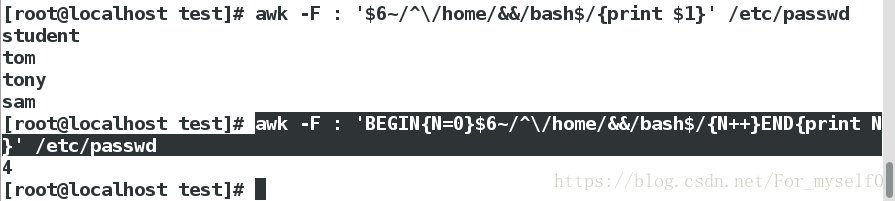
一、grep
1.grep概述
文本过滤命令:grep是一种文本搜索工具,根据用户指定的“模式”对目标文本进行匹配检查,打印匹配到的行;
grep:由正则表达式或者字符及基本文本字符所编写的过滤条件;
2.grep匹配字符
- E ##扩展正则表达式
grep root passwd ##模糊过滤root字符
grep -E "\<root" passwd ##模糊过滤以root开头的字符
grep -E "\<root\>" passwd ##精确过滤以root字符

grep -E -i "\<root\>" passwd ##忽略大小写过滤root字符
grep -E -i "^\<root\>" passwd ##忽略大小写过滤以root字符开头的行
grep -E -i "\<root\>$" passwd ##忽略大小写过滤以root字符结尾的行
grep -E "root|ROOT" passwd ##模糊过滤root和ROOT字符
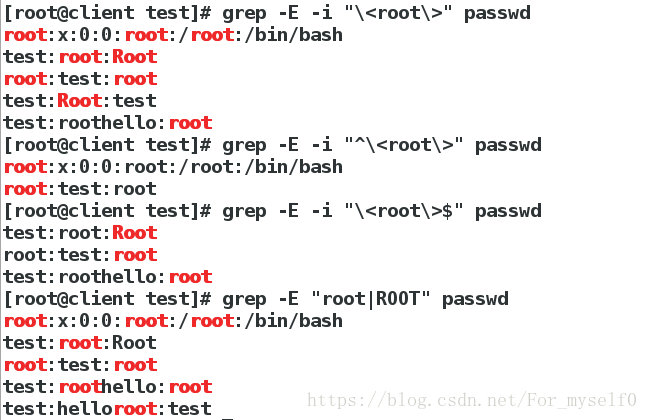
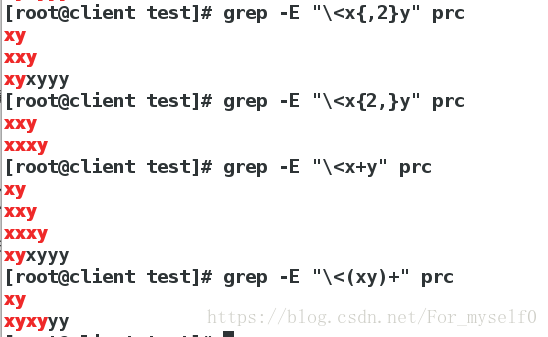
3.grep匹配字符出现次数
grep -E "x.." prc ##x后至少2个字符
grep -E "x..\>" prc ##x后2个字符结尾
grep -E "x..y\>" prc ##x..y结尾
grep -E "\<x..y\>" prc ##x开头,2个字符,y结尾

