文章目录
【语义分割】2021-Segmenter ICCV
论文题目:Segmenter: Transformer for Semantic Segmentation
论文链接: https://arxiv.org/abs/2105.05633v3
论文代码: https://github.com/rstrudel/segmenter
论文翻译:https://blog.csdn.net/qq_42882457/article/details/124385073
发表时间:2021年5月
引用:Strudel R, Garcia R, Laptev I, et al. Segmenter: Transformer for semantic segmentation[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 7262-7272.
引用数:182
1. 简介
1.1 摘要
图像分割在单个图像块的层次上通常是模糊的,需要上下文信息才能达成一致。本文介绍了一种用于语义切分的转换模型 Segmenter。
与基于卷积的方法相比,我们的方法允许在第一层和整个网络中对全局上下文进行建模。我们以最近的视觉转换器(ViT)为基础,将其扩展到语义分割。为此,我们依赖于与图像块对应的输出嵌入,并使用逐点线性解码器或掩码 Transformer 解码器从这些嵌入中获取类标签。
我们利用预先训练的图像分类模型,并表明我们可以在中等大小的数据集上对其进行微调,以进行语义分割。线性解码器已经可以获得很好的结果,但是通过生成类掩码的掩码转换器可以进一步提高性能。我们进行了广泛的消融研究,以显示不同参数的影响,尤其是对于大型模型和小面积贴片,性能更好。Segmenter在语义分割方面取得了很好的效果。它在 Ade20K 和 Pascal 上下文数据集上都优于最先进的技术,在城市景观数据集上具有竞争力
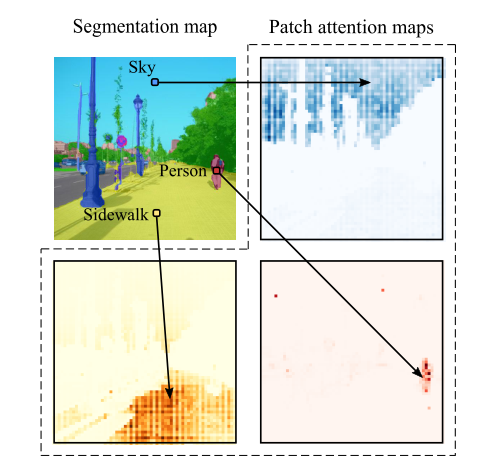
1.2 创新点
1)提出了一种基于 Vision Transformer 的语义分割的新颖方法,该方法不使用卷积,通过设计捕获上下文信息并优于基于 FCN 的方法;
2)提出了一系列具有不同分辨率级别的模型,允许在精度和运行时间之间进行权衡,从最先进的性能到模型具有快速推理和良好性能的模型;
3)提出了一种基于 Transformer 的解码器生成类掩码,其性能优于我们的线性结构,并且可以扩展以执行更一般的图像分割任务;
4)证明了此方法在 ADE20K 和 Pascal Context 数据集上产生了最先进的结果,并且在Cityscapes 上具有竞争力。
2. 网络
2.1 整体架构
Segmenter完全基于transformer的编解码器体系结构,利用了模型每一层的全局图像上下文。
- 基于ViT,将图像分割成块(patches),并将它们映射为一个线性嵌入序列;
- 用编码器进行编码;
- 再由Mask Transformer将编码器和类嵌入的输出进行解码,上采样后应用Argmax给每个像素一一分好类,输出最终的像素分割图。
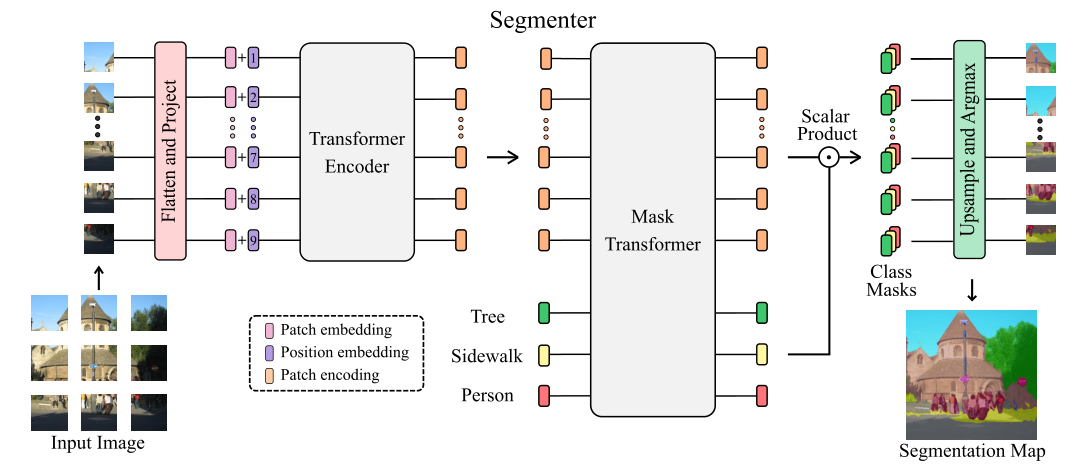
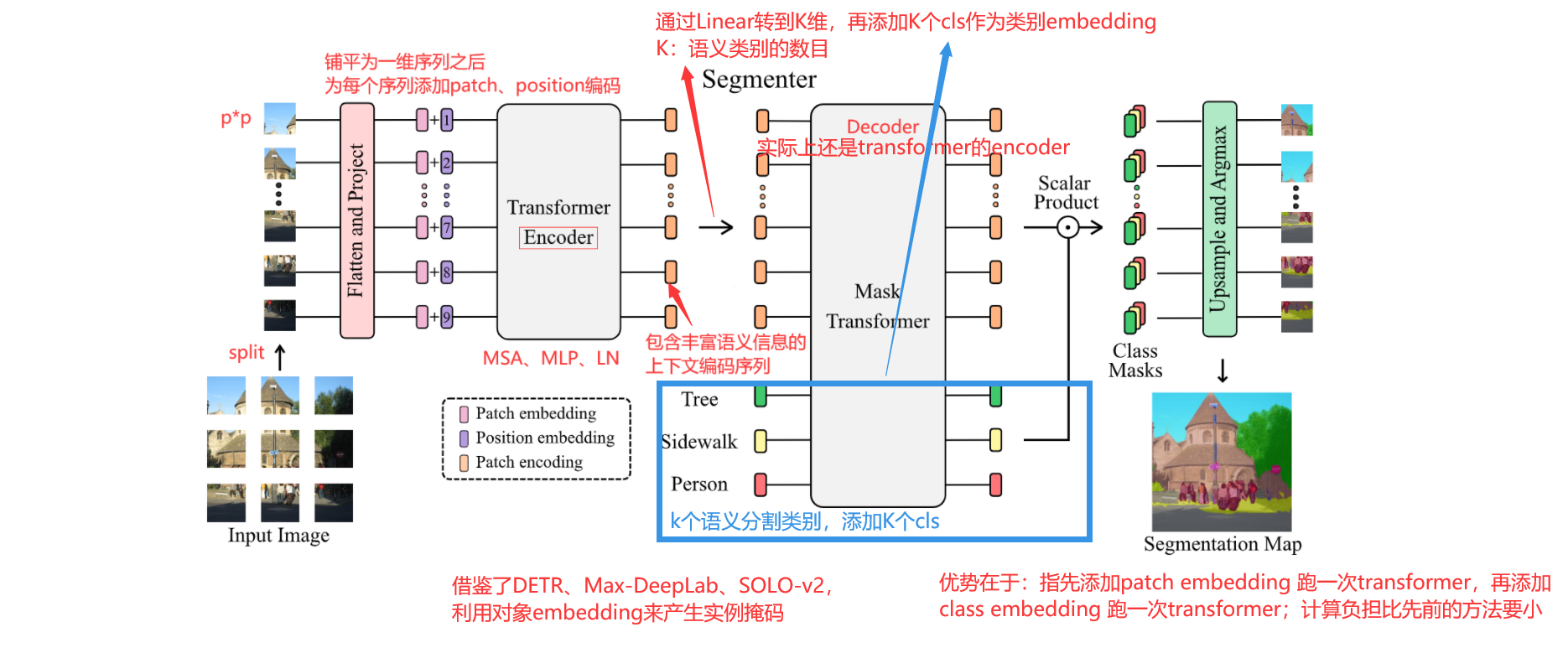
2.2 编码器
- 一个图像 x ∈ R H × W × C x\in R^{H\times W\times C} x∈RH×W×C被分割成一个块序列 x = [ x 1 , … , x N ] ∈ R N × P 2 × C \mathbf{x}=\left[x_{1}, \ldots, x_{N}\right] \in \mathbb{R}^{N \times P^{2} \times C} x=[x1,…,xN]∈RN×P2×C,其中 ( P , P ) (P,P) (P,P)是划分的块的大小, N = H W / P 2 N=H W / P^{2} N=HW/P2是块的数量,C是通道的数量。
- 每个块被压平成一个一维向量,然后线性投影到一个块嵌入,产生一个块嵌入序列 x 0 = [ E x 1 , … , E x N ] ∈ R N × D \mathbf{x}_{\mathbf{0}}=\left[\mathbf{E} x_{1}, \ldots, \mathbf{E} x_{N}\right] \in \mathbb{R}^{N \times D} x0=[Ex1,…,ExN]∈RN×D,其中 E ∈ R D × ( P 2 C ) \mathbf{E} \in \mathbb{R}^{D \times\left(P^{2} C\right)} E∈RD×(P2C)。
- 为了获取位置信息,将可学习的位置嵌入点 p o s = [ pos 1 , … , pos N ] ∈ R N × D \mathbf{p o s}=\left[\operatorname{pos}_{1}, \ldots,\operatorname{pos}_{N}\right] \in \mathbb{R}^{N \times D} pos=[pos1,…,posN]∈RN×D添加到块序列中,得到标记 z 0 = x 0 + p o s \mathbf{z}_{0}=\mathbf{x}_{0}+\mathbf{p o s} z0=x0+pos
