文章目录
【小样本分割 2020 ICCV】PANet
论文题目:PANet: Few-Shot Image Semantic Segmentation with Prototype Alignment
中文题目:PANet:基于原型对齐的小样本图像语义分割
论文链接:https://arxiv.org/abs/1908.06391v2
论文代码:https://github.com/kaixin96/PANet
论文团队:新加坡国立大学
发表时间:2019年8月
DOI:
引用:Wang K, Liew J H, Zou Y, et al. Panet: Few-shot image semantic segmentation with prototype alignment[C]//proceedings of the IEEE/CVF international conference on computer vision. 2019: 9197-9206.
引用数:584(截止时间:2023年4月24号)
1. 简介
本文从度量学习的角度来解决小样本分割问题,提出一种新的原型对齐网络来更好地利用支持集信息。
PANet从嵌入空间内的一些支持图像中学习特定类的原型表示,然后通过将每个像素与学习到的原型进行匹配,对查询图像进行分割。
通过非参数度量学习,PANet提供了代表每个语义类的高质量原型,这些原型同时还存在对不同类的判别信息。此外,PANet还引入了一种支持和查询之间的原型对齐正则化。在此基础上,PANet充分利用了来自支持的知识,在少镜头分割中提供了更好的泛化。
目前存在的问题和方案
现有的小样本分割方法通常从少量的支持图像中学习,然后将学习到的知识输入到参数化模块中进行查询分割。然而,这类方案存在两个缺点,推广效果不理想。
- 首先,它们
没有区分知识提取和分割过程,这可能会有问题,因为分割模型的表示与支持集的语义特征混合。因此,我们建议将这部分分为原型提取和非参数度量学习两部分。原型被优化为每个语义类的紧凑和鲁棒表示,非参数度量学习通过嵌入空间中的像素级匹配进行分割。 - 此外,我们不像以前的方法一样使只使用支持图像的标注做masking,我们将
这些标注加入了小样本学习的监督过程。为此,我们引入了一种新的原型对齐正则化方法,这是一种反向分割方法。即将查询图像及其预测掩码作为一种新的支持集,用于对之前的支持图像进行分割。通过这种方式,鼓励模型在支持和查询之间生成更一致的原型,从而提供更好的泛化性能

2. 网络
2.1 整体架构
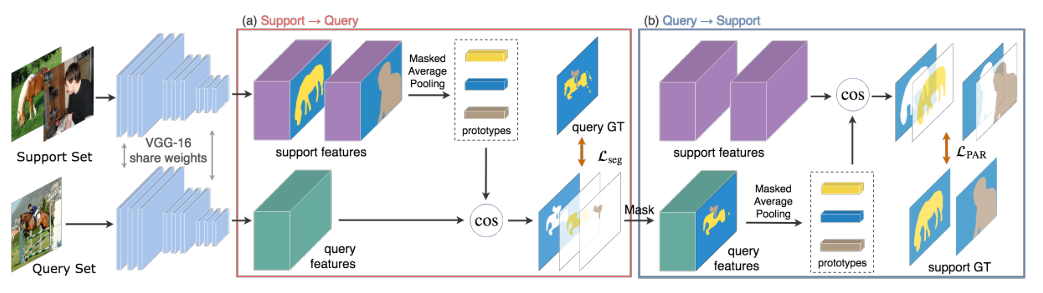
现有的小样本分割方法将提取的支持特征与查询特征融合,以参数化的方式生成分割结果,我们提出的模型旨在在嵌入空间中学习并对齐每个语义类的紧凑和健壮的原型表示,然后通过非参数度量学习在嵌入空间内进行分割。
PANet首先通过共享的特征提取器将不同的前景对象和背景嵌入到不同的原型中。这样,每一个学习到的原型都是对应类的代表,同时也有足够区别于其它类。然后,将查询图像中的每个像素标记为这个像素的嵌入表示离它最近的类特定原型。
所提出的PANet结构设计有几个优点。
- 首先,它不引入额外的可学习参数,因此不容易过度拟合。
- 其次,在PANet中,原型嵌入和预测在计算的特征图上执行,因此分割不需要额外通过网络。
- 此外,由于正则化仅用于训练,因此不会增加推理的计算成本。
2.2 原型学习
我们的模型基于度量网络,能够有效地学习每个语义类易于分离的原型表示。
PANet不是对整个输入图像进行平均,而是利用支持图像上的掩码注释来分别学习前景和背景原型。
有两种方法来利用分割掩码,前期融合和后期融合,本文采取的是后期融合,也就是将mask盖在特征图上以产生前景和背景特征(而不是在输入特征提取器前进行融合),这样做有利于保持共享特征提取器的输入一致性。