grep -E "x*y" prc ##xy之间x出现任意次
grep -E "x?y" prc ##xy之间x出现0-1次

grep -E "\<x{ ,2}y" prc ##以x开头,xy之间x最多出现2次
grep -E "\<x{2, }y" prc ##以x开头,xy之间x最少出现2次
grep -E "\<x+y" prc ##xy之间x最少出现1次
grep -E "\<(xy)+" prc ##以xy开头,xy字符最少出现1次
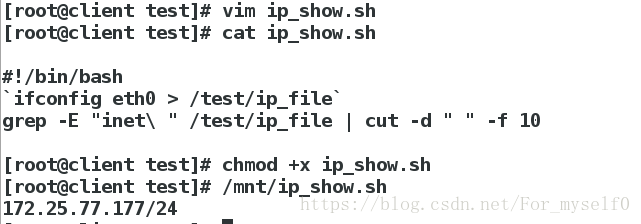
4.用grep编辑脚本ip_show.sh
二、sed
1.sed概述
行编辑器:用来操作纯ASCII码的文本
原理:处理时,把当前处理的行存储在“模式空间”(临时缓冲区),符合模式条件的处理,不符合条件的不处理,处理完成后把缓冲区内容送往屏幕;接着处理下一行,不断重复,直至文件结束;
2.p模式(显示)
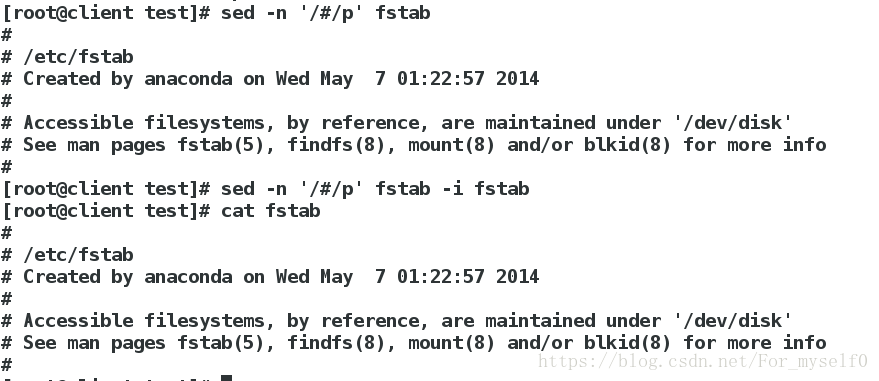
sed -n '/#/p' fstab ##显示文件带#的行
sed -n '/#/p' fstab -i fstab ##将显示结果覆盖掉原文件
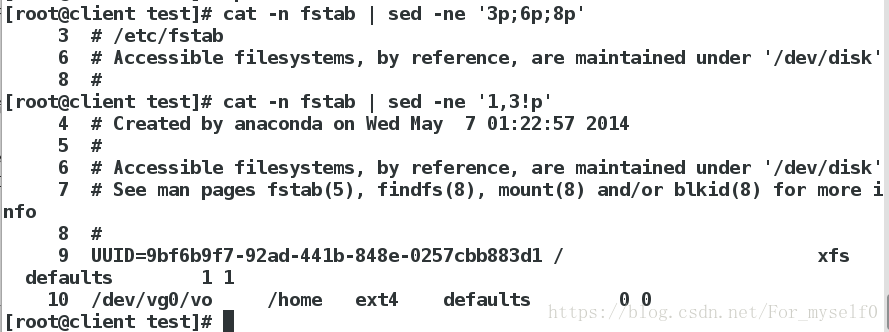
cat -n fstab | sed -ne '3p;6p;8p' ##显示文件的3,6,8行
cat -n fstab | sed -ne '1,3!p' ##不显示文件的1-3行
3.d模式(删除)
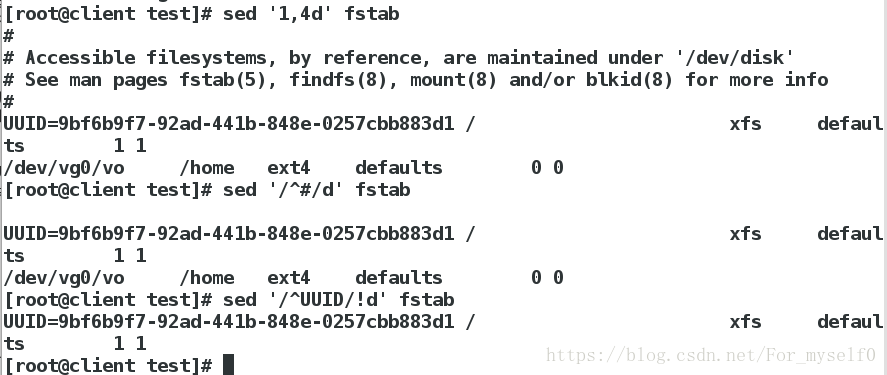