- 将由L层组成的transformer编码器应用于标记 z 0 z_0 z0的序列,生成上下文化编码 Z L ∈ R N × D \mathbf{Z}_{L} \in \mathbb{R}^{N \times D} ZL∈RN×D序列。transformer层由一个多头自注意(MSA)块组成,然后是一个由两层组成的点向MLP块组成,在每个块之前应用LayerNorm(LN),在每个块之后添加残差块。
a i − 1 = MSA ( LN ( z i − 1 ) ) + z i − 1 z i = MLP ( LN ( a i − 1 ) ) + a i − 1 \begin{aligned} \mathbf{a}_{\mathbf{i}-1} &=\operatorname{MSA}\left(\operatorname{LN}\left(\mathbf{z}_{\mathbf{i}-1}\right)\right)+\mathbf{z}_{\mathbf{i}-\mathbf{1}} \\ \mathbf{z}_{\mathbf{i}} &=\operatorname{MLP}\left(\operatorname{LN}\left(\mathbf{a}_{\mathbf{i}-\mathbf{1}}\right)\right)+\mathbf{a}_{\mathbf{i}-\mathbf{1}} \end{aligned} ai−1zi=MSA(LN(zi−1))+zi−1=MLP(LN(ai−1))+ai−1
其中, i ∈ { 1 , ⋯ , L } i\in \{1,\cdots,L\} i∈{ 1,⋯,L}。
自注意机制由三个点向线性层映射标记到中间表示, Q ∈ R N × d , K ∈ R N × d , V ∈ R N × d \mathbf{Q} \in \mathbb{R}^{N \times d},\mathbf{K} \in \mathbb{R}^{N \times d},\mathbf{V} \in \mathbb{R}^{N \times d} Q∈RN×d,K∈RN×d,V∈RN×d组成。然后,自我注意的计算方法如下:
MSA ( Q , K , V ) = softmax ( Q K T d ) V \operatorname{MSA}(\mathbf{Q}, \mathbf{K}, \mathbf{V})=\operatorname{softmax}\left(\frac{\mathbf{Q} \mathbf{K}^{T}}{\sqrt{d}}\right) \mathbf{V} MSA(Q,K,V)=softmax(dQKT)V
2.3 解码器
patch encodings Z L ∈ R N × D \mathbf{Z}_{\mathbf{L}} \in \mathbb{R}^{N \times D} ZL∈RN×D被解码为分割映射 s ∈ R H × W × K \mathbf{s} \in \mathbb{R}^{H \times W \times K} s∈RH×W×K,其中 K K K为类别数。
解码器学习将来自编码器的补丁级编码映射到补丁级的类分数。
接下来,这些 patch-level class scores 通过线性插值双线性插值上采样到 pixel-level scores 。我们将在下面描述一个线性解码器,它作为一个基线,而我们的方法是一个掩码转换器,见图2。
Linear
patch encodings( Z L ∈ R N × D \mathbf{Z}_{\mathbf{L}} \in \mathbb{R}^{N \times D} ZL∈RN×D)应用点向线性层,产生块级类对数 Z lin ∈ R N × K \mathbf{Z}_{\operatorname{lin}} \in \mathbb{R}^{N \times K} Zlin∈RN×K,然后将序列重塑为2D特征图 S lin ∈ R H / P × W / P × K \mathbf{S}_{\operatorname{lin}} \in \mathbb{R}^{H / P \times W / P \times K} Slin∈RH/P×W/P×K并提前上采样到原始图像大小 S ∈ R H × W × W \mathbf{S} \in \mathbb{R}^{H \times W \times W} S∈RH×W×W。然后在类维度上应用softmax,得到最终的分割映射。
Mask Transformer
对于基于transformer的解码器,我们引入了一组 K K K个可学习的类嵌入 [ c l s 1 , … , c l s K ] ∈ R K × D \left[\mathrm{cls}_{1}, \ldots, \mathrm{cls}_{K}\right] \in \mathbb{R} ^{K \times D} [cls1,…,clsK]∈RK×D,其中 K K K是类的数量。每个类的嵌入都被随机初始化,并分配给一个语义类。它将用于生成类掩码。类嵌入 c l s cls cls由解码器与补丁编码 z l z_l zl联合处理,如图2所示。
解码器是一个由M层组成的transformer编码器。我们的mask transformer 通过计算解码器输出的 L 2 L_2 L2标准化补丁嵌入 z M ′ ∈ R N × D \mathbf{z}_{\mathbf{M}}^{\prime} \in \mathbb{R}^{N \times D} zM′∈RN×D与类嵌入 c ∈ R K × D \mathbf{c} \in \mathbb{R}^{K \times D} c∈RK×D之间的标量乘积来生成K个掩码。类掩码的集合计算如下:
Masks ( z M ′ , c ) = z M ′ c T \operatorname{Masks}\left(\mathbf{z}_{\mathbf{M}}^{\prime}, \mathbf{c}\right)=\mathbf{z}_{\mathbf{M}}^{\prime} \mathbf{c}^{T} Masks(zM′,c)=zM′cT
其中, Masks ( z M ′ , c ) ∈ R N × K \operatorname{Masks}\left(\mathbf{z}_{\mathbf{M}}^{\prime}, \mathbf{c}\right) \in \mathbb{R}^{N \times K} Masks(zM′,c)∈RN×K是一组块序列。
然后将每个mask序列重塑为二维mask,形成 S m a s k ∈ R H / P × W / P × K \mathbf{S}_{\mathbf{m a s k}} \in \mathbb{R}^{H / P \times W / P \times K} Smask∈RH/P×W/P×K,并提前上采样到原始图像大小,获得特征图 S ∈ R H × W × W \mathbf{S} \in \mathbb{R}^{H \times W \times W} S∈RH×W×W。然后在类维度上应用一个softmax,然后应用一个层范数,得到像素级的类分数,形成最终的分割图。
我们的Mask Transformer受到了DETR[7]、MaxDeepLab[52]和SOLO-v2[55]的启发,它们引入了对象嵌入[7]来生成实例掩码[52,55]。然而,与我们的方法不同的是,MaxDeep-Lab使用了一种基于cnn和transformer的混合方法,并由于计算限制,将像素和类嵌入分割成两个流。使用纯Transformer架构和利用块编码,我们提出了一种简单的方法,在解码阶段联合处理块和类嵌入。这种方法允许产生动态滤波器,随输入而变化。当我们在这项工作中处理语义分割时,我们的Mask Transformer也可以直接适应于通过用对象嵌入替换类嵌入来执行实例分割。
2.4 结果
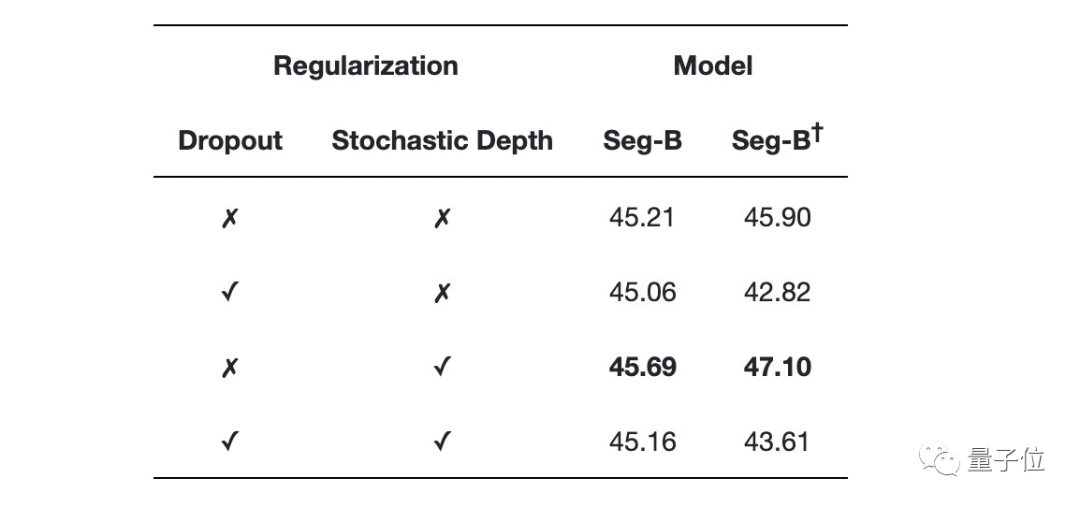
他们发现随机深度(Stochastic Depth)方案可独立提高性能,而dropout无论是单独还是与随机深度相结合,都会损耗性能。
不同图像块大小和不同transformer的性能比较发现:
增加图像块的大小会导致图像的表示更粗糙,但会产生处理速度更快的小序列。
减少图像块大小是一个强大的改进方式,不用引入任何参数!但需要在较长的序列上计算Attention,会增加计算时间和内存占用。
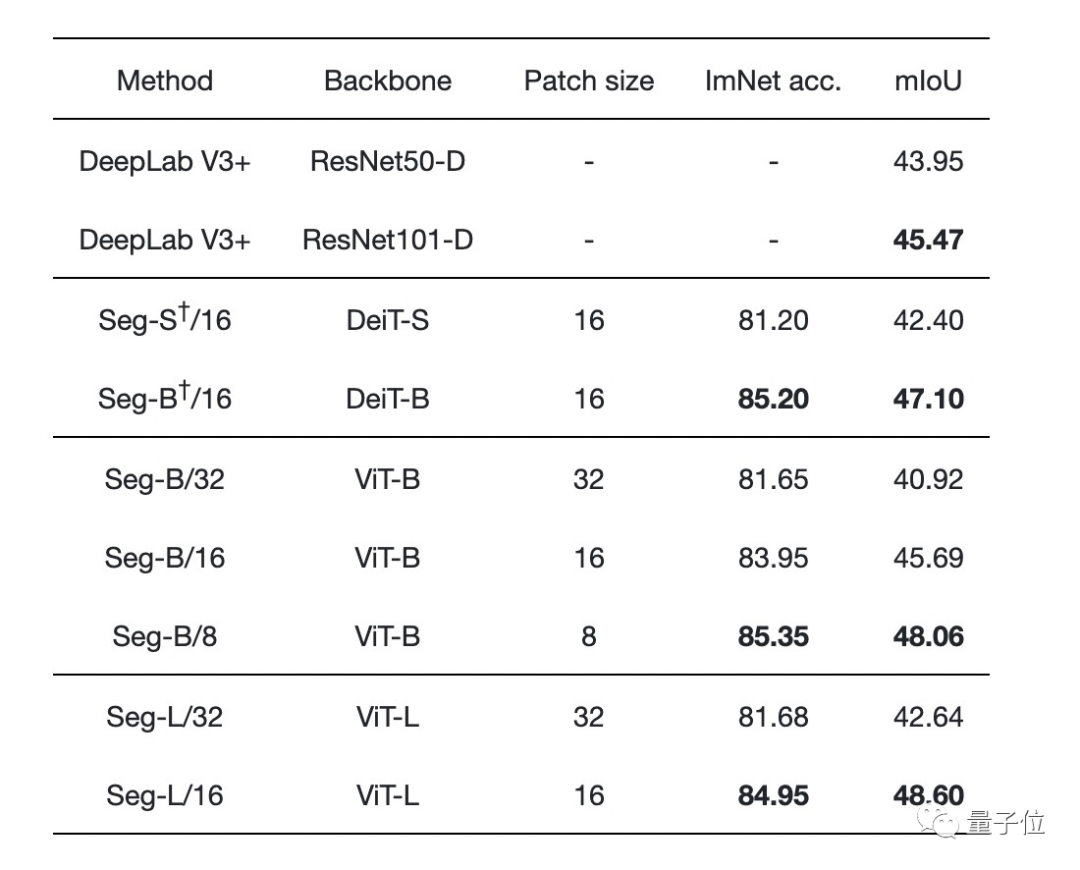
Segmenter在使用大型transformer模型或小规模图像块的情况下更优:
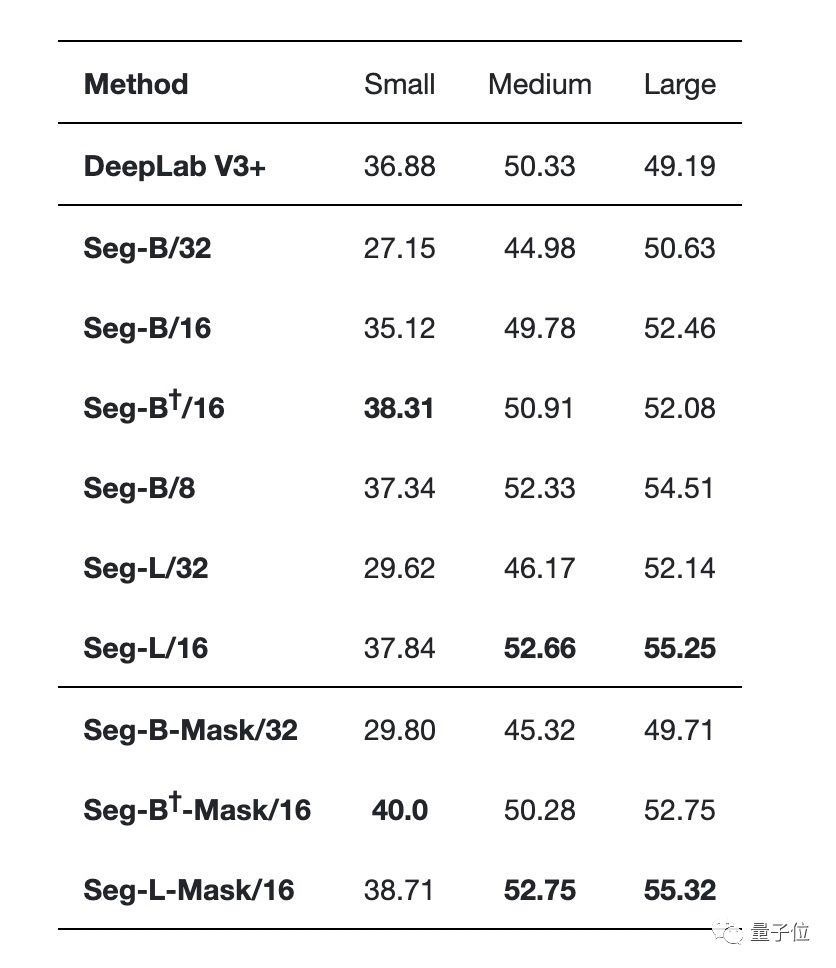
(表中间是带有线性解码器的不同编码器,表底部是带有Mask Transformer作为解码器的不同编码器)
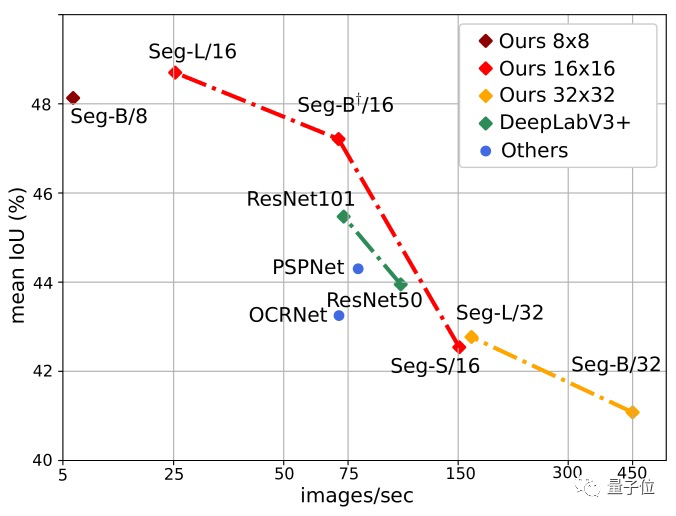
下图也显示了Segmenter的明显优势,其中Seg/16模型(图像块大小为16x16)在性能与准确性方面表现最好。
最后,我们再来看看Segmenter与SOTA的比较:
在最具挑战性的ADE20K数据集上,Segmenter两项指标均高于所有SOTA模型!

(中间太长已省略)

在Cityscapes数据集上与大多数SOTA不相上下,只比性能最好的Panoptic-Deeplab低0.8。
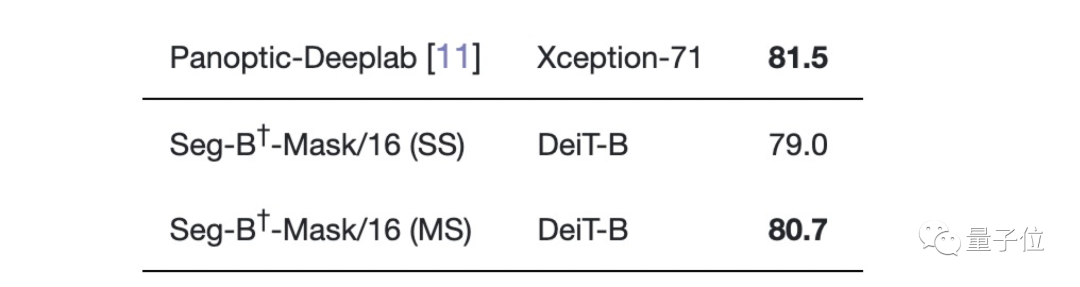
在Pascal Context数据集上的表现也是如此。
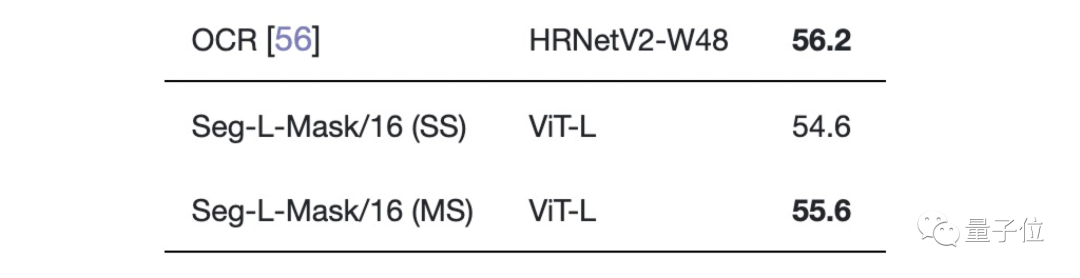
剩余参数比较,大家有兴趣的可按需查看论文细节。
ADE20K
| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) |
|---|---|---|---|---|---|---|---|
| Segmenter Mask | ViT-T_16 | 512x512 | 160000 | 1.21 | 27.98 | 39.99 | 40.83 |
| Segmenter Linear | ViT-S_16 | 512x512 | 160000 | 1.78 | 28.07 | 45.75 | 46.82 |
| Segmenter Mask | ViT-S_16 | 512x512 | 160000 | 2.03 | 24.80 | 46.19 | 47.85 |
| Segmenter Mask | ViT-B_16 | 512x512 | 160000 | 4.20 | 13.20 | 49.60 | 51.07 |
| Segmenter Mask | ViT-L_16 | 640x640 | 160000 | 16.99 | 3.03 | 51.65 | 53.58 |
3. 代码
import math
import torch
import torch.nn as nn
from einops import rearrange
from pathlib import Path
import torch.nn.functional as F