具体来说,给定一个支持集 S i = { ( I c , k , M c , k ) } \mathcal{S}_{i}=\{(I_{c,k},M_{c,k})\} Si={(Ic,k,Mc,k)}, F c , k F_{c,k} Fc,k表示图像 I c , k I_{c,k} Ic,k经过特征提取后得到的特征图。 c c c表示类别, k k k则表示支持图像序号,类 c c c的原型通过掩码平均池化得到:
p c = 1 K ∑ k ∑ x , y F c , k ( x , y ) 1 [ M c , k ( x , y ) = c ] ∑ x , y 1 [ M c , k ( x , y ) = c ] , p_c=\dfrac{1}{K}\sum_k\dfrac{\sum_{x,y}F_{c,k}^{(x,y)}\mathbb{1}[M_{c,k}^{(x,y)}=c]}{\sum_{x,y}\mathbb{1}[M_{c,k}^{(x,y)}=c]}, pc=K1k∑∑x,y1[Mc,k(x,y)=c]∑x,yFc,k(x,y)1[Mc,k(x,y)=c],
背景类的原型则可表示为:
p b g = 1 C K ∑ c , k ∑ x , y F c , k ( x , y ) 1 [ M c , k ( x , y ) ∉ C i ] ∑ x , y 1 [ M c , k ( x , y ) ∉ C i ] . p_{\mathrm{bg}}=\dfrac{1}{CK}\sum_{c,k}\dfrac{\sum_{x,y}F_{c,k}^{(x,y)}\mathbf{1}[M_{c,k}^{(x,y)}\notin\mathcal{C}_i]}{\sum_{x,y}\mathbf{1}[M_{c,k}^{(x,y)}\notin\mathcal{C}_i]}. pbg=CK1c,k∑∑x,y1[Mc,k(x,y)∈/Ci]∑x,yFc,k(x,y)1[Mc,k(x,y)∈/Ci].
( x , y ) (x,y) (x,y)表示位置,1表示框内式子为真则值为1,假为0
2.3 非参数度量学习
我们采用非参数度量学习方法来学习最优的原型并进行相应的分割。由于分割可以看作是在每个空间位置的分类,我们计算查询图像在每个空间位置上的特征向量与支持图像原型之间的距离。然后在距离上使用softmax得到语义类(包括背景)的概率映射 M ~ q \tilde{M}_{q} M~q
具体来说,给定一个距离函数 d d d,让 P = { p c ∣ c ∈ C i } ∪ { p b g } \mathcal{P}=\{p_{c}|c\in\mathcal{C}_{i}\}\cup\{p_{\mathrm{bg}}\} P={
pc∣c∈Ci}∪{
pbg}和 F q F_q Fq 表示查询图像特征映射。
M ~ q ; j ( x , y ) = exp ( − α d ( F q ( x , y ) , p j ) ) ∑ p j ∈ P exp ( − α d ( F q ( x , y ) , p j ) ) . \tilde{M}_{q;j}^{(x,y)}=\frac{\exp(-\alpha d(F_{q}^{(x,y)},p_{j}))}{\sum_{p_{j}\in\mathcal{P}}\exp(-\alpha d(F_{q}^{(x,y)},p_{j}))}. M~q;j(x,y)=∑pj∈Pexp(−αd(Fq(x,y),pj))exp(−αd(Fq(x,y),pj)).
距离函数 d d d一般采用余弦距离或平方欧几里得距离,根据经验,我们发现使用余弦距离更稳定,性能更好,可能是因为它是有界的,因此更容易优化。
然后,预测的分割掩码由下式给出:
M ~ q ( x , y ) = arg j max M ~ q ; j ( x , y ) . \tilde{M}_q^{(x,y)}=\arg\limits_j\max\tilde{M}_{q;j}^{(x,y)}. M~q(x,y)=jargmaxM~q;j(x,y).