sed '1,4d' fstab ##删除文件的1、4行
sed '/^#/d' fstab ##删除文件以#开头的行
sed '/^UUID/!d' fstab ##除了以UUID开头的行都删除
4.a模式(插入)
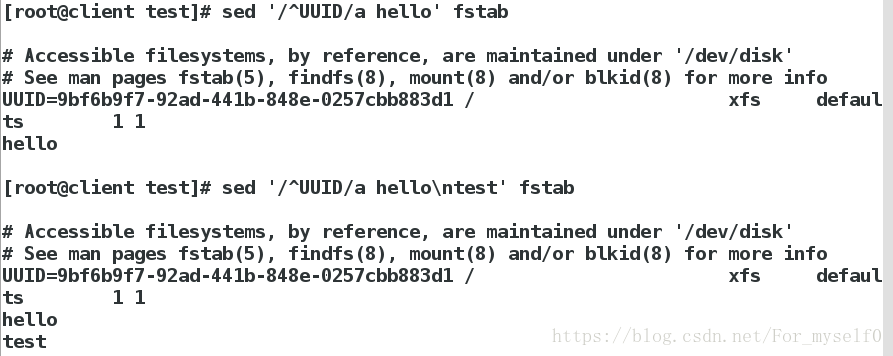
sed '/^UUID/a hello' fstab ##在以UUID开头的那一行后插入hello行
sed '/^UUID/a hello\ntest' fstab ##在以UUID开头的那一行后插入2行
5.i模式(插入)
sed '/^UUID/i hello' fstab ##在以UUID开头的那一行前插入hello行
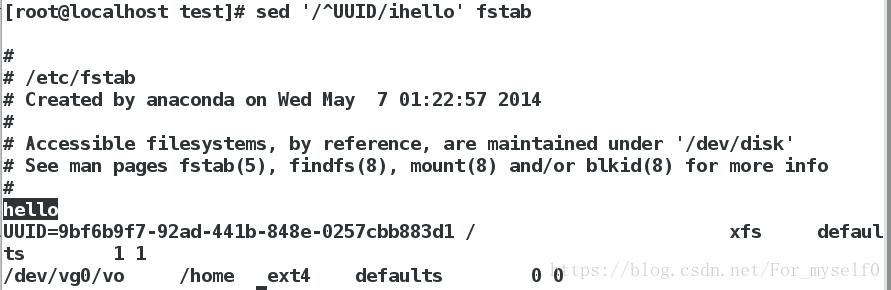
6.c模式(替换)
sed '/^UUID/c hello' fstab ##将以UUID开头的那一行替换成hello行
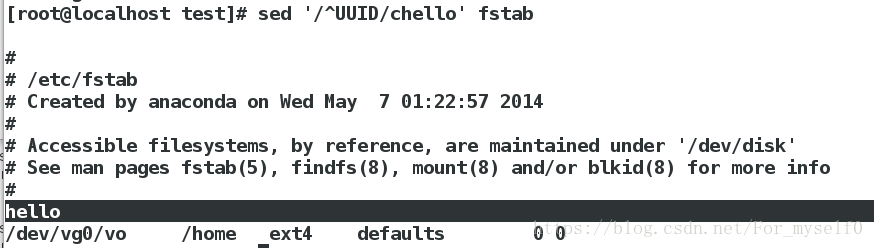
###编写脚本,改变http服务的接口###
脚本内容如下:

验证脚本:
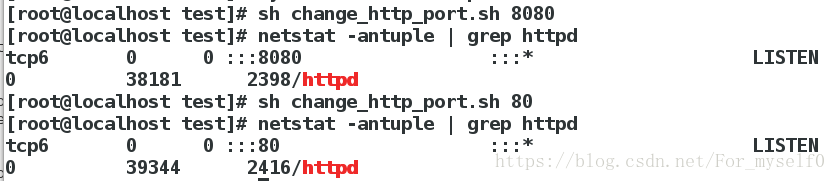
7.w模式(写入)
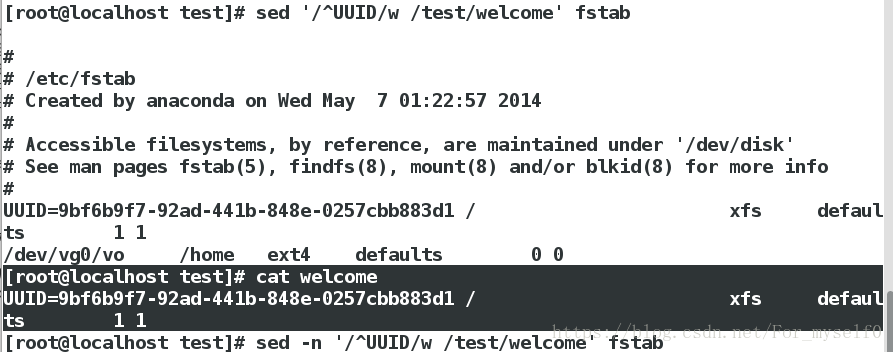
sed '/^UUID/w /mnt/test' fstab ##将文件fstab以UUID开头的那一行写入/mnt/test
sed -n '/^UUID/w /mnt/test' fstab ##同上,但是不输出结果