from timm.models.layers import DropPath, trunc_normal_, to_2tuple
from timm.models.vision_transformer import _load_weights
def padding(im, patch_size, fill_value=0):
# make the image sizes divisible by patch_size
H, W = im.size(2), im.size(3)
pad_h, pad_w = 0, 0
if H % patch_size > 0:
pad_h = patch_size - (H % patch_size)
if W % patch_size > 0:
pad_w = patch_size - (W % patch_size)
im_padded = im
if pad_h > 0 or pad_w > 0:
im_padded = F.pad(im, (0, pad_w, 0, pad_h), value=fill_value)
return im_padded
def unpadding(y, target_size):
H, W = target_size
H_pad, W_pad = y.size(2), y.size(3)
# crop predictions on extra pixels coming from padding
extra_h = H_pad - H
extra_w = W_pad - W
if extra_h > 0:
y = y[:, :, :-extra_h]
if extra_w > 0:
y = y[:, :, :, :-extra_w]
return y
def init_weights(m):
"""
初始化参数
Args:
m:
Returns:
"""
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=0.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def resize_pos_embed(posemb, grid_old_shape, grid_new_shape, num_extra_tokens):
# Rescale the grid of position embeddings when loading from state_dict. Adapted from
# https://github.com/google-research/vision_transformer/blob/00883dd691c63a6830751563748663526e811cee/vit_jax/checkpoint.py#L224
posemb_tok, posemb_grid = (
posemb[:, :num_extra_tokens],
posemb[0, num_extra_tokens:],
)
if grid_old_shape is None:
gs_old_h = int(math.sqrt(len(posemb_grid)))
gs_old_w = gs_old_h
else:
gs_old_h, gs_old_w = grid_old_shape
gs_h, gs_w = grid_new_shape
posemb_grid = posemb_grid.reshape(1, gs_old_h, gs_old_w, -1).permute(0, 3, 1, 2)
posemb_grid = F.interpolate(posemb_grid, size=(gs_h, gs_w), mode="bilinear")
posemb_grid = posemb_grid.permute(0, 2, 3, 1).reshape(1, gs_h * gs_w, -1)
posemb = torch.cat([posemb_tok, posemb_grid], dim=1)
return posemb
###############################
###################
# 编码器
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout, out_dim=None):
super().__init__()
self.fc1 = nn.Linear(dim, hidden_dim)
self.act = nn.GELU()
if out_dim is None:
out_dim = dim
self.fc2 = nn.Linear(hidden_dim, out_dim)
self.drop = nn.Dropout(dropout)
@property
def unwrapped(self):
return self
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Attention(nn.Module):
def __init__(self, dim, heads, dropout):
super().__init__()
self.heads = heads
head_dim = dim // heads
self.scale = head_dim ** -0.5
self.attn = None
self.qkv = nn.Linear(dim, dim * 3)
