| 在Linux下安装最新版本的Solr5.3.1并配置IK中文分词 一、首先安装Solr5.3.1从5.0开始,Solr不再需要单独的发布为任何Servlet容器打包的WAR包,Solr运行在自己的Servlet的容器里。 1、首先需要JDK版本最低为1.7,请使用 #java --version 注意,linux默认自带的Open JDK可能不被支持,所以请尽量使用官方版本的JDK 2、 获取Solr5.3.1的安装包 #wget http://mirror.bit.edu.cn/apache/lucene/solr/5.3.1/solr-5.3.1.tgz #tar zxvf solr-5.3.1.taz 3、创建应用程序和数据目录 #mkdir -p /data/solr /usr/local/solr 4、创建运行solr的用户并赋权 #groupadd solr #useradd -g solr solr #chown -R solr.solr /data/solr /usr/local/solr 5、安装solr服务为自启动 #solr-5.3.1/bin/install_solr_service.sh solr-5.3.1.tgz -d /data/solr -i /usr/local/solr 6、安装完成后,命令行输出为: Solr process 29692 running on port 8983
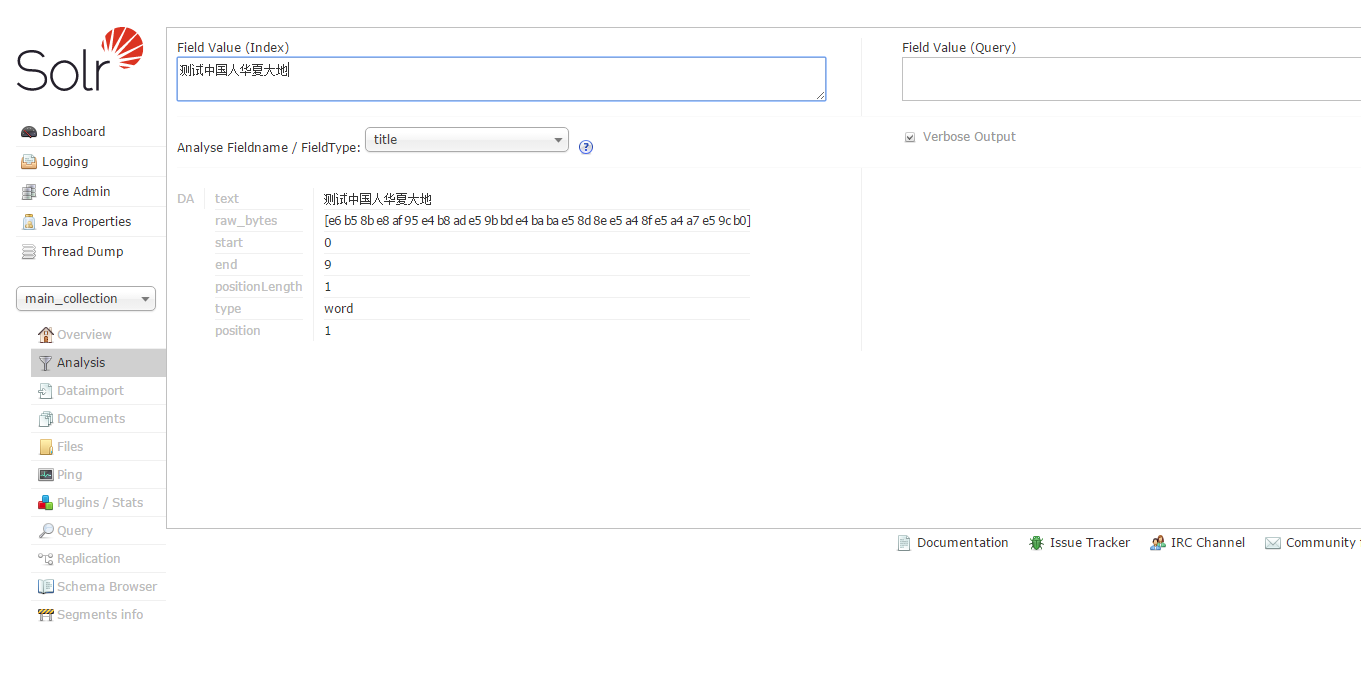
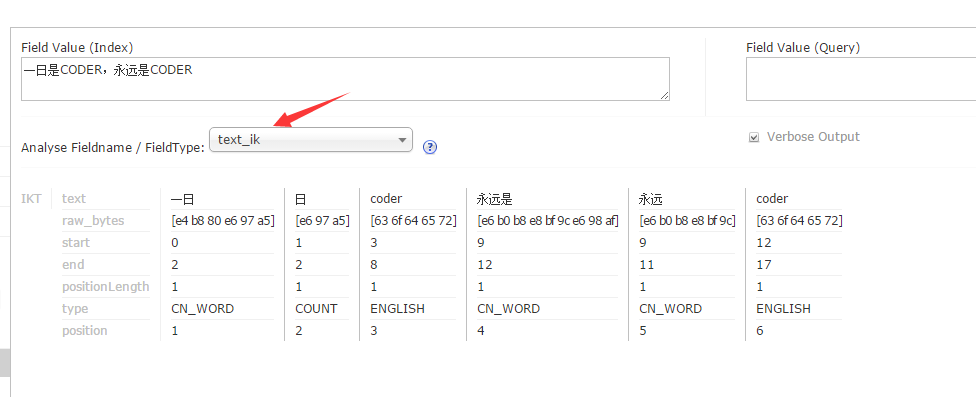
# su solr -c "/usr/local/solr/solr/bin/solr create -c gettingstarted -n data_driven_schema_configs" 其中的 gettingstarted 即为新添加的Solr Core,data_driven_schema_configs是初始化Core的配置文件,可是尝试先手工post一个文档进去: 5、 进入配置目录 <fieldType name="text_ik" class="solr.TextField"> <analyzer type="index" useSmart="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/> <analyzer type="query" useSmart="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType>
|
在Linux下安装最新版本的Solr5.3.1并配置IK中文分词

猜你喜欢
转载自blog.csdn.net/blackhost/article/details/84645506
今日推荐
周排行