分割损失的表达如下:
L s e g = − 1 N ∑ x , y ∑ p j ∈ P 1 [ M q ( x , y ) = j ] log M ~ q ; j ( x , y ) , \mathcal{L}_{\mathrm{seg}}=-\frac{1}{N}\sum_{x,y}\sum_{p_j\in\mathcal{P}}1[M_q^{(x,y)}=j]\log\tilde{M}_{q;j}^{(x,y)}, Lseg=−N1x,y∑pj∈P∑1[Mq(x,y)=j]logM~q;j(x,y),
M q M_q Mq表示查询图像的ground-truth分割掩码,N表示所有空间位置数量,对上述损失进行优化将为每个类派生出合适的原型。
2.4 原型对齐正则化
直觉上来说,如果模型能够使用从支持集中提取的原型来预测出一个好的查询分割掩码,那么这个预测出的查询图像分割掩码应该能够很好地分割支持图像。因此PAR鼓励最终的分割模型反向进行few-shot learning,即以查询和预测的掩码作为新的支持样本来学习分割原始支持图像(也就是这里的查询图像和预测得到的查询图像掩码作为新的支持图像–掩码对)。这将在支持原型和查询图像之间形成对齐,并从支持集中学习到更丰富的知识。
支持图像的分割概率图为
M ~ c , k ; j ( x , y ) = exp ( − α d ( F c , k ( x , y ) , p ˉ j ) ) ∑ p ˉ j ∈ { p ˉ c , p ˉ b g } exp ( − α d ( F c , k ( x , y ) , p ˉ j ) ) , \tilde{M}_{c,k;j}^{(x,y)}=\frac{\exp(-\alpha d(F_{c,k}^{(x,y)},\bar{p}_{j}))}{\sum_{\bar{p}_{j}\in\{\bar{p}_{c},\bar{p}_{b_{g}}\}}\exp(-\alpha d(F_{c,k}^{(x,y)},\bar{p}_{j}))}, M~c,k;j(x,y)=∑pˉj∈{
pˉc,pˉbg}exp(−αd(Fc,k(x,y),pˉj))exp(−αd(Fc,k(x,y),pˉj)),
使用查询图像和其掩码预测支持图像掩码的损失函数如下:
L P A R = − 1 C K N ∑ c , k , x , y ∑ p j ∈ P 1 [ M q ( x , y ) = j ] log M ~ q ; j ( x , y ) . \mathcal{L}_{\mathrm{PAR}}=-\dfrac{1}{CKN}\sum_{c,k,x,y}\sum_{p_j\in\mathcal{P}}1[M_q^{(x,y)}=j]\log\tilde{M}_{q;j}^{(x,y)}. LPAR=−CKN1c,k,x,y∑pj∈P∑1[Mq(x,y)=j]logM~q;j(x,y).
3. 代码
3.1 backbone
import torch
import torch.nn as nn
import torch.nn.functional as F
__all__ = ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101', 'resnet152']
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False, dilation=dilation)
def conv1x1(in_planes, out_planes, stride=1):
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if groups != 1 or base_width != 64:
raise ValueError('BasicBlock only supports groups=1 and base_width=64')
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None, last_relu=True):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
self.last_relu = last_relu
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
if self.last_relu:
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, zero_init_residual=False, groups=1,
width_per_group=64, replace_stride_with_dilation=None, norm_layer=None):
super(ResNet, self).__init__()
self.out_channels = block.expansion * 256
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 128
self.dilation = 1
if replace_stride_with_dilation is None:
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Sequential(
conv3x3(3, 64, stride=2),
norm_layer(64),
nn.ReLU(inplace=True),
conv3x3(64, 64),
norm_layer(64),
nn.ReLU(inplace=True),
conv3x3(64, 128)
)
self.bn1 = norm_layer(128)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1], last_relu=False)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False, last_relu=True):
"""
:param last_relu: in metric learning paradigm, the final relu is removed (last_relu = False)
"""
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = list()
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
use_relu = True if i != blocks - 1 else last_relu
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer, last_relu=use_relu))
return nn.Sequential(*layers)
def base_forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
c1 = self.layer1(x)
c2 = self.layer2(c1)
c3 = self.layer3(c2)
return c3
def _resnet(arch, block, layers, pretrained, **kwargs):
model = ResNet(block, layers, **kwargs)
if pretrained:
state_dict = torch.load(pretrained)
msg=model.load_state_dict(state_dict, strict=False)
print(msg)
return model
def resnet18(pretrained=False):
return _resnet('resnet18', BasicBlock, [2, 2, 2, 2], pretrained)
def resnet34(pretrained=False):
return _resnet('resnet34', BasicBlock, [3, 4, 6, 3], pretrained)
def resnet50(pretrained=False):
return _resnet('resnet50', Bottleneck, [3, 4, 6, 3], pretrained,
replace_stride_with_dilation=[False, True, True])
def resnet101(pretrained=False):
return _resnet('resnet101', Bottleneck, [3, 4, 23, 3], pretrained,
