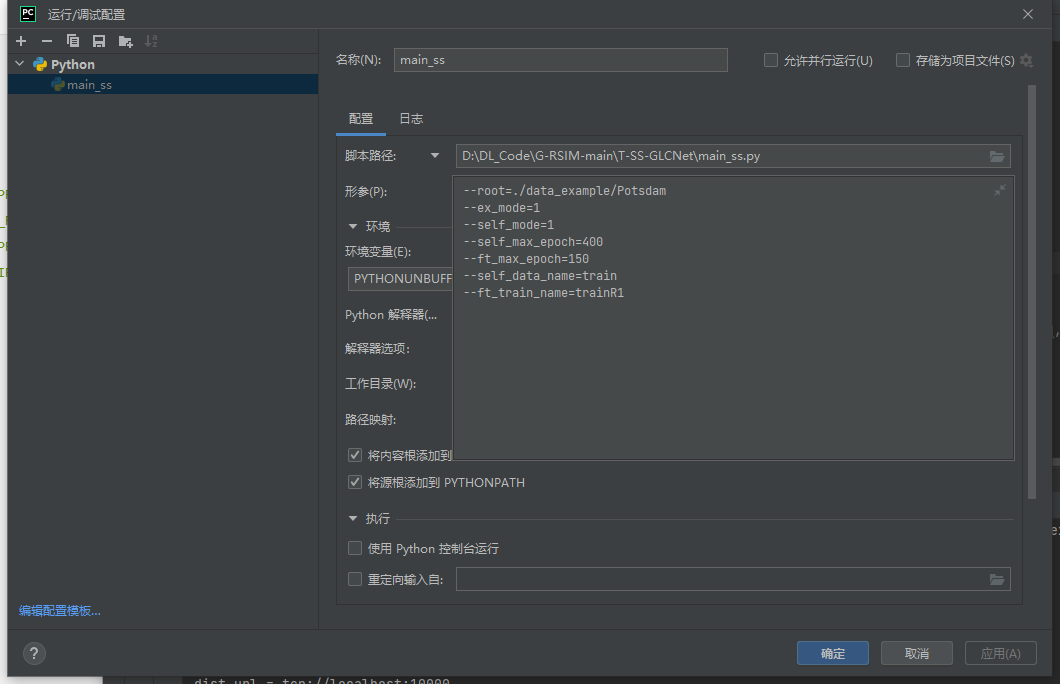
配置好后,就可以进行运行和调试啦。