sed '/^UUID/=' fstab ##将文件fstab以UUID开头的行号输出
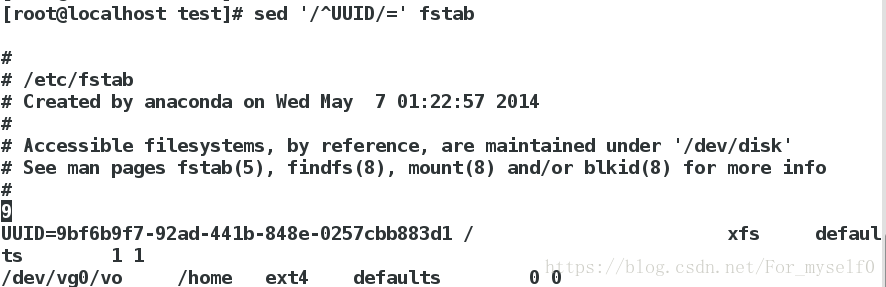
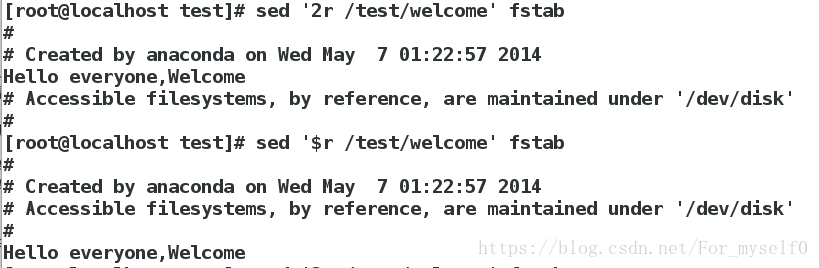
sed '2r /mnt/hello' fstab ##将/mnt/hello文件写入fstab的第2行后
sed '$r /mnt/hello' fstab ##将/mnt/hello文件写入fstab的最后1行
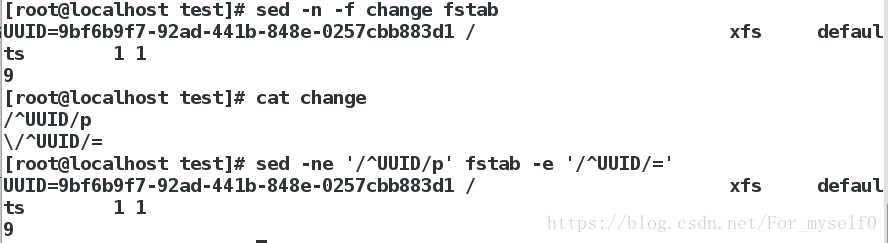
8.其他参数 (-n:只显示匹配空间的内容)
sed -n -f change fstab ##对fstab执行change的策略
sed -n -e '/^UUID/p' fstab -e '/^UUID/=' ##同上,跟change策略有关
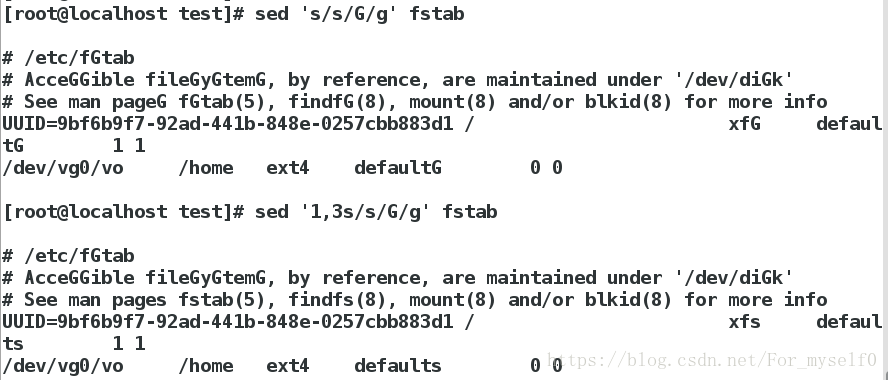
sed 's/s/G/g' fstab ##将fstab全文的s替换成S
sed '1,3s/s/S/g' fstab ##将fstab前3行的s替换成S
sed '/are/,/man/s/e/\#/g' fstab ##将fstab字符by与man之间行的e替换成#
sed 's@s@S@g' fstab ##@与/意义相同

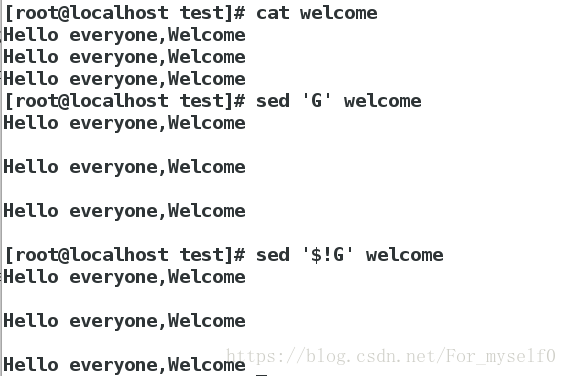
sed 'G' hello ##在hello文件的每行后插入空行
sed '$!G' hello ##除了最后1行,每行后插入空行