self.attn_drop = nn.Dropout(dropout)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(dropout)
@property
def unwrapped(self):
return self
def forward(self, x, mask=None):
B, N, C = x.shape
qkv = (
self.qkv(x)
.reshape(B, N, 3, self.heads, C // self.heads)
.permute(2, 0, 3, 1, 4)
)
q, k, v = (
qkv[0],
qkv[1],
qkv[2],
)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x, attn
class Block(nn.Module):
def __init__(self, dim, heads, mlp_dim, dropout, drop_path):
"""
transformer block 结构
Args:
dim:
heads:
mlp_dim:
dropout:
drop_path:
"""
super().__init__()
self.norm1 = nn.LayerNorm(dim)
self.norm2 = nn.LayerNorm(dim)
self.attn = Attention(dim, heads, dropout)
self.mlp = FeedForward(dim, mlp_dim, dropout)
self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
def forward(self, x, mask=None, return_attention=False):
y, attn = self.attn(self.norm1(x), mask)
if return_attention:
return attn
x = x + self.drop_path(y)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class PatchEmbedding(nn.Module):
def __init__(self, image_size, patch_size, embed_dim, channels):
super().__init__()
self.image_size = image_size
if image_size[0] % patch_size != 0 or image_size[1] % patch_size != 0:
raise ValueError("image dimensions must be divisible by the patch size")
self.grid_size = image_size[0] // patch_size, image_size[1] // patch_size
self.num_patches = self.grid_size[0] * self.grid_size[1]
self.patch_size = patch_size
self.proj = nn.Conv2d(
channels, embed_dim, kernel_size=patch_size, stride=patch_size
)
def forward(self, im):
B, C, H, W = im.shape
x = self.proj(im).flatten(2).transpose(1, 2)
return x
class VisionTransformer(nn.Module):
def __init__(
self,
image_size,
patch_size,
n_layers,
d_model,
d_ff,
n_heads,
n_cls,
dropout=0.1,
drop_path_rate=0.0,
distilled=False,
channels=3,
):
super().__init__()
self.patch_embed = PatchEmbedding(
image_size,
patch_size,
d_model,
channels,
)
self.patch_size = patch_size
self.n_layers = n_layers
self.d_model = d_model
self.d_ff = d_ff
self.n_heads = n_heads
self.dropout = nn.Dropout(dropout)
self.n_cls = n_cls
# cls and pos tokens
self.cls_token = nn.Parameter(torch.zeros(1, 1, d_model))
self.distilled = distilled
if self.distilled:
self.dist_token = nn.Parameter(torch.zeros(1, 1, d_model))
self.pos_embed = nn.Parameter(
torch.randn(1, self.patch_embed.num_patches + 2, d_model)
)
self.head_dist = nn.Linear(d_model, n_cls)