replace_stride_with_dilation=[False, True, True])
def resnet152(pretrained=False):
return _resnet('resnet152', Bottleneck, [3, 8, 36, 3], pretrained,
replace_stride_with_dilation=[False, True, True])
3.2 模型代码
from .resnet import resnet50, resnet101
import torch
from torch import nn
import torch.nn.functional as F
import pdb
class PANet(nn.Module):
def __init__(self, backbone, shot=1, pretrained=True):
super(PANet, self).__init__()
backbone = eval(backbone)(pretrained=pretrained) # 创建backbone-resnet50。backbone 取前几层。
self.layer0 = nn.Sequential(backbone.conv1, backbone.bn1, backbone.relu, backbone.maxpool)
self.layer1, self.layer2, self.layer3 = backbone.layer1, backbone.layer2, backbone.layer3
self.shot = shot
def forward(self, img_s_list, mask_s_list, img_q, mask_q):
"""
Args:
img_s_list: support images
List shape=shot x [batch size,3,473,473]
mask_s_list: masks for support images
List shape=shot x [batch size,473,473]
img_q: query images
[batch_size,3,473,473]
mask_q: query images
[batch_size,473,473]
"""
h, w = img_q.shape[-2:]
# feature maps of support images
feature_s_list = []
# 获取支持集的特征
for k in range(len(img_s_list)):
with torch.no_grad():
s_0 = self.layer0(img_s_list[k])
s_0 = self.layer1(s_0)
s_0 = self.layer2(s_0)
s_0 = self.layer3(s_0)
feature_s_list.append(s_0)
del s_0
# 获取查询集图像的特征
with torch.no_grad():
q_0 = self.layer0(img_q)
q_0 = self.layer1(q_0)
q_0 = self.layer2(q_0)
feature_q = self.layer3(q_0) # [4,1024,60,60]
# foreground(target class) and background prototypes pooled from K support features
feature_fg_list = []
feature_bg_list = []
for k in range(len(img_s_list)):
feature_fg = self.masked_average_pooling(feature_s_list[k], (mask_s_list[k] == 1).float())[None, :] # feature_fg=[1,4,1024]
feature_bg = self.masked_average_pooling(feature_s_list[k], (mask_s_list[k] == 0).float())[None, :] # feature_bg=[1,4,1024]
feature_fg_list.append(feature_fg)
feature_bg_list.append(feature_bg)
# 对shot个图片进行平均,计算原型 [4,1024,1,1]
FP = torch.mean(torch.cat(feature_fg_list, dim=0), dim=0).unsqueeze(-1).unsqueeze(-1)
# 背景原型 [4,1024,1,1]
BP = torch.mean(torch.cat(feature_bg_list, dim=0), dim=0).unsqueeze(-1).unsqueeze(-1)
# 计算查询特征和前景和背景的原型 之间的相似度。计算出初步的分割掩码
out_0 = self.similarity_func(feature_q, FP, BP) # [4,2,60,60]
out_0 = F.interpolate(out_0, size=(h, w), mode="bilinear", align_corners=True) # [4,2,473,473]
# 如果是训练阶段,不需要对齐
# Prototype alignment regularization (PAR) 原型对齐阶段
if self.training:
out_ls = []
# 通过 查询集的输出的特征,根据掩码,输出查询集的前景和背景的原型
fg_q = self.masked_average_pooling(feature_q, (mask_q == 1).float())[None, :].squeeze(0) # [4,1024]
bg_q = self.masked_average_pooling(feature_q, (mask_q == 0).float())[None, :].squeeze(0) # [4,1024]
for i in range(self.shot):
# 根据查询集的原型,计算出支持集的分割图
self_out = self.similarity_func(feature_s_list[i], fg_q[..., None, None], bg_q[..., None, None])
self_out = F.interpolate(self_out, size=(h, w), mode="bilinear", align_corners=True)
out_ls.append(self_out)
return out_0, out_ls
return out_0
def similarity_func(self, feature_q, fg_proto, bg_proto):
"""
通过计算相似度来进行分割
Args:
feature_q: [4,1024,60,60] 查询集特征
fg_proto: [4,1024,1,1] 前景原型
bg_proto: [4,1024,1,1] 背景原型
return: [4,2,60,60] 初步的分割结果
"""
similarity_fg = F.cosine_similarity(feature_q, fg_proto, dim=1)
similarity_bg = F.cosine_similarity(feature_q, bg_proto, dim=1)
out = torch.cat((similarity_bg[:, None, ...], similarity_fg[:, None, ...]), dim=1) * 10.0 # [4,2,60,60]
return out
def masked_average_pooling(self, feature, mask):
"""
通过mask_pool操作获取对应特征的原型。
Args:
feature: [4,1024,60,60]
mask: [4,473,473]
return prototype: [4,1024] 掩码后对应特征的原型
"""
mask = F.interpolate(mask.unsqueeze(1), size=feature.shape[-2:], mode='bilinear', align_corners=True)
masked_feature = torch.sum(feature * mask, dim=(2, 3)) / (mask.sum(dim=(2, 3)) + 1e-5)
return masked_feature
参考资料