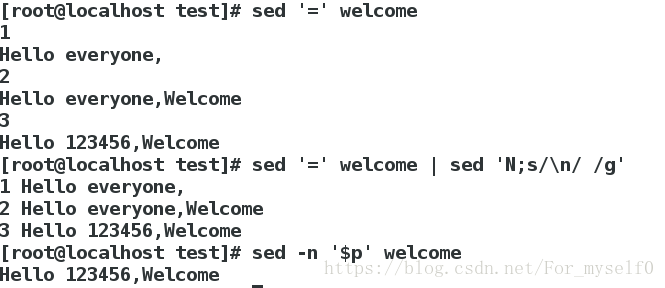
sed '=' hello ##显示行号
sed '=' hello | sed 'N;s/\n/ /g'
sed -n '$p' hello ##只打印hello的最后1行
三、awk
1.awk概述
awk处理机制:逐行处理文本,支持在处理第一行之前做一些准备工作,以及在处理完最后一行做一些总结性质的工作
2.awk参数
awk -F : 'BEGIN{print "NAME"}{print $1}' passwd
##以:为分隔符,处理前打印 NAME ,打印第1列
awk -F : 'BEGIN{print "NAME"}{print $1}END{print NR}' passwd
##以:为分隔符,处理前打印 NAME ,打印第1列,处理后打印行数(NF列)

awk -F : '/bash$/{print $7}' passwd
##以:为分隔符,打印以bash结尾行的第7列
awk -F : '/bash$/' passwd
##以:为分隔符,打印以bash结尾行

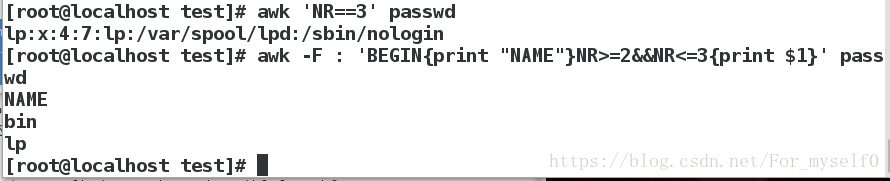
awk -F : 'NR==3' passwd
##以:为分隔符,打印第3行
awk -F : 'BEGIN{print "NAME"}NR<=3&&NR>=2{print $1}' passwd
##以:为分隔符,处理前打印 NAME ,打印2-3行的第1个字符
练习:
1.打印能登陆系统且家目录是/home的用户个数