else:
self.pos_embed = nn.Parameter(
torch.randn(1, self.patch_embed.num_patches + 1, d_model)
)
# transformer blocks
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, n_layers)]
self.blocks = nn.ModuleList(
[Block(d_model, n_heads, d_ff, dropout, dpr[i]) for i in range(n_layers)]
)
# output head
self.norm = nn.LayerNorm(d_model)
self.head = nn.Linear(d_model, n_cls)
trunc_normal_(self.pos_embed, std=0.02)
trunc_normal_(self.cls_token, std=0.02)
if self.distilled:
trunc_normal_(self.dist_token, std=0.02)
self.pre_logits = nn.Identity()
self.apply(init_weights)
@torch.jit.ignore
def no_weight_decay(self):
return {
"pos_embed", "cls_token", "dist_token"}
@torch.jit.ignore()
def load_pretrained(self, checkpoint_path, prefix=""):
_load_weights(self, checkpoint_path, prefix)
def forward(self, im, return_features=False):
B, _, H, W = im.shape
PS = self.patch_size
x = self.patch_embed(im)
cls_tokens = self.cls_token.expand(B, -1, -1)
if self.distilled:
dist_tokens = self.dist_token.expand(B, -1, -1)
x = torch.cat((cls_tokens, dist_tokens, x), dim=1)
else:
x = torch.cat((cls_tokens, x), dim=1)
pos_embed = self.pos_embed
num_extra_tokens = 1 + self.distilled
if x.shape[1] != pos_embed.shape[1]:
pos_embed = resize_pos_embed(
pos_embed,
self.patch_embed.grid_size,
(H // PS, W // PS),
num_extra_tokens,
)
x = x + pos_embed
x = self.dropout(x)
for blk in self.blocks:
x = blk(x)
x = self.norm(x)
if return_features:
return x
if self.distilled:
x, x_dist = x[:, 0], x[:, 1]
x = self.head(x)
x_dist = self.head_dist(x_dist)
x = (x + x_dist) / 2
else:
x = x[:, 0]
x = self.head(x)
return x
def get_attention_map(self, im, layer_id):
if layer_id >= self.n_layers or layer_id < 0:
raise ValueError(
f"Provided layer_id: {
layer_id} is not valid. 0 <= {
layer_id} < {
self.n_layers}."
)
B, _, H, W = im.shape
PS = self.patch_size
x = self.patch_embed(im)
cls_tokens = self.cls_token.expand(B, -1, -1)
if self.distilled:
dist_tokens = self.dist_token.expand(B, -1, -1)
x = torch.cat((cls_tokens, dist_tokens, x), dim=1)
else:
x = torch.cat((cls_tokens, x), dim=1)
pos_embed = self.pos_embed
num_extra_tokens = 1 + self.distilled
if x.shape[1] != pos_embed.shape[1]:
pos_embed = resize_pos_embed(
pos_embed,
self.patch_embed.grid_size,
(H // PS, W // PS),
num_extra_tokens,
)
x = x + pos_embed
for i, blk in enumerate(self.blocks):
if i < layer_id:
x = blk(x)
else:
return blk(x, return_attention=True)
#######################################################################
# 解码器
class DecoderLinear(nn.Module):
def __init__(self, n_cls, patch_size, d_encoder):
super().__init__()
self.d_encoder = d_encoder
self.patch_size = patch_size
self.n_cls = n_cls
self.head = nn.Linear(self.d_encoder, n_cls)
self.apply(init_weights)
@torch.jit.ignore
def no_weight_decay(self):
return set()
def forward(self, x, im_size):
H, W = im_size
GS = H // self.patch_size
x = self.head(x)
x = rearrange(x, "b (h w) c -> b c h w", h=GS)
return x
class MaskTransformer(nn.Module):
"""
解码器部分
"""
def __init__(
self,
n_cls,
patch_size,
d_encoder,
n_layers,
n_heads,
d_model,
d_ff,
drop_path_rate,
dropout,
):
super().__init__()
self.d_encoder = d_encoder
self.patch_size = patch_size
self.n_layers = n_layers
self.n_cls = n_cls
self.d_model = d_model
self.d_ff = d_ff
self.scale = d_model ** -0.5
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, n_layers)]
self.blocks = nn.ModuleList(
[Block(d_model, n_heads, d_ff, dropout, dpr[i]) for i in range(n_layers)]
)
self.cls_emb = nn.Parameter(torch.randn(1, n_cls, d_model))
self.proj_dec = nn.Linear(d_encoder, d_model)
self.proj_patch = nn.Parameter(self.scale * torch.randn(d_model, d_model))
self.proj_classes = nn.Parameter(self.scale * torch.randn(d_model, d_model))
self.decoder_norm = nn.LayerNorm(d_model)
self.mask_norm = nn.LayerNorm(n_cls)
self.apply(init_weights)
trunc_normal_(self.cls_emb, std=0.02)
@torch.jit.ignore
def no_weight_decay(self):
return {
"cls_emb"}
def forward(self, x, im_size):
H, W = im_size
GS = H // self.patch_size
x = self.proj_dec(x)
cls_emb = self.cls_emb.expand(x.size(0), -1, -1)
x = torch.cat((x, cls_emb), 1)
for blk in self.blocks:
x = blk(x)
x = self.decoder_norm(x)
patches, cls_seg_feat = x[:, : -self.n_cls], x[:, -self.n_cls:]
patches = patches @ self.proj_patch
cls_seg_feat = cls_seg_feat @ self.proj_classes
patches = patches / patches.norm(dim=-1, keepdim=True)
cls_seg_feat = cls_seg_feat / cls_seg_feat.norm(dim=-1, keepdim=True)
masks = patches @ cls_seg_feat.transpose(1, 2)
masks = self.mask_norm(masks)
masks = rearrange(masks, "b (h w) n -> b n h w", h=int(GS))
return masks
def get_attention_map(self, x, layer_id):
if layer_id >= self.n_layers or layer_id < 0:
raise ValueError(
f"Provided layer_id: {
layer_id} is not valid. 0 <= {
layer_id} < {
self.n_layers}."
)
x = self.proj_dec(x)
cls_emb = self.cls_emb.expand(x.size(0), -1, -1)
x = torch.cat((x, cls_emb), 1)
for i, blk in enumerate(self.blocks):
if i < layer_id:
x = blk(x)
else:
return blk(x, return_attention=True)
class Segmenter(nn.Module):
"""
segmenter 模型代码
"""
def __init__(
self,
encoder,
decoder,
n_cls,
):
super().__init__()
self.n_cls = n_cls
self.patch_size = encoder.patch_size
self.encoder = encoder
self.decoder = decoder
@torch.jit.ignore
def no_weight_decay(self):
def append_prefix_no_weight_decay(prefix, module):
return set(map(lambda x: prefix + x, module.no_weight_decay()))
nwd_params = append_prefix_no_weight_decay("encoder.", self.encoder).union(
append_prefix_no_weight_decay("decoder.", self.decoder)
)
return nwd_params
def forward(self, im):
H_ori, W_ori = im.size(2), im.size(3)
im = padding(im, self.patch_size)
H, W = im.size(2), im.size(3)
x = self.encoder(im, return_features=True)
# remove CLS/DIST tokens for decoding
num_extra_tokens = 1 + self.encoder.distilled
x = x[:, num_extra_tokens:]
masks = self.decoder(x, (H, W))
masks = F.interpolate(masks, size=(H, W), mode="bilinear")
masks = unpadding(masks, (H_ori, W_ori))
return masks
def get_attention_map_enc(self, im, layer_id):
return self.encoder.get_attention_map(im, layer_id)
def get_attention_map_dec(self, im, layer_id):
x = self.encoder(im, return_features=True)
# remove CLS/DIST tokens for decoding
num_extra_tokens = 1 + self.encoder.distilled
x = x[:, num_extra_tokens:]
return self.decoder.get_attention_map(x, layer_id)
cfg = {
"vit_base_patch8_384": {
"image_size": 384,
"patch_size": 8,
"d_model": 768,
"n_heads": 12,
"n_layers": 12,
"normalization": "vit",
"distilled": False
},
"vit_tiny_patch16_384": {
"image_size": 384,
"patch_size": 16,
"d_model": 192,
"n_heads": 3,
"n_layers": 12,
"normalization": "vit",
"distilled": False
},
"vit_base_patch16_384": {
"image_size": 384,
"patch_size": 16,
"d_model": 768,
"n_heads": 12,
"n_layers": 12,
"normalization": "vit",
"distilled": False
},
"vit_large_patch16_384": {
"image_size": 384,
"patch_size": 16,
"d_model": 1024,
"n_heads": 16,
"n_layers": 24,
"normalization": "vit",
"distilled": False
},
"vit_small_patch32_384": {
"image_size": 384,
"patch_size": 32,
"d_model": 384,
"n_heads": 6,
"n_layers": 12,
"normalization": "vit",
"distilled": False
},
"vit_base_patch32_384": {
"image_size": 384,
"patch_size": 32,
"d_model": 768,
"n_heads": 12,
"n_layers": 12,
"normalization": "vit",
"distilled": False
},
"vit_large_patch32_384": {
"image_size": 384,
"patch_size": 32,
"d_model": 1024,
"n_heads": 16,
"n_layers": 24,
"normalization": "vit",
"distilled": False
}
}
def create_model(num_classes=10, image_size=224, backbone="vit_base_patch8_384"):
model_cfg = cfg[backbone]
image_size = image_size
patch_size = model_cfg["patch_size"]
n_layers = model_cfg["n_layers"]
d_model = model_cfg["d_model"]
n_heads = model_cfg["n_heads"]
mlp_expansion_ratio = 4
d_ff = mlp_expansion_ratio * model_cfg["d_model"]
if type(image_size) is not tuple:
image_size = to_2tuple(image_size)
encoder = VisionTransformer(
image_size=image_size,
patch_size=patch_size,
n_layers=n_layers,
d_model=d_model,
n_heads=n_heads,
d_ff=d_ff,
n_cls=num_classes,
)
dim = d_model
n_heads = dim // 64
decoder = MaskTransformer(
n_cls=num_classes,
patch_size=patch_size,
d_encoder=d_model,
n_layers=2,
n_heads=n_heads,
d_model=d_model,
d_ff=4 * dim,
drop_path_rate=0.0,
dropout=0.1,
)
model = Segmenter(encoder, decoder, n_cls=num_classes)
return model
def vit_base_patch8_384(pretrained=False, **kwargs):
return create_model(backbone="vit_base_patch8_384", **kwargs)
def vit_tiny_patch16_384(pretrained=False, **kwargs):
return create_model(backbone="vit_tiny_patch16_384", **kwargs)
def vit_base_patch16_384(pretrained=False, **kwargs):
return create_model(backbone="vit_base_patch16_384", **kwargs)
def vit_large_patch16_384(pretrained=False, **kwargs):
return create_model(backbone="vit_large_patch16_384", **kwargs)
def vit_small_patch32_384(pretrained=False, **kwargs):
return create_model(backbone="vit_small_patch32_384", **kwargs)
def vit_base_patch32_384(pretrained=False, **kwargs):
return create_model(backbone="vit_base_patch32_384", **kwargs)
def vit_large_patch32_384(pretrained=False, **kwargs):
return create_model(backbone="vit_large_patch32_384", **kwargs)
if __name__ == '__main__':
x = torch.randn(2, 3, 224,224)
model = vit_small_patch32_384(num_classes=19)
y = model(x)
print(y.shape)
